Python中怎么爬取微信公眾號文章
今天就跟大家聊聊有關Python中怎么爬取微信公眾號文章,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內(nèi)容,希望大家根據(jù)這篇文章可以有所收獲。
洛浦網(wǎng)站制作公司哪家好,找創(chuàng)新互聯(lián)建站!從網(wǎng)頁設計、網(wǎng)站建設、微信開發(fā)、APP開發(fā)、響應式網(wǎng)站等網(wǎng)站項目制作,到程序開發(fā),運營維護。創(chuàng)新互聯(lián)建站自2013年創(chuàng)立以來到現(xiàn)在10年的時間,我們擁有了豐富的建站經(jīng)驗和運維經(jīng)驗,來保證我們的工作的順利進行。專注于網(wǎng)站建設就選創(chuàng)新互聯(lián)建站。
Selenium介紹
Selenium是一個用于web應用程序自動化測試的工具,直接運行在瀏覽器當中,可以通過代碼控制與頁面上元素進行交互,并獲取對應的信息。Selenium很大的一個優(yōu)點是:不需要復雜地構造請求,訪問參數(shù)跟使用瀏覽器的正常用戶一模一樣,訪問行為也相對更像正常用戶,不容易被反爬蟲策略命中,所見即所得。而且在抓取的過程中,必要時還可人工干預(比如登錄、輸入驗證碼等)。
Selenium常常是面對一個嚴格反爬網(wǎng)站無從入手時的保留武器。當然也有缺點:操作均需要等待頁面加載完畢后才可以繼續(xù)進行,所以速度要慢,效率不高(某些情況下使用headless和無圖模式會提高一點效率)。
需求分析和代碼實現(xiàn)
需求很明確:獲取一個公眾號全部推文的標題、日期、鏈接。微信自身的推文功能只能通過其App查看,對App的抓取比較復雜。有一個很方便的替代途徑就是通過搜狗微信檢索。不過如果直接使用Requests等庫直接請求,會涉及的反爬措施有cookie設置,js加密等等,所以今天就利用Selenium大法!
首先導入所需的庫和實例化瀏覽器對象:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
# 導入第2-4行是為了馬上會提到的 顯式等待
import time
import datetime
driver = webdriver.Chrome()
driver.get('https://weixin.sogou.com/')上述的代碼就可以實現(xiàn)打開搜狗微信搜索的操作,接下來需要往搜索框里輸入文字,并且點擊“搜文章”(不直接點搜公眾號是因為已經(jīng)取消通過公眾號直接獲取相應文章的功能)
wait = WebDriverWait(driver, 10)
input = wait.until(EC.presence_of_element_located((By.NAME, 'query')))
input.send_keys('早起Python')
driver.find_element_by_xpath("//input[@class='swz']").click()邏輯是設定最長等待時間,在10s內(nèi)發(fā)現(xiàn)了輸入框已經(jīng)加載出來后就輸入公眾號名稱,這里我們以“早起Python”為例,并且根據(jù)“搜文章”按鈕的xpath獲取該位置并點擊,這里就用到了顯式等待。Selenium請求網(wǎng)頁等待響應受到網(wǎng)速牽制,如果元素未加載全而代碼執(zhí)行過快就會意外報錯而終止,解決方式是等待。
隱式等待是在嘗試發(fā)現(xiàn)某個元素的時候,如果沒能立刻發(fā)現(xiàn),就等待固定長度的時間driver.implicitly_wait(10),顯示等待明確了等待條件,只有該條件觸發(fā),才執(zhí)行后續(xù)代碼,如這里我用到的代碼,當然也可以用time模塊之間設定睡眠時間,睡完了再運行后續(xù)代碼。
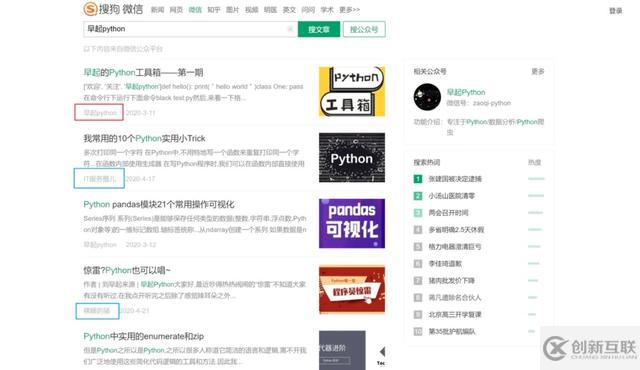
另外只能獲取前10頁100條的結果,查看后續(xù)頁面需要微信掃碼登錄:
因此從這里開始,代碼的執(zhí)行邏輯為:
第10頁遍歷完成后自動點擊登錄,此時需要人工介入,掃碼完成登錄
代碼檢測登錄是否完成(可以簡化為識別“下一頁”按鈕是否出現(xiàn)),如果登錄完成則繼續(xù)從11頁遍歷到最后一頁(沒有“下一頁”按鈕)
由于涉及兩次遍歷則可以將解析信息包裝成函數(shù):
num = 0
def get_news():
global num # 放全局變量是為了給符合條件的文章記序
time.sleep(1)
news_lst = driver.find_elements_by_xpath("//li[contains(@id,'sogou_vr_11002601_box')]")
for news in news_lst:
# 獲取公眾號來源
source = news.find_elements_by_xpath('div[2]/div/a')[0].text
if '早起' not in source:
continue
num += 1
# 獲取文章標題
title = news.find_elements_by_xpath('div[2]/h4/a')[0].text
# 獲取文章發(fā)表日期
date = news.find_elements_by_xpath('div[2]/div/span')[0].text
# 文章發(fā)表的日期如果較近可能會顯示“1天前” “12小時前” “30分鐘前”
# 這里可以用`datetime`模塊根據(jù)時間差求出具體時間
# 然后解析為`YYYY-MM-DD`格式
if '前' in date:
today = datetime.datetime.today()
if '天' in date:
delta = datetime.timedelta(days=int(date[0]))
elif '小時' in date:
delta = datetime.timedelta(hours=int(date.replace('小時前', ' ')))
else:
delta = datetime.timedelta(minutes=int(date.replace('分鐘前', ' ')))
date = str((today - delta).strftime('%Y-%m-%d'))
date = datetime.datetime.strptime(date, '%Y-%m-%d').strftime('%Y-%m-%d')
# 獲取url
url = news.find_elements_by_xpath('div[2]/h4/a')[0].get_attribute('href')
print(num, title, date)
print(url)
print('-' * 10)
for i in range(10):
get_news()
if i == 9:
# 如果遍歷到第十頁則跳出循環(huán)不需要點擊“下一頁”
break
driver.find_element_by_id("sogou_next").click()接下來就是點擊“登錄”,然后人工完成掃碼,可以利用while True檢測登錄是否成功,是否出現(xiàn)了下一頁按鈕,如果出現(xiàn)則跳出循環(huán),點擊“下一頁”按鈕并繼續(xù)后面的代碼,否則睡3秒后重復檢測:
driver.find_element_by_name('top_login').click()
while True:
try:
next_page = driver.find_element_by_id("sogou_next")
break
except:
time.sleep(3)
next_page.click()效果如圖:
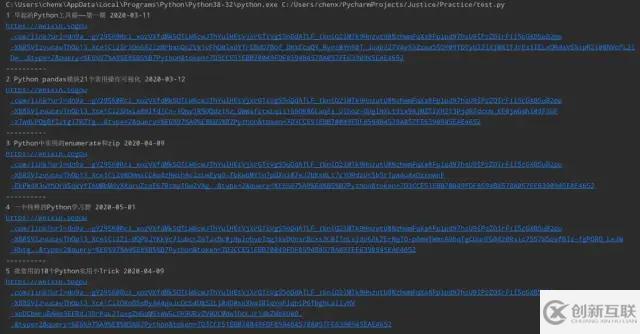
然后就是重新遍歷文章了,由于不知道最后一頁是第幾頁可以使用while循環(huán)反復調(diào)用解析頁面的函數(shù)半點擊“下一頁”,如果不存在下一頁則結束循環(huán):
while True:
get_news()
try:
driver.find_element_by_id("sogou_next").click()
except:
break
# 最后退出瀏覽器即可
driver.quit()看完上述內(nèi)容,你們對Python中怎么爬取微信公眾號文章有進一步的了解嗎?如果還想了解更多知識或者相關內(nèi)容,請關注創(chuàng)新互聯(lián)行業(yè)資訊頻道,感謝大家的支持。
網(wǎng)頁名稱:Python中怎么爬取微信公眾號文章
文章地址:http://www.chinadenli.net/article24/jcocje.html
成都網(wǎng)站建設公司_創(chuàng)新互聯(lián),為您提供營銷型網(wǎng)站建設、定制開發(fā)、Google、ChatGPT、網(wǎng)站策劃、靜態(tài)網(wǎng)站
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉載內(nèi)容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉載,或轉載時需注明來源: 創(chuàng)新互聯(lián)

- 網(wǎng)站導航設計的思索 2020-04-14
- 網(wǎng)站建設中的網(wǎng)站導航的5點要素 2015-04-17
- 菏澤網(wǎng)站建設-網(wǎng)站導航功能都有哪些呢? 2021-10-06
- 網(wǎng)站導航SEO優(yōu)化的5大要素 2015-12-19
- 北京網(wǎng)站優(yōu)化,網(wǎng)站導航詳解 2021-04-17
- 如何做好網(wǎng)站導航優(yōu)化工作? 2015-08-01
- 網(wǎng)站導航及首頁布局必知的設計原則 2016-10-10
- 網(wǎng)站導航如何設置才符合SEO的標準? 2015-12-20
- 為你總結哪些網(wǎng)站導航設計最佳實踐 2022-06-14
- 網(wǎng)站導航如何設計-佛山網(wǎng)站設計 2022-11-26
- 怎樣設計網(wǎng)站導航會更加的專業(yè)? 2014-03-04
- 網(wǎng)站導航如何設計 2022-11-01