lucene的全文檢索是什么
本篇內(nèi)容介紹了“l(fā)ucene的全文檢索是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠?qū)W有所成!
樺南網(wǎng)站制作公司哪家好,找創(chuàng)新互聯(lián)公司!從網(wǎng)頁設計、網(wǎng)站建設、微信開發(fā)、APP開發(fā)、成都響應式網(wǎng)站建設等網(wǎng)站項目制作,到程序開發(fā),運營維護。創(chuàng)新互聯(lián)公司2013年開創(chuàng)至今到現(xiàn)在10年的時間,我們擁有了豐富的建站經(jīng)驗和運維經(jīng)驗,來保證我們的工作的順利進行。專注于網(wǎng)站建設就選創(chuàng)新互聯(lián)公司。
定義:Lucene 是一個高效的,基于 Java 的全文檢索庫。所以在了解 Lucene 之前要費一番工夫了解一下全文檢索。
那么什么叫做全文檢索呢?這要從我們生活中的數(shù)據(jù)說起。我們生活中的數(shù)據(jù)總體分為兩種:結(jié)構(gòu)化數(shù)據(jù) 和 非結(jié)構(gòu)化數(shù)據(jù)。
結(jié)構(gòu)化數(shù)據(jù): 指具有固定格式或有限長度的數(shù)據(jù),如數(shù)據(jù)庫,元數(shù)據(jù)等。
非結(jié)構(gòu)化數(shù)據(jù):指不定長或無固定格式的數(shù)據(jù),如郵件, word 文檔等。
當然有的地方還會提到第三種,半結(jié)構(gòu)化數(shù)據(jù),如 XML,HTML 等,當根據(jù)需要可按結(jié)構(gòu)化數(shù)據(jù)來處理,也可抽取出純文本按非結(jié)構(gòu)化數(shù)據(jù)來處理。非結(jié)構(gòu)化數(shù)據(jù)又一種叫法叫全文數(shù)據(jù)。按照數(shù)據(jù)的分類,搜索也分為兩種:
對結(jié)構(gòu)化數(shù)據(jù)的搜索:如對數(shù)據(jù)庫的搜索,用 SQL 語句。再如對元數(shù)據(jù)的搜索,如利用
windows 搜索對文件名,類型,修改時間進行搜索等。對非結(jié)構(gòu)化數(shù)據(jù)的搜索:如利用 windows 的搜索也可以搜索文件內(nèi)容,Linux 下的 grep
命令,再如用 Google 和百度可以搜索大量內(nèi)容數(shù)據(jù)。
是對非結(jié)構(gòu)化數(shù)據(jù)也即對全文數(shù)據(jù)的搜索主要有兩種方法:
一種是 (Serial Scanning) 順序掃描法:所謂順序掃描,比如要找內(nèi)容包含某一個字符串的文件,就是一個文檔一個文檔的看,對于每一個文檔,從頭看到尾,如果此文檔包含此字符串,則此文檔為我們要找的文件,接著看下一個文件,直到掃描完所有的文件。如利用 windows的搜索也可以搜索文件內(nèi)容,只是相當?shù)穆H绻阌幸粋€ 80G 硬盤,如果想在上面找到一個內(nèi)容包含某字符串的文件,不花他幾個小時,怕是做不到。Linux 下的 grep 命令也是這
一種方式。大家可能覺得這種方法比較原始,但對于小數(shù)據(jù)量的文件,這種方法還是最直接,最方便的。但是對于大量的文件,這種方法就很慢了。有人可能會說,對非結(jié)構(gòu)化數(shù)據(jù)順序掃描很慢,對結(jié)構(gòu)化數(shù)據(jù)的搜索卻相對較快(由于結(jié)構(gòu)化數(shù)據(jù)有一定的結(jié)構(gòu)可以采取一定的搜索算法加快速度),那么把我們的非結(jié)構(gòu)化數(shù)據(jù)想辦法弄得有一定結(jié)構(gòu)不就行了嗎?這種想法很天然,卻構(gòu)成了全文檢索的基本思路,也即將非結(jié)構(gòu)化數(shù)據(jù)中的一部分信息提取出來,重新組織,使其變得一定結(jié)構(gòu),然后對此有一定結(jié)構(gòu)的數(shù)據(jù)進行搜索,從而達到搜索相對較快的目的。這部分從非結(jié)構(gòu)化數(shù)據(jù)中提取出的然后重新組織的信息,我們稱之索引索引索引。這種說法比較抽象,舉幾個例子就很容易明白,比如字典,字典的拼音表和部首檢字表就相當于字典的索引,對每一個字的解釋是非結(jié)構(gòu)化的,如果字典沒有音節(jié)表和部首檢字表,在茫茫辭海中找一個字只能順序掃描。然而字的某些信息可以提取出來進行結(jié)構(gòu)化處理,比如讀音,就比較結(jié)構(gòu)化,分聲母和韻母,分別只有幾種可以一一列舉,于是將讀音拿出來按一定的順序排列,每一項讀音都指向此字的詳細解釋的頁數(shù)。我們搜索時按結(jié)構(gòu)化的拼音搜到讀音,然后按其指向的頁數(shù),便可找到我們的非結(jié)構(gòu)化數(shù)據(jù)——也即對字的解釋。這種先建立索引,再對索引進行搜索的過程就叫全文檢索(Full-text Search)。下面這幅圖來自《Lucene in action》,但卻不僅僅描述了 Lucene 的檢索過程,而是描述了全文檢索的一般過程。
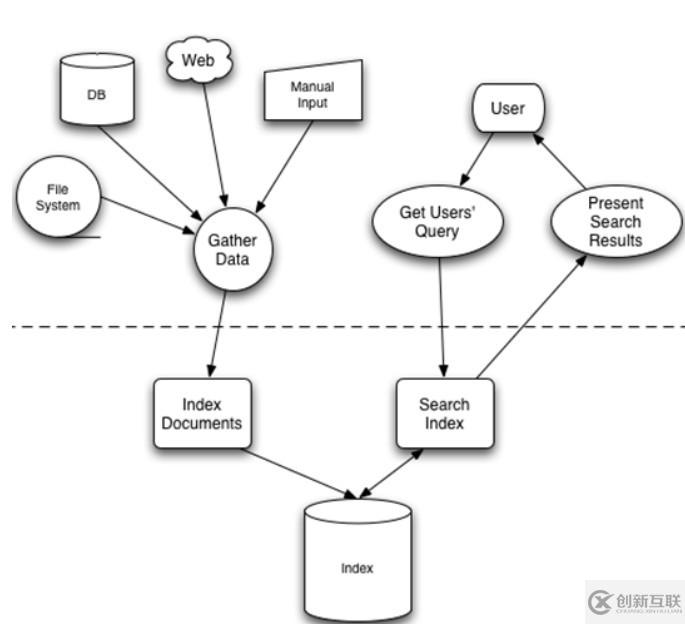
全文檢索大體分兩個過程,索引創(chuàng)建(Indexing)和搜索索引(Search)。
索引創(chuàng)建:將現(xiàn)實世界中所有的結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)提取信息,創(chuàng)建索引的過程。
搜索索引:就是得到用戶的查詢請求,搜索創(chuàng)建的索引,然后返回結(jié)果的過程。
于是全文檢索就存在三個重要問題:
1. 索引里面究竟存些什么?(Index)
2. 如何創(chuàng)建索引?(Indexing)
3. 如何對索引進行搜索?(Search)
“l(fā)ucene的全文檢索是什么”的內(nèi)容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業(yè)相關的知識可以關注創(chuàng)新互聯(lián)網(wǎng)站,小編將為大家輸出更多高質(zhì)量的實用文章!
分享名稱:lucene的全文檢索是什么
分享URL:http://www.chinadenli.net/article6/gpohog.html
成都網(wǎng)站建設公司_創(chuàng)新互聯(lián),為您提供自適應網(wǎng)站、品牌網(wǎng)站制作、手機網(wǎng)站建設、網(wǎng)站維護、網(wǎng)站收錄、網(wǎng)站設計
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)

- 集團公司網(wǎng)站建設方案 網(wǎng)站改版有哪些 2021-05-13
- 企業(yè)網(wǎng)站改版的目的是什么?有哪些流程和事項需要注意? 2022-06-07
- 界面設計對網(wǎng)站改版的重要性 2021-09-26
- 網(wǎng)站改版網(wǎng)站建設還有必要嗎? 2022-12-14
- 為什么企業(yè)要把傳統(tǒng)網(wǎng)站改版成廣州高端網(wǎng)站制作? 2022-12-09
- 網(wǎng)站改版升級運營的建議 2022-12-20
- 金華網(wǎng)站改版設計哪家公司好? 2020-11-25
- 網(wǎng)站改版專題:網(wǎng)站改版到底改什么? 2023-02-11
- 網(wǎng)站升級和網(wǎng)站改版是同一種事情嗎? 2020-12-20
- 網(wǎng)站改版需要注意的事項 2022-12-08
- 哪些情況要進行網(wǎng)站改版? 2021-11-06
- 網(wǎng)站改版怎樣能不掉權(quán)重 2022-06-18