python如何實(shí)現(xiàn)感知器算法-創(chuàng)新互聯(lián)
這篇文章主要介紹了python如何實(shí)現(xiàn)感知器算法,具有一定借鑒價(jià)值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。

具體內(nèi)容如下
先創(chuàng)建感知器類:用于二分類
# -*- coding: utf-8 -*-
import numpy as np
class Perceptron(object):
"""
感知器:用于二分類
參照改寫 https://blog.csdn.net/simple_the_best/article/details/54619495
屬性:
w0:偏差
w:權(quán)向量
learning_rate:學(xué)習(xí)率
threshold:準(zhǔn)則閾值
"""
def __init__(self,learning_rate=0.01,threshold=0.001):
self.learning_rate=learning_rate
self.threshold=threshold
def train(self,x,y):
"""訓(xùn)練
參數(shù):
x:樣本,維度為n*m(樣本有m個(gè)特征,x輸入就是m維),樣本數(shù)量為n
y:類標(biāo),維度為n*1,取值1和-1(正樣本和負(fù)樣本)
返回:
self:object
"""
self.w0=0.0
self.w=np.full(x.shape[1],0.0)
k=0
while(True):
k+=1
dJw0=0.0
dJw=np.zeros(x.shape[1])
err=0.0
for i in range(0,x.shape[0]):
if not (y[i]==1 or y[i]==-1):
print("類標(biāo)只能為1或-1!請(qǐng)核對(duì)!")
break
update=self.learning_rate*0.5*(y[i]-self.predict(x[i]))
dJw0+=update
dJw+=update*x[i]
err+=np.abs(0.5*(y[i]-self.predict(x[i])))
self.w0 += dJw0
self.w += dJw
if np.abs(np.sum(self.learning_rate*dJw))<self.threshold or k>500:
print("迭代次數(shù):",k," 錯(cuò)分樣本數(shù):",err)
break
return self
def predict(self,x):
"""預(yù)測(cè)類別
參數(shù):
x:樣本,1*m維,1個(gè)樣本,m維特征
返回:
yhat:預(yù)測(cè)的類標(biāo)號(hào),1或者-1,1代表正樣本,-1代表負(fù)樣本
"""
if np.matmul(self.w,x.T)+self.w0>0:
yhat=1
else:
yhat=-1
return yhat
def predict_value(self,x):
"""預(yù)測(cè)值
參數(shù):
x:樣本,1*m維,1個(gè)樣本,m維特征
返回:
y:預(yù)測(cè)值
"""
y=np.matmul(self.w,x.T)+self.w0
return y然后為Iris數(shù)據(jù)集創(chuàng)建一個(gè)Iris類,用于產(chǎn)生5折驗(yàn)證所需要的數(shù)據(jù),并且能產(chǎn)生不同樣本數(shù)量的數(shù)據(jù)集。
# -*- coding: utf-8 -*-
"""
Author:CommissarMa
2018年5月23日 16點(diǎn)52分
"""
import numpy as np
import scipy.io as sio
class Iris(object):
"""Iris數(shù)據(jù)集
參數(shù):
data:根據(jù)size裁剪出來(lái)的iris數(shù)據(jù)集
size:每種類型的樣本數(shù)量
way:one against the rest || one against one
注意:
此處規(guī)定5折交叉驗(yàn)證(5-cv),所以每種類型樣本的數(shù)量要是5的倍數(shù)
多分類方式:one against the rest
"""
def __init__(self,size=50,way="one against the rest"):
"""
size:每種類型的樣本數(shù)量
"""
data=sio.loadmat("C:\\Users\\CommissarMa\\Desktop\\模式識(shí)別\\課件ppt\\PR實(shí)驗(yàn)內(nèi)容\\iris_data.mat")
iris_data=data['iris_data']#iris_data:原數(shù)據(jù)集,shape:150*4,1-50個(gè)樣本為第一類,51-100個(gè)樣本為第二類,101-150個(gè)樣本為第三類
self.size=size
self.way=way
self.data=np.zeros((size*3,4))
for r in range(0,size*3):
self.data[r]=iris_data[int(r/size)*50+r%size]
def generate_train_data(self,index_fold,index_class,neg_class=None):
"""
index_fold:5折驗(yàn)證的第幾折,范圍:0,1,2,3,4
index_class:第幾類作為正類,類別號(hào):負(fù)類樣本為-1,正類樣本為1
"""
if self.way=="one against the rest":
fold_size=int(self.size/5)#將每類樣本分成5份
train_data=np.zeros((fold_size*4*3,4))
label_data=np.full((fold_size*4*3),-1)
for r in range(0,fold_size*4*3):
n_class=int(r/(fold_size*4))#第幾類
n_fold=int((r%(fold_size*4))/fold_size)#第幾折
n=(r%(fold_size*4))%fold_size#第幾個(gè)
if n_fold<index_fold:
train_data[r]=self.data[n_class*self.size+n_fold*fold_size+n]
else:
train_data[r]=self.data[n_class*self.size+(n_fold+1)*fold_size+n]
label_data[fold_size*4*index_class:fold_size*4*(index_class+1)]=1
elif self.way=="one against one":
if neg_class==None:
print("one against one模式下需要提供負(fù)類的序號(hào)!")
return
else:
fold_size=int(self.size/5)#將每類樣本分成5份
train_data=np.zeros((fold_size*4*2,4))
label_data=np.full((fold_size*4*2),-1)
for r in range(0,fold_size*4*2):
n_class=int(r/(fold_size*4))#第幾類
n_fold=int((r%(fold_size*4))/fold_size)#第幾折
n=(r%(fold_size*4))%fold_size#第幾個(gè)
if n_class==0:#放正類樣本
if n_fold<index_fold:
train_data[r]=self.data[index_class*self.size+n_fold*fold_size+n]
else:
train_data[r]=self.data[index_class*self.size+(n_fold+1)*fold_size+n]
if n_class==1:#放負(fù)類樣本
if n_fold<index_fold:
train_data[r]=self.data[neg_class*self.size+n_fold*fold_size+n]
else:
train_data[r]=self.data[neg_class*self.size+(n_fold+1)*fold_size+n]
label_data[0:fold_size*4]=1
else:
print("多分類方式錯(cuò)誤!只能為one against one 或 one against the rest!")
return
return train_data,label_data
def generate_test_data(self,index_fold):
"""生成測(cè)試數(shù)據(jù)
index_fold:5折驗(yàn)證的第幾折,范圍:0,1,2,3,4
返回值:
test_data:對(duì)應(yīng)于第index_fold折的測(cè)試數(shù)據(jù)
label_data:類別號(hào)為0,1,2
"""
fold_size=int(self.size/5)#將每類樣本分成5份
test_data=np.zeros((fold_size*3,4))
label_data=np.zeros(fold_size*3)
for r in range(0,fold_size*3):
test_data[r]=self.data[int(int(r/fold_size)*self.size)+int(index_fold*fold_size)+r%fold_size]
label_data[0:fold_size]=0
label_data[fold_size:fold_size*2]=1
label_data[fold_size*2:fold_size*3]=2
return test_data,label_data然后我們進(jìn)行訓(xùn)練測(cè)試,先使用one against the rest策略:
# -*- coding: utf-8 -*-
from perceptron import Perceptron
from iris_data import Iris
import numpy as np
if __name__=="__main__":
iris=Iris(size=50,way="one against the rest")
correct_all=0
for n_fold in range(0,5):
p=[Perceptron(),Perceptron(),Perceptron()]
for c in range(0,3):
x,y=iris.generate_train_data(index_fold=n_fold,index_class=c)
p[c].train(x,y)
#訓(xùn)練完畢,開始測(cè)試
correct=0
x_test,y_test=iris.generate_test_data(index_fold=n_fold)
num=len(x_test)
for i in range(0,num):
maxvalue=max(p[0].predict_value(x_test[i]),p[1].predict_value(x_test[i]),
p[2].predict_value(x_test[i]))
if maxvalue==p[int(y_test[i])].predict_value(x_test[i]):
correct+=1
print("錯(cuò)分?jǐn)?shù)量:",num-correct,"錯(cuò)誤率:",(num-correct)/num)
correct_all+=correct
print("平均錯(cuò)誤率:",(num*5-correct_all)/(num*5))然后使用one against one 策略去訓(xùn)練測(cè)試:
# -*- coding: utf-8 -*-
from perceptron import Perceptron
from iris_data import Iris
import numpy as np
if __name__=="__main__":
iris=Iris(size=10,way="one against one")
correct_all=0
for n_fold in range(0,5):
#訓(xùn)練
p01=Perceptron()#0類和1類比較的判別器
p02=Perceptron()
p12=Perceptron()
x,y=iris.generate_train_data(index_fold=n_fold,index_class=0,neg_class=1)
p01.train(x,y)
x,y=iris.generate_train_data(index_fold=n_fold,index_class=0,neg_class=2)
p02.train(x,y)
x,y=iris.generate_train_data(index_fold=n_fold,index_class=1,neg_class=2)
p12.train(x,y)
#測(cè)試
correct=0
x_test,y_test=iris.generate_test_data(index_fold=n_fold)
num=len(x_test)
for i in range(0,num):
vote0=0
vote1=0
vote2=0
if p01.predict_value(x_test[i])>0:
vote0+=1
else:
vote1+=1
if p02.predict_value(x_test[i])>0:
vote0+=1
else:
vote2+=1
if p12.predict_value(x_test[i])>0:
vote1+=1
else:
vote2+=1
if vote0==max(vote0,vote1,vote2) and int(vote0)==int(y_test[i]):
correct+=1
elif vote1==max(vote0,vote1,vote2) and int(vote1)==int(y_test[i]):
correct+=1
elif vote2==max(vote0,vote1,vote2) and int(vote2)==int(y_test[i]):
correct+=1
print("錯(cuò)分?jǐn)?shù)量:",num-correct,"錯(cuò)誤率:",(num-correct)/num)
correct_all+=correct
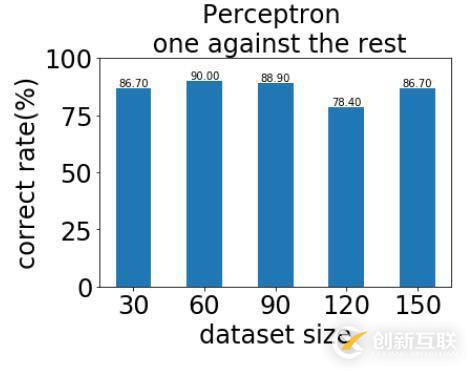
print("平均錯(cuò)誤率:",(num*5-correct_all)/(num*5))實(shí)驗(yàn)結(jié)果如圖所示:
感謝你能夠認(rèn)真閱讀完這篇文章,希望小編分享的“python如何實(shí)現(xiàn)感知器算法”這篇文章對(duì)大家有幫助,同時(shí)也希望大家多多支持創(chuàng)新互聯(lián),關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道,更多相關(guān)知識(shí)等著你來(lái)學(xué)習(xí)!
文章題目:python如何實(shí)現(xiàn)感知器算法-創(chuàng)新互聯(lián)
文章URL:http://www.chinadenli.net/article44/dhopee.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供App開發(fā)、網(wǎng)站設(shè)計(jì)公司、網(wǎng)站制作、外貿(mào)建站、電子商務(wù)、響應(yīng)式網(wǎng)站
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- python中的類-創(chuàng)新互聯(lián)
- angular如何實(shí)現(xiàn)form驗(yàn)證-創(chuàng)新互聯(lián)
- 《c++primer》第三章字符串、vector、數(shù)組-創(chuàng)新互聯(lián)
- 檢測(cè)本地網(wǎng)絡(luò)到ECS實(shí)例之間網(wǎng)絡(luò)狀況的方法-創(chuàng)新互聯(lián)
- css描邊屬性有什么用-創(chuàng)新互聯(lián)
- python的學(xué)習(xí)路線-創(chuàng)新互聯(lián)
- Wrapper類怎么在java中使用-創(chuàng)新互聯(lián)

- 品牌網(wǎng)站建設(shè)為什么只能選擇網(wǎng)站定制 2016-09-03
- 成都網(wǎng)站建設(shè)品牌網(wǎng)站建設(shè)方案要怎么做? 2016-09-27
- 高端品牌網(wǎng)站建設(shè)凸顯格調(diào)的方法 2022-11-29
- 如何做成都企業(yè)品牌網(wǎng)站建設(shè)? 2022-07-14
- 影響品牌網(wǎng)站建設(shè)質(zhì)量的因素有哪些? 2022-03-07
- 北京高端品牌網(wǎng)站建設(shè)公司-專業(yè)高端網(wǎng)站制作 2021-02-11
- 怎樣做才能夠得到更好的進(jìn)行公司品牌網(wǎng)站建設(shè)呢? 2016-10-13
- 集寧品牌網(wǎng)站建設(shè)解決方案 2020-11-24
- 企業(yè)要做品牌網(wǎng)站建設(shè)的四大理由 2017-12-14
- 如何才能樹立起自己的品牌網(wǎng)站建設(shè) 2016-09-01
- 豐臺(tái)網(wǎng)站建設(shè),豐臺(tái)網(wǎng)站制作,豐臺(tái)做網(wǎng)站,豐臺(tái)網(wǎng)站改版 2016-11-04
- 品牌網(wǎng)站建設(shè)過(guò)程怎么有條理的進(jìn)行呢 2021-10-20