三、spark--spark調(diào)度原理分析
[TOC]
成都創(chuàng)新互聯(lián)公司2013年至今,是專業(yè)互聯(lián)網(wǎng)技術(shù)服務公司,擁有項目做網(wǎng)站、網(wǎng)站制作網(wǎng)站策劃,項目實施與項目整合能力。我們以讓每一個夢想脫穎而出為使命,1280元宜豐做網(wǎng)站,已為上家服務,為宜豐各地企業(yè)和個人服務,聯(lián)系電話:18982081108
一、wordcount程序的執(zhí)行過程
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//創(chuàng)建spark配置文件對象.設(shè)置app名稱,master地址,local表示為本地模式。
//如果是提交到集群中,通常不指定。因為可能在多個集群匯上跑,寫死不方便
val conf = new SparkConf().setAppName("wordCount")
//創(chuàng)建spark context對象
val sc = new SparkContext(conf)
sc.textFile(args(0)).flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.saveAsTextFile(args(1))
sc.stop()
}
}核心代碼很簡單,首先看 textFile這個函數(shù)
SparkContext.scala
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
//指定文件路徑、輸入的格式類為textinputformat,輸出的key類型為longwritable,輸出的value類型為text
//map(pair => pair._2.toString)取出前面的value,然后將value轉(zhuǎn)為string類型
//最后將處理后的value返回成一個新的list,也就是RDD[String]
//setName(path) 設(shè)置該file名字為路徑
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
關(guān)鍵性的操作就是:
返回了一個hadoopFile,它有幾個參數(shù):
path:文件路徑
classOf[TextInputFormat]:這個其實就是輸入文件的處理類,也就是我們mr中分析過的TextInputFormat,其實就是直接拿過來的用的,不要懷疑,就是醬紫的
classOf[LongWritable], classOf[Text]:這兩個其實可以猜到了,就是輸入的key和value的類型。
接著執(zhí)行了一個map(pair => pair._2.toString),將KV中的value轉(zhuǎn)為string類型我們接著看看hadoopFile 這個方法
def hadoopFile[K, V](
path: String,
inputFormatClass: Class[_ <: InputFormat[K, V]],
keyClass: Class[K],
valueClass: Class[V],
minPartitions: Int = defaultMinPartitions): RDD[(K, V)] = withScope {
assertNotStopped()
// This is a hack to enforce loading hdfs-site.xml.
// See SPARK-11227 for details.
FileSystem.getLocal(hadoopConfiguration)
// A Hadoop configuration can be about 10 KB, which is pretty big, so broadcast it.
val confBroadcast = broadcast(new SerializableConfiguration(hadoopConfiguration))
val setInputPathsFunc = (jobConf: JobConf) => FileInputFormat.setInputPaths(jobConf, path)
//看到這里,最后返回的是一個 HadoopRDD 對象
//指定sc對象,配置文件、輸入方法類、KV類型、分區(qū)個數(shù)
new HadoopRDD(
this,
confBroadcast,
Some(setInputPathsFunc),
inputFormatClass,
keyClass,
valueClass,
minPartitions).setName(path)
}最后返回HadoopRDD對象。
接著就是flatMap(.split(" ")) .map((,1)),比較簡單
flatMap(_.split(" "))
就是將輸入每一行,按照空格切割,然后切割后的元素稱為一個新的數(shù)組。
然后將每一行生成的數(shù)組合并成一個大數(shù)組。
map((_,1))
將每個元素進行1的計數(shù),組成KV對,K是元素,V是1接著看.reduceByKey(_+_)
這個其實就是將同一key的KV進行聚合分組,然后將同一key的value進行相加,最后就得出某個key對應的value,也就是某個單詞的個數(shù)
看看這個函數(shù)
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope {
reduceByKey(defaultPartitioner(self), func)
}
這個過程中會分區(qū),默認分區(qū)數(shù)是2,使用的是HashPartitioner進行分區(qū),可以指定分區(qū)的最小個數(shù)二、spark的資源調(diào)度
2.1 資源調(diào)度流程
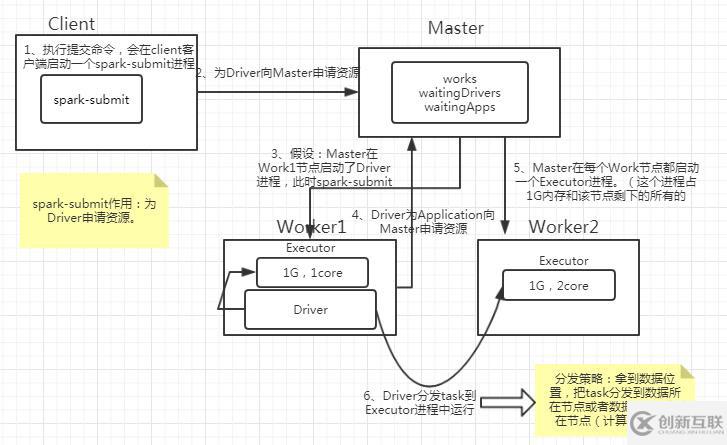
圖2.1 spark資源調(diào)度
1、執(zhí)行提交命令,會在client客戶端啟動一個spark-submit進程(用來為Driver申請資源)。
2、為Driver向Master申請資源,在Master的waitingDrivers 集合中添加這個Driver要申請的信息。Master查看works集合,挑選出合適的Work節(jié)點。
3、在選中的Work節(jié)點中啟動Driver進程(Driver進程已經(jīng)啟動了,spark-submit的使命已經(jīng)完成了,關(guān)閉該進程)。所以其實driver也需要資源,也只是跑在executor上的一個線程而已
4、Driver進程為要運行的Application申請資源(這個資源指的是Executor進程)。此時Master的waitingApps 中要添加這個Application申請的資源信息。這時要根據(jù)申請資源的要求去計算查看需要用到哪些Worker節(jié)點(每一個節(jié)點要用多少資源)。在這些節(jié)點啟動Executor進程。
(注:輪詢啟動Executor。Executor占用這個節(jié)點1G內(nèi)存和這個Worker所能管理的所有的core)
5、此時Driver就可以分發(fā)任務到各個Worker節(jié)點的Executor進程中運行了。
Master中的三個集合
val works = new HashSet[WorkInfo]()
??works 集合采用HashSet數(shù)組存儲work的節(jié)點信息,可以避免存放重復的work節(jié)點。為什么要避免重復?首先我們要知道work節(jié)點有可能因為某些原因掛掉,掛掉之后下一次與master通信時會報告給master,這個節(jié)點掛掉了,然后master會在works對象里把這個節(jié)點去掉,等下次再用到這個節(jié)點是時候,再加進來。這樣來說,理論上是不會有重復的work節(jié)點的。可是有一種特殊情況:work掛掉了,在下一次通信前又自己啟動了,這時works里面就會有重復的work信息。
??val waitingDrivers = new ArrayBuffer[DriverInfo]()
??當客戶端向master為Driver申請資源時,會將要申請的Driver的相關(guān)信息封裝到master節(jié)點的DriverInfo這個泛型里,然后添加到waitingDrivers 里。master會監(jiān)控這個waitingDrivers 對象,當waitingDrivers集合中的元素不為空時,說明有客戶端向master申請資源了。此時應該先查看一下works集合,找到符合要求的worker節(jié)點,啟動Driver。當Driver啟動成功后,會把這個申請信息從waitingDrivers 對象中移除。
?? val waitingApps = new ArrayBuffer[ApplicationInfo]()
??Driver啟動成功后,會為application向master申請資源,這個申請信息封存到master節(jié)點的waitingApps 對象中。同樣的,當waitingApps 集合不為空,說明有Driver向Master為當前的Application申請資源。此時查看workers集合,查找到合適的Worker節(jié)點啟動Executor進程,默認的情況下每一個Worker只是為每一個Application啟動一個Executor,這個Executor會使用1G內(nèi)存和所有的core。啟動Executor后把申請信息從waitingApps 對象中移除。
??注意點:上面說到master會監(jiān)控這三個集合,那么到底是怎么監(jiān)控的呢???
??master并不是分出來線程專門的對這三個集合進行監(jiān)控,相對而言這樣是比較浪費資源的。master實際上是‘監(jiān)控’這三個集合的改變,當這三個集合中的某一個集合發(fā)生變化時(新增或者刪除),那么就會調(diào)用schedule()方法。schedule方法中封裝了上面提到的處理邏輯。2.2 application和executor的關(guān)系
1、默認情況下,每一個Worker只會為每一個Application啟動一個Executor。每個Executor默認使用1G內(nèi)存和這個Worker所能管理的所有的core。
2、如果想要在一個Worker上啟動多個Executor,在提交Application的時候要指定Executor使用的core數(shù)量(避免使用該worker所有的core)。提交命令:spark-submit --executor-cores
3、默認情況下,Executor的啟動方式是輪詢啟動,一定程度上有利于數(shù)據(jù)的本地化。
什么是輪詢啟動???為什么要輪訓啟動呢???
??輪詢啟動:輪詢啟動就是一個個的啟動。例如這里有5個人,每個人要發(fā)一個蘋果+一個香蕉。輪詢啟動的分發(fā)思路就是:五個人先一人分一個蘋果,分發(fā)完蘋果再分發(fā)香蕉。
??為什么要使用輪詢啟動的方式呢???我們做大數(shù)據(jù)計算首先肯定想的是計算找數(shù)據(jù)。在數(shù)據(jù)存放的地方直接計算,而不是把數(shù)據(jù)搬過來再計算。我們有n臺Worker節(jié)點,如果只是在數(shù)據(jù)存放的節(jié)點計算。只用了幾臺Worker去計算,大部分的worker都是閑置的。這種方案肯定不可行。所以我們就使用輪詢方式啟動Executor,先在每一臺節(jié)點都允許一個任務。
??存放數(shù)據(jù)的節(jié)點由于不需要網(wǎng)絡傳輸數(shù)據(jù),所以肯定速度快,執(zhí)行的task數(shù)量就會比較多。這樣不會浪費集群資源,也可以在存放數(shù)據(jù)的節(jié)點進行計算,在一定程度上也有利于數(shù)據(jù)的本地化。
2.3 spark的粗細粒度調(diào)度
粗粒度(富二代):
在任務執(zhí)行之前,會先將資源申請完畢,當所有的task執(zhí)行完畢,才會釋放這部分資源。
優(yōu)點:每一個task執(zhí)行前。不需要自己去申請資源了,節(jié)省啟動時間。
缺點:等到所有的task執(zhí)行完才會釋放資源(也就是整個job執(zhí)行完成),集群的資源就無法充分利用。
這是spark使用的調(diào)度粒度,主要是為了讓stage,job,task的執(zhí)行效率高一點細粒度(窮二代):
Application提交的時候,每一個task自己去申請資源,task申請到資源才會執(zhí)行,執(zhí)行完這個task會立刻釋放資源。
優(yōu)點:每一個task執(zhí)行完畢之后會立刻釋放資源,有利于充分利用資源。
缺點:由于需要每一個task自己去申請資源,導致task啟動時間過長,進而導致stage、job、application啟動時間延長。2.4 spark-submit提交任務對資源的限制
我們提交任務時,可以指定一些資源限制的參數(shù):
--executor-cores : 單個executor使用的core數(shù)量,不指定的話默認使用該worker所有能調(diào)用的core
--executor-memory : 單個executor使用的內(nèi)存大小,如1G。默認是1G
--total-executor-cores : 整個application最多使用的core數(shù)量,防止獨占整個集群資源三、整個spark資源調(diào)度+任務調(diào)度的流程
3.1 總的調(diào)度流程
https://blog.csdn.net/qq_33247435/article/details/83653584#3Spark_51
一個application的調(diào)度到完成,需要經(jīng)過以下階段:
application-->資源調(diào)度-->任務調(diào)度(task)-->并行計算-->完成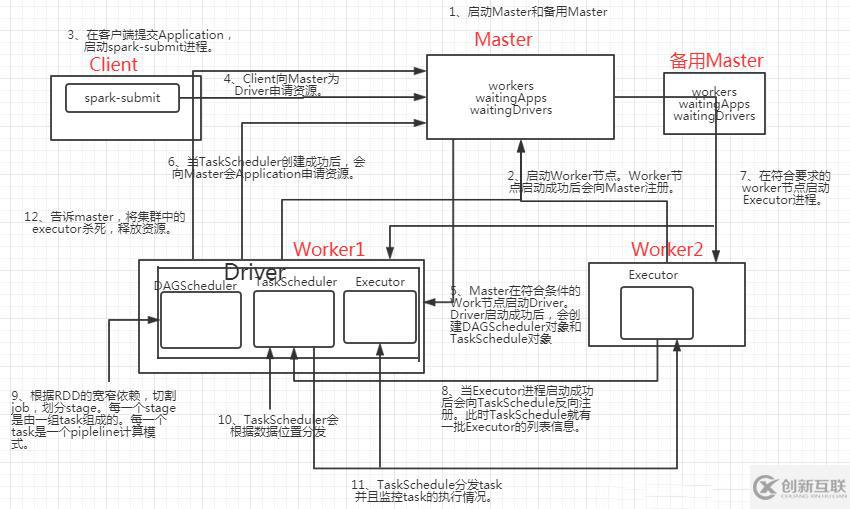
圖3.1 spark調(diào)度流程
可以看到,driver啟動后,會有下面兩個對象:
DAGScheduler:
據(jù)RDD的寬窄依賴關(guān)系將DAG有向無環(huán)圖切割成一個個的stage,將stage封裝給另一個對象taskSet,taskSet=stage,然后將一個個的taskSet給taskScheduler。
taskScheduler:
taskSeheduler拿倒taskSet之后,會遍歷這個taskSet,拿到每一個task,然后去調(diào)用HDFS上的方法,獲取數(shù)據(jù)的位置,根據(jù)獲得的數(shù)據(jù)位置分發(fā)task到響應的Worker節(jié)點的Executor進程中的線程池中執(zhí)行。并且會根據(jù)每個task的執(zhí)行情況監(jiān)控,等到所有task執(zhí)行完成后,就告訴master將所喲executor殺死任務調(diào)度中主要涉涉及到以下流程:
1)、DAGScheduler:根據(jù)RDD的寬窄依賴關(guān)系將DAG有向無環(huán)圖切割成一個個的stage,將stage封裝給另一個對象taskSet,taskSet=stage,然后將一個個的taskSet給taskScheduler。
2)、taskScheduler:taskSeheduler拿倒taskSet之后,會遍歷這個taskSet,拿到每一個task,然后去調(diào)用HDFS上的方法,獲取數(shù)據(jù)的位置,根據(jù)獲得的數(shù)據(jù)位置分發(fā)task到響應的Worker節(jié)點的Executor進程中的線程池中執(zhí)行。
3)、taskScheduler:taskScheduler節(jié)點會跟蹤每一個task的執(zhí)行情況,若執(zhí)行失敗,TaskScher會嘗試重新提交,默認會重試提交三次,如果重試三次依然失敗,那么這個task所在的stage失敗,此時TaskScheduler向DAGScheduler做匯報。
4)DAGScheduler:接收到stage失敗的請求后,,此時DAGSheduler會重新提交這個失敗的stage,已經(jīng)成功的stage不會重復提交,只會重試這個失敗的stage。
(注:如果DAGScheduler重試了四次依然失敗,那么這個job就失敗了,job不會重試掉隊任務的概念:
當所有的task中,75%以上的task都運行成功了,就會每隔一百秒計算一次,計算出目前所有未成功任務執(zhí)行時間的中位數(shù)*1.5,凡是比這個時間長的task都是掙扎的task。總的調(diào)度流程:
=======================================資源調(diào)度=========================================
1、啟動Master和備用Master(如果是高可用集群需要啟動備用Master,否則沒有備用Master)。
2、啟動Worker節(jié)點。Worker節(jié)點啟動成功后會向Master注冊。在works集合中添加自身信息。
3、在客戶端提交Application,啟動spark-submit進程。偽代碼:spark-submit --master --deploy-mode cluster --class jarPath
4、Client向Master為Driver申請資源。申請信息到達Master后在Master的waitingDrivers集合中添加該Driver的申請信息。
5、當waitingDrivers集合不為空,調(diào)用schedule()方法,Master查找works集合,在符合條件的Work節(jié)點啟動Driver。啟動Driver成功后,waitingDrivers集合中的該條申請信息移除。Client客戶端的spark-submit進程關(guān)閉。
(Driver啟動成功后,會創(chuàng)建DAGScheduler對象和TaskSchedule對象)
6、當TaskScheduler創(chuàng)建成功后,會向Master會Application申請資源。申請請求發(fā)送到Master端后會在waitingApps集合中添加該申請信息。
7、當waitingApps集合中的元素發(fā)生改變,會調(diào)用schedule()方法。查找works集合,在符合要求的worker節(jié)點啟動Executor進程。
8、當Executor進程啟動成功后會將waitingApps集合中的該申請信息移除。并且向TaskSchedule反向注冊。此時TaskSchedule就有一批Executor的列表信息。
=======================================任務調(diào)度=========================================
9、根據(jù)RDD的寬窄依賴,切割job,劃分stage。每一個stage是由一組task組成的。每一個task是一個pipleline計算模式。
10、TaskScheduler會根據(jù)數(shù)據(jù)位置分發(fā)task。(taskScheduler是如何拿到數(shù)據(jù)位置的???TaskSchedule調(diào)用HDFS的api,拿到數(shù)據(jù)的block塊以及block塊的位置信息)
11、TaskSchedule分發(fā)task并且監(jiān)控task的執(zhí)行情況。
12、若task執(zhí)行失敗或者掙扎。會重試這個task。默認會重試三次。
13、若重試三次依舊失敗。會把這個task返回給DAGScheduler,DAGScheduler會重試這個失敗的stage(只重試失敗的這個stage)。默認重試四次。
14、告訴master,將集群中的executor殺死,釋放資源。
文章題目:三、spark--spark調(diào)度原理分析
URL網(wǎng)址:http://www.chinadenli.net/article42/jiihhc.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供定制開發(fā)、網(wǎng)站導航、虛擬主機、品牌網(wǎng)站設(shè)計、網(wǎng)站排名、網(wǎng)站營銷
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)

- 提高采集內(nèi)容收錄量和排名的方法是什么? 2015-10-01
- 網(wǎng)站優(yōu)化之網(wǎng)站收錄篇 2016-11-02
- 東營百度快照網(wǎng)站收錄與索引有哪些差異之處?探討網(wǎng)站索引量晉升的要領(lǐng)與能力 2023-01-04
- 【網(wǎng)站排名優(yōu)化】網(wǎng)站有收錄關(guān)鍵詞卻沒排名是什么原因?如何解決? 2016-11-10
- 網(wǎng)站外鏈怎么發(fā)才會被收錄 ? 2016-10-26
- 如何提升網(wǎng)站的收錄量 2014-10-25
- 網(wǎng)站收錄突然減少怎么辦 2022-09-13
- 成都網(wǎng)站優(yōu)化:收錄量和外鏈到底是哪個重要? 2016-10-31
- 如何檢測判斷網(wǎng)站不被收錄的原因 2014-07-11
- 網(wǎng)站不被收錄或者收錄少是怎么回事 2014-12-06
- 網(wǎng)站內(nèi)頁一直不被收錄是什么原因? 2014-08-13
- 如何快速收錄,如何讓網(wǎng)站內(nèi)容被百度快速收錄? 2016-08-20