內(nèi)存崩潰了?其實(shí)你只需要換一種方式
使用 JDK 自帶的 Set 集合來(lái)進(jìn)行 URL 去重,看上去效果不錯(cuò),但是這種做法有一個(gè)致命了缺陷,就是隨著采集的 URL 增多,你需要的內(nèi)存越來(lái)越大,最終會(huì)導(dǎo)致你的內(nèi)存崩潰。那我們?cè)诓皇褂脭?shù)據(jù)庫(kù)的情況下有沒(méi)有解決辦法呢?布隆過(guò)濾器!它就可以完美解決這個(gè)問(wèn)題,布隆過(guò)濾器有什么特殊的地方呢?接下來(lái)就一起來(lái)學(xué)習(xí)一下布隆過(guò)濾器。
我們一直強(qiáng)調(diào)成都做網(wǎng)站、網(wǎng)站設(shè)計(jì)對(duì)于企業(yè)的重要性,如果您也覺(jué)得重要,那么就需要我們慎重對(duì)待,選擇一個(gè)安全靠譜的網(wǎng)站建設(shè)公司,企業(yè)網(wǎng)站我們建議是要么不做,要么就做好,讓網(wǎng)站能真正成為企業(yè)發(fā)展過(guò)程中的有力推手。專業(yè)網(wǎng)站建設(shè)公司不一定是大公司,成都創(chuàng)新互聯(lián)作為專業(yè)的網(wǎng)絡(luò)公司選擇我們就是放心。
什么是布隆過(guò)濾器
布隆過(guò)濾器是一種數(shù)據(jù)結(jié)構(gòu),比較巧妙的概率型數(shù)據(jù)結(jié)構(gòu),它是在 1970 年由一個(gè)名叫布隆提出的,它實(shí)際上是由一個(gè)很長(zhǎng)的二進(jìn)制向量和一系列隨機(jī)映射函數(shù)組成,這點(diǎn)跟哈希表有些相同,但是相對(duì)哈希表來(lái)說(shuō)布隆過(guò)濾器它更高效、占用空間更少,布隆過(guò)濾器有一個(gè)缺點(diǎn)那就是有一定的誤識(shí)別率和刪除困難。布隆過(guò)濾器只能告訴你某個(gè)元素一定不存在或者可能存在在集合中, 所以布隆過(guò)濾器經(jīng)常用來(lái)處理可以忍受判斷失誤的業(yè)務(wù),比如爬蟲(chóng) URL 去重。
布隆過(guò)濾器原理
在說(shuō)布隆過(guò)濾器原理之前,我們先來(lái)復(fù)習(xí)一下哈希表,利用 Set 來(lái)進(jìn)行 URL 去重,我們來(lái)看看 Set 的存儲(chǔ)模型
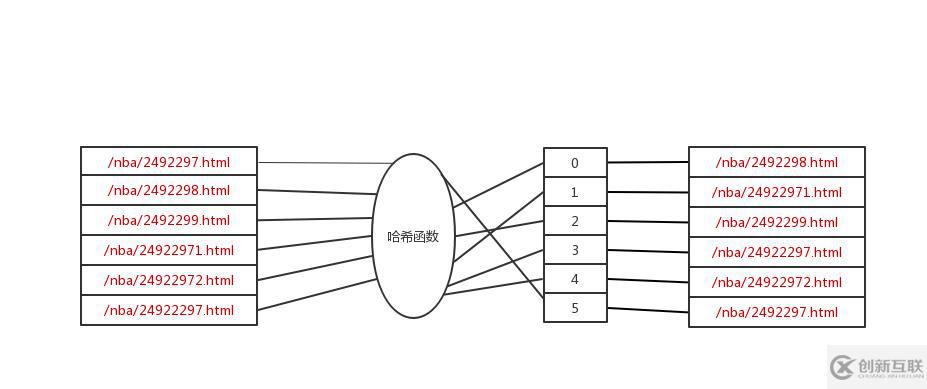
URL 經(jīng)過(guò)一個(gè)哈希函數(shù)后,將 URL 存入了數(shù)組里,這樣查詢時(shí)也是非常高效的,但是由于數(shù)組里存入的是 URL,隨著 URL 的增多,需要的數(shù)組越來(lái)越大,意味著你需要更多的內(nèi)存,比如我們采集了幾億的 URL,那么可能就需要上百G 的內(nèi)存,這是條件不允許的,因?yàn)閮?nèi)存特別的昂貴,所以這個(gè)在 url 去重中是不可取的,占內(nèi)存更小的布隆過(guò)濾器就是一種不錯(cuò)的選擇。
布隆過(guò)濾器實(shí)質(zhì)上由長(zhǎng)度為 m 的位向量或位列表(僅包含 0 或 1 位值的列表)組成,最初所有值均設(shè)置為 0,如下所示。

因?yàn)榈讓邮?bit 數(shù)組,所以意味著數(shù)組只有 0、1 兩個(gè)值,跟哈希表一樣,我們將 URL 通過(guò) K 個(gè)函數(shù)映射 bit 數(shù)組里,并且將指向的 Bit 數(shù)組對(duì)應(yīng)的值改成 1 。我們以存?/nba/2492297.html?為例,如下圖所示:
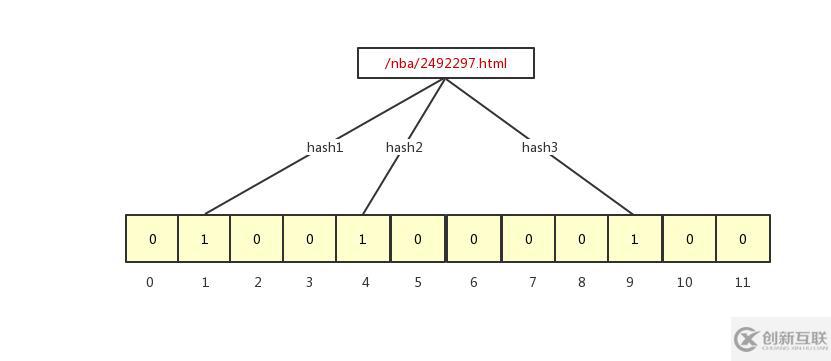
/nba/2492297.html經(jīng)過(guò)三個(gè)哈希函數(shù)分別映射到了 1、4、9 的位置,這三個(gè) bit 數(shù)組的值就變成了 1,我們?cè)俅嫒胍粋€(gè)?/nba/2492298.html,此時(shí) bit 數(shù)組就變成下面這樣:
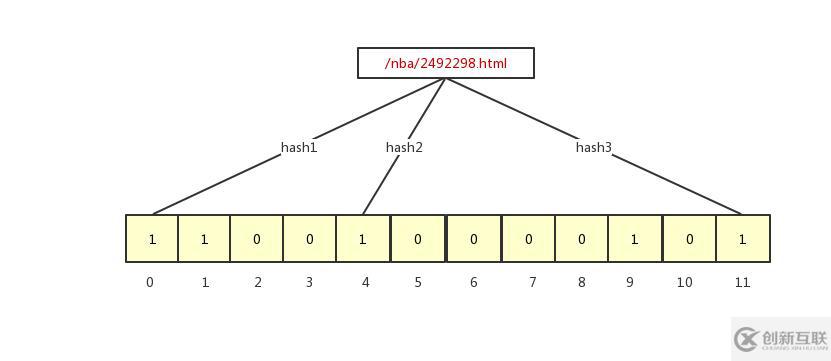
/nba/2492298.html被映射到了 0、4、11 的位置,所以此時(shí) bit 數(shù)組上有 5 個(gè)位置的值為 1,本應(yīng)該是有 6 個(gè)值為 1 的,但是因?yàn)樵?4 這個(gè)位置重復(fù)了,所以會(huì)覆蓋。
布隆過(guò)濾器是如何判斷某個(gè)值一定不存在或者可能存在呢?通過(guò)判斷哈希函數(shù)映射到對(duì)應(yīng)數(shù)組的值,如果都為 1,說(shuō)明可能存在,如果有一個(gè)不為 1,說(shuō)明一定不存在。對(duì)于一定不存在好理解,但是都為 1 時(shí),為什么說(shuō)可能存在呢?這跟哈希表一樣,哈希函數(shù)會(huì)產(chǎn)生哈希沖突,也就是說(shuō)兩個(gè)不同的值經(jīng)過(guò)哈希函數(shù)都會(huì)得到同一個(gè)數(shù)組下標(biāo),布隆過(guò)濾器也是一樣的。我們以判斷?/nba/2492299.html?是否已經(jīng)采集過(guò)為例,經(jīng)過(guò)哈希函數(shù)映射的 bit 數(shù)組上的位置入下圖所示:
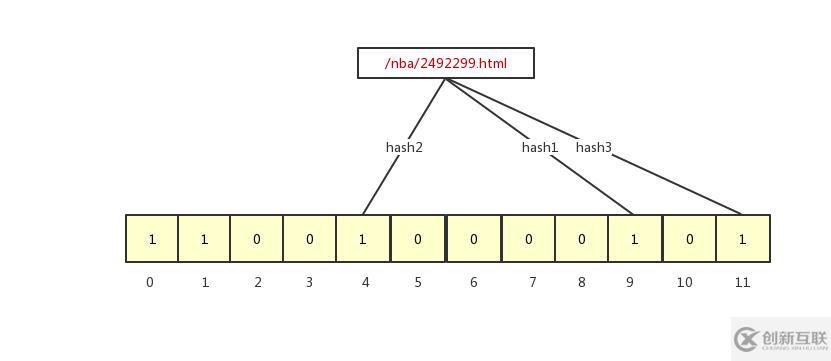
/nba/2492299.html?被哈希函數(shù)映射到了 4、9、11 的位置,而這幾個(gè)位置的值都為 1 ,所以布隆過(guò)濾器就認(rèn)為?/nba/2492299.html?被采集過(guò)了,實(shí)際上是沒(méi)有采集過(guò)的,這就說(shuō)明了布隆過(guò)濾器存在誤判,這也是我們業(yè)務(wù)允許的。布隆過(guò)濾器的誤判率跟 bit 數(shù)組的大小和哈希函數(shù)的個(gè)數(shù)有關(guān)系,如果 bit 數(shù)組過(guò)小,哈希函數(shù)過(guò)多,那么 bit 數(shù)組的值很快都會(huì)變成 1,這樣誤判率就會(huì)越來(lái)越高,bit 數(shù)組過(guò)大,就會(huì)浪費(fèi)更多的內(nèi)存,所以就要平衡好 bit 數(shù)組的大小和哈希函數(shù)的個(gè)數(shù),關(guān)于如何平衡這兩個(gè)的關(guān)系,不是我們這篇文章的重點(diǎn)。
布隆過(guò)濾器的原理我們已經(jīng)了解了,為了加深對(duì)布隆過(guò)濾器的理解,我們用 Java 來(lái)實(shí)現(xiàn)一個(gè)簡(jiǎn)易辦的布隆過(guò)濾器,代碼如下:
public class SimpleBloomFilterTest {
// bit 數(shù)組的大小
private static final int DEFAULT_SIZE = 1000;
// 用來(lái)生產(chǎn)三個(gè)不同的哈希函數(shù)的
private static final int[] seeds = new int[]{7, 31, 61,};
// bit 數(shù)組
private BitSet bits = new BitSet(DEFAULT_SIZE);
// 存放哈希函數(shù)的數(shù)組
private SimpleHash[] func = new SimpleHash[seeds.length];
public static void main(String[] args) {
SimpleBloomFilterTest filter = new SimpleBloomFilterTest();
filter.add("https://voice.hupu.com/nba/2492440.html");
filter.add("https://voice.hupu.com/nba/2492437.html");
filter.add("https://voice.hupu.com/nba/2492439.html");
System.out.println(filter.contains("https://voice.hupu.com/nba/2492440.html"));
System.out.println(filter.contains("https://voice.hupu.com/nba/249244.html"));
}
public SimpleBloomFilterTest() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
/**
* 向布隆過(guò)濾器添加元素
* @param value
*/
public void add(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
/**
* 判斷某元素是否存在布隆過(guò)濾器
* @param value
* @return
*/
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
/**
* 哈希函數(shù)
*/
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
}把上面這段代碼理解好對(duì)我們理解布隆過(guò)濾器非常有幫助,實(shí)際上在工作中并不需要我們自己實(shí)現(xiàn)布隆過(guò)濾器,谷歌已經(jīng)幫我們實(shí)現(xiàn)了布隆過(guò)濾器,在 Guava 包中提供了 BloomFilter,這個(gè)布隆過(guò)濾器實(shí)現(xiàn)的非常棒,下面就看看谷歌辦的布隆過(guò)濾器。
布隆過(guò)濾器 Guava 版
要使用 Guava 包下提供的 BloomFilter ,就需要引入 Guava 包,我們?cè)?pom.xml 中引入下面依賴:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.1-jre</version>
</dependency>Guava 中的布隆過(guò)濾器實(shí)現(xiàn)的非常復(fù)雜,關(guān)于細(xì)節(jié)我們就不去探究了,我們就來(lái)看看 Guava 中布隆過(guò)濾器的構(gòu)造函數(shù)吧,Guava 中并沒(méi)有提供構(gòu)造函數(shù),而且提供了 create 方法來(lái)構(gòu)造布隆過(guò)濾器:
public static <T> BloomFilter<T> create(
Funnel<? super T> funnel, int expectedInsertions, double fpp) {
return create(funnel, (long) expectedInsertions, fpp);
}funnel:你要過(guò)濾數(shù)據(jù)的類型
expectedInsertions:你要存放的數(shù)據(jù)量
fpp:誤判率
你只需要傳入這三個(gè)參數(shù)你就可以使用 Guava 包中的布隆過(guò)濾器了,下面這我寫(xiě)的一段 Guava 布隆過(guò)濾器測(cè)試程序,可以改動(dòng) fpp 多運(yùn)行幾次,體驗(yàn) Guava 的布隆過(guò)濾器。
public class GuavaBloomFilterTest {
// bit 數(shù)組大小
private static int size = 10000;
// 布隆過(guò)濾器
private static BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), size, 0.03);
public static void main(String[] args) {
// 先向布隆過(guò)濾器中添加 10000 個(gè)url
for (int i = 0; i < size; i++) {
String url = "https://voice.hupu.com/nba/" + i;
bloomFilter.put(url);
}
// 前10000個(gè)url不會(huì)出現(xiàn)誤判
for (int i = 0; i < size; i++) {
String url = "https://voice.hupu.com/nba/" + i;
if (!bloomFilter.mightContain(url)) {
System.out.println("該 url 被采集過(guò)了");
}
}
List<String> list = new ArrayList<String>(1000);
// 再向布隆過(guò)濾器中添加 2000 個(gè) url ,在這2000 個(gè)中就會(huì)出現(xiàn)誤判了
// 誤判的個(gè)數(shù)為 2000 * fpp
for (int i = size; i < size + 2000; i++) {
String url = "https://voice.hupu.com/nba/" + i;
if (bloomFilter.mightContain(url)) {
list.add(url);
}
}
System.out.println("誤判數(shù)量:" + list.size());
}
}布隆過(guò)濾器的應(yīng)用
緩存擊穿
緩存擊穿是查詢數(shù)據(jù)庫(kù)中不存在的數(shù)據(jù),如果有用戶惡意模擬請(qǐng)求很多緩存中不存在的數(shù)據(jù),由于緩存中都沒(méi)有,導(dǎo)致這些請(qǐng)求短時(shí)間內(nèi)直接落在了DB上,對(duì)DB產(chǎn)生壓力,導(dǎo)致數(shù)據(jù)庫(kù)異常。
最常見(jiàn)的解決辦法就是采用布隆過(guò)濾器,將所有可能存在的數(shù)據(jù)哈希到一個(gè)足夠大的bitmap中,一個(gè)一定不存在的數(shù)據(jù)會(huì)被這個(gè)bitmap攔截掉,從而避免了對(duì)底層存儲(chǔ)系統(tǒng)的查詢壓力。下面是一段偽代碼:
public String getByKey(String key) {
// 通過(guò)key獲取value
String value = redis.get(key);
if (StringUtil.isEmpty(value)) {
if (bloomFilter.mightContain(key)) {
value = xxxService.get(key);
redis.set(key, value);
return value;
} else {
return null;
}
}
return value;
}爬蟲(chóng) URL 去重
爬蟲(chóng)是對(duì) url 的去重,防止 url 重復(fù)采集,這也是我們這篇文章重點(diǎn)講解的內(nèi)容
垃圾郵件識(shí)別
從數(shù)十億個(gè)垃圾郵件列表中判斷某郵箱是否垃圾郵箱,將垃圾郵箱添加到布隆過(guò)濾器中,然后判斷某個(gè)郵件是否是存在在布隆過(guò)濾器中,存在說(shuō)明就是垃圾郵箱。
分享文章:內(nèi)存崩潰了?其實(shí)你只需要換一種方式
文章來(lái)源:http://www.chinadenli.net/article42/gpsghc.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供響應(yīng)式網(wǎng)站、營(yíng)銷型網(wǎng)站建設(shè)、網(wǎng)站改版、品牌網(wǎng)站建設(shè)、網(wǎng)頁(yè)設(shè)計(jì)公司、App設(shè)計(jì)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)

- 成都網(wǎng)站建設(shè)之動(dòng)態(tài)網(wǎng)站好還是靜態(tài)網(wǎng)站好 2022-07-31
- 新聞動(dòng)態(tài)網(wǎng)站建設(shè)對(duì)建設(shè)人員的要求 2022-05-02
- 靜態(tài)網(wǎng)站跟動(dòng)態(tài)網(wǎng)站在制作上有哪些區(qū)別呢 2016-11-12
- 網(wǎng)站建設(shè)中關(guān)于靜態(tài)頁(yè)面和動(dòng)態(tài)頁(yè)面的區(qū)分 2016-10-02
- 靜態(tài)網(wǎng)站與動(dòng)態(tài)網(wǎng)站的特點(diǎn) 2016-11-11
- 淺談關(guān)于網(wǎng)站的動(dòng)態(tài)URL和靜態(tài)URL 2014-03-13
- 動(dòng)態(tài)網(wǎng)站做seo優(yōu)化可以怎么辦? 2013-05-29
- 什么是靜態(tài)網(wǎng)站、動(dòng)態(tài)網(wǎng)站?有何優(yōu)缺點(diǎn)? 2016-11-10
- 成都網(wǎng)站建設(shè)怎樣選擇動(dòng)態(tài)或偽靜態(tài) 2016-08-22
- 網(wǎng)站建設(shè)基礎(chǔ)知識(shí)之靜態(tài)和動(dòng)態(tài)網(wǎng)站(一) 2016-09-16
- 新聞動(dòng)態(tài)網(wǎng)站內(nèi)容和農(nóng)民的信息需求之間存在差異 2022-05-04
- 動(dòng)態(tài)網(wǎng)站與靜態(tài)網(wǎng)站相對(duì)比有哪些優(yōu)缺點(diǎn) 2023-04-02