如何用python獲取免費(fèi)代理IP
這篇文章主要介紹了如何用python獲取免費(fèi)代理IP的相關(guān)知識(shí),內(nèi)容詳細(xì)易懂,操作簡(jiǎn)單快捷,具有一定借鑒價(jià)值,相信大家閱讀完這篇如何用python獲取免費(fèi)代理IP文章都會(huì)有所收獲,下面我們一起來看看吧。
我們提供的服務(wù)有:成都網(wǎng)站制作、做網(wǎng)站、外貿(mào)營(yíng)銷網(wǎng)站建設(shè)、微信公眾號(hào)開發(fā)、網(wǎng)站優(yōu)化、網(wǎng)站認(rèn)證、白堿灘ssl等。為成百上千企事業(yè)單位解決了網(wǎng)站和推廣的問題。提供周到的售前咨詢和貼心的售后服務(wù),是有科學(xué)管理、有技術(shù)的白堿灘網(wǎng)站制作公司
首先創(chuàng)建scrapy項(xiàng)目, 運(yùn)行一下命令:
$ scrapy startproject getProxy kuaidaili.com
$ scrapy genspider proxyKdlSpider kuaidaili.com
百度搜索免費(fèi)代理ip, 我進(jìn)的是快代理, 頁面通過列表顯示代理ip及其相關(guān)信息的。
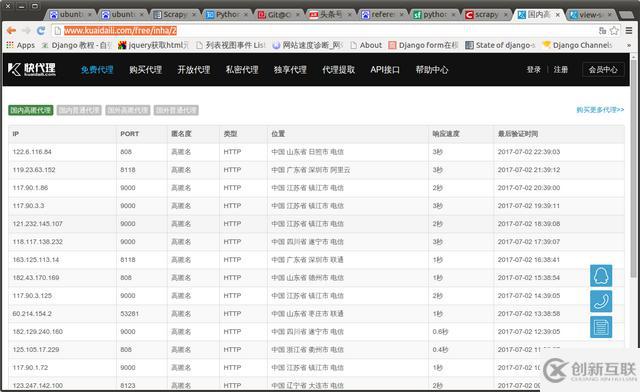
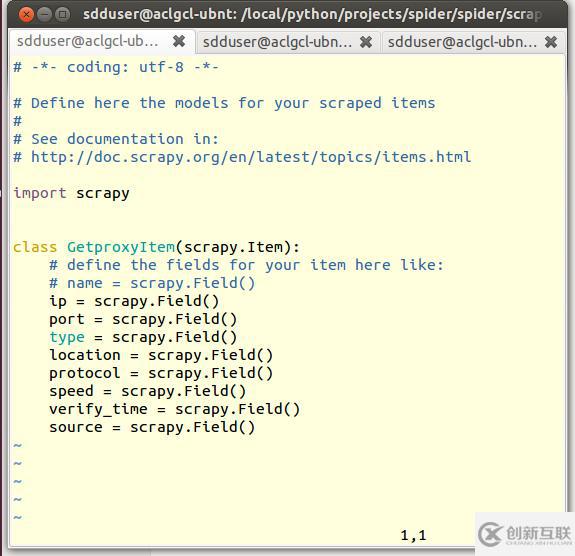
3. 通過以上的界面, 改寫items.py, 增加如下項(xiàng), 用來保存代理ip的相關(guān)信息
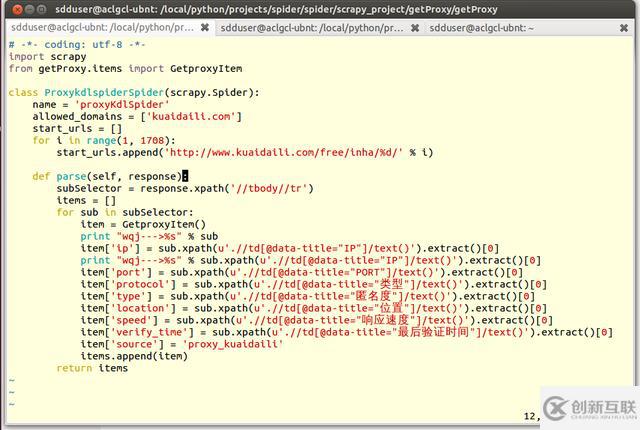
4. 通過觀察頁面源碼, 發(fā)現(xiàn)我們需要的代理ip信息可用xpath輕易獲取。

5. 通過上圖觀察到的規(guī)律改寫proxyKdlSpider.py文件, 通過如下xpath可獲取代理ip信息。
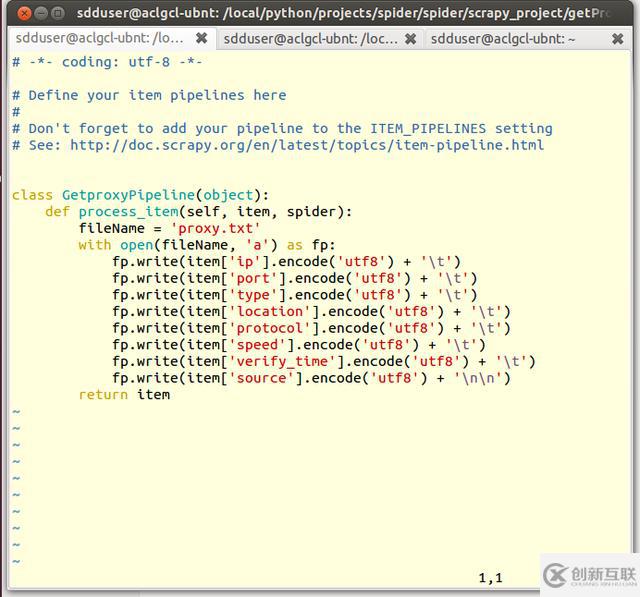
6. 改寫pipelines.py, 將解析提取出來的代理ip信息保存到文件proxy.txt中。
7. 改寫settings.py, 增加以下行:

其中USER_AGENT會(huì)改寫請(qǐng)求headers。 因快代理網(wǎng)站會(huì)通過USER_AGENT來判斷訪問者是否爬蟲, 不這樣設(shè)置會(huì)導(dǎo)致運(yùn)行爬蟲的ip被封禁。
設(shè)置DOWNLOAD_DELAY=5含義是爬蟲每5s請(qǐng)求一個(gè)網(wǎng)頁, 這樣設(shè)置的目的是為了避免快速訪問大量網(wǎng)頁觸發(fā)網(wǎng)站的反爬蟲機(jī)制
設(shè)置ITEM_PIPELINES是告訴爬蟲在過濾完需要的信息后如何保存。
8 運(yùn)行編寫的爬蟲:
$ scrapy crawl proxyKdlSpider
由于我們限制了采集速度, 過程會(huì)有點(diǎn)長(zhǎng)。 運(yùn)行完畢后采集結(jié)果如下:
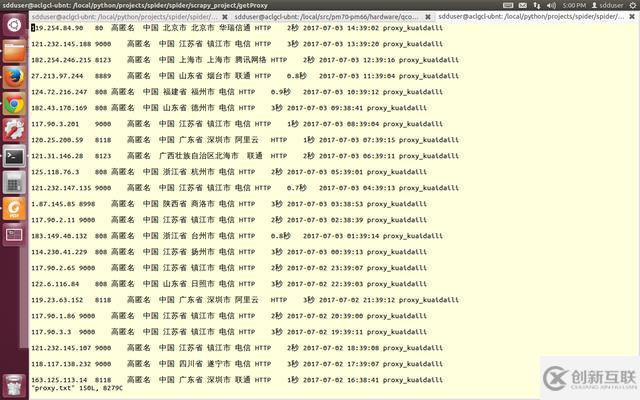
關(guān)于“如何用python獲取免費(fèi)代理IP”這篇文章的內(nèi)容就介紹到這里,感謝各位的閱讀!相信大家對(duì)“如何用python獲取免費(fèi)代理IP”知識(shí)都有一定的了解,大家如果還想學(xué)習(xí)更多知識(shí),歡迎關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道。
網(wǎng)站標(biāo)題:如何用python獲取免費(fèi)代理IP
網(wǎng)站鏈接:http://www.chinadenli.net/article42/gpciec.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供全網(wǎng)營(yíng)銷推廣、網(wǎng)站營(yíng)銷、App開發(fā)、ChatGPT、網(wǎng)站建設(shè)、網(wǎng)站內(nèi)鏈
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來源: 創(chuàng)新互聯(lián)

- 定制網(wǎng)站建設(shè)的方式是啥? 2013-11-11
- 影響企業(yè)定制網(wǎng)站建設(shè)報(bào)價(jià)的因素 2016-08-14
- 自助建站與定制網(wǎng)站的區(qū)別 2016-01-24
- 給企業(yè)定制網(wǎng)站建設(shè)的進(jìn)一步的深入分析 2021-03-25
- 定制網(wǎng)站建設(shè)可以提高企業(yè)的網(wǎng)絡(luò)虛擬形象 2019-04-30
- 定制網(wǎng)站建設(shè)需要注意哪些 2016-05-31
- 打造高端定制網(wǎng)站建設(shè)關(guān)鍵點(diǎn) 2016-08-02
- 定制網(wǎng)站建設(shè)的特點(diǎn)是什么? 2021-09-09
- 定制網(wǎng)站制作要注意哪些問題? 2021-12-04
- 高端定制網(wǎng)站有哪些優(yōu)勢(shì)? 2023-01-25
- 定制網(wǎng)站和模板網(wǎng)站的區(qū)別 2016-10-28
- 佛山定制網(wǎng)站制作的流程和步驟 2022-11-23