Yelp的PaaStorm內部機制是什么
這篇文章主要介紹“Yelp的PaaStorm內部機制是什么”,在日常操作中,相信很多人在Yelp的PaaStorm內部機制是什么問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Yelp的PaaStorm內部機制是什么”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
創(chuàng)新互聯(lián)建站是一家集網(wǎng)站建設,連云港企業(yè)網(wǎng)站建設,連云港品牌網(wǎng)站建設,網(wǎng)站定制,連云港網(wǎng)站建設報價,網(wǎng)絡營銷,網(wǎng)絡優(yōu)化,連云港網(wǎng)站推廣為一體的創(chuàng)新建站企業(yè),幫助傳統(tǒng)企業(yè)提升企業(yè)形象加強企業(yè)競爭力。可充分滿足這一群體相比中小企業(yè)更為豐富、高端、多元的互聯(lián)網(wǎng)需求。同時我們時刻保持專業(yè)、時尚、前沿,時刻以成就客戶成長自我,堅持不斷學習、思考、沉淀、凈化自己,讓我們?yōu)楦嗟钠髽I(yè)打造出實用型網(wǎng)站。
這名字中有什么含義?
PaaStorm的名字其實是PaaSTA和Storm的組合。那PaaStorm到底是干什么的呢?要回答這個問題,咱們先看看數(shù)據(jù)管道的基本架構:
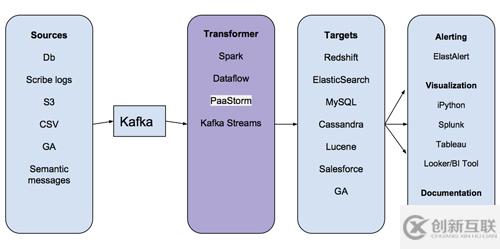
主要看看“Transformer”那一步,就會知道大多數(shù)存儲在Kafka中的消息都并不能直接被導入目標系統(tǒng)。設想有一套Redshift集群是用來存儲廣告推送數(shù)據(jù)的。廣告推送集群想存儲的只是上游系統(tǒng)的某一個字段(比如某個業(yè)務的平均權重),否則它就要保存原始數(shù)據(jù)并對其進行聚合計算。如果Redhift廣告推送集群要存儲所有上游數(shù)據(jù)的話,就會浪費存儲空間,導致系統(tǒng)性能降低。
在過去,各個服務都會寫復雜的MapReduce任務,在把數(shù)據(jù)寫到目標數(shù)據(jù)存儲之前先進行數(shù)據(jù)處理。可是,這些MapReduce任務都碰到了上文所述的性能和擴展問題。數(shù)據(jù)管道給大家提供的好處之一是消費者程序可以拿到它所需要的數(shù)據(jù)的形式,不管上游數(shù)據(jù)本來是什么樣。
減少示例代碼
本來我們是可以讓每個消費者程序自己按自己需要的方式做數(shù)據(jù)轉換的。比如,廣告推送系統(tǒng)可以自己寫一個轉換服務,從Kafka中的業(yè)務數(shù)據(jù)中提取出查看統(tǒng)計量,并自己維護這個轉換服務的。這種辦法最初工作得很好,但最終系統(tǒng)上規(guī)模時我們就碰上問題了。
我們想提供一個轉換框架是基于以下考慮:
很多轉換邏輯是通用的,可以在多個團隊之間共享。比如把標志位轉換成有意義的字段。
這樣的轉換邏輯通常會需要很多示例代碼。比如連接數(shù)據(jù)源或數(shù)據(jù)目的、保存狀態(tài)、監(jiān)控吞吐量、故障恢復等。這樣的代碼本來并不需要在各種服務之間拷來拷去。
要保證能對數(shù)據(jù)進行實時處理的話,數(shù)據(jù)轉換操作要盡可能地快,要基于流。
減少示例代碼最自然的方式就是提供一個轉換接口。大家的服務實現(xiàn)接口中完成一次轉換操作的具體邏輯,然后,剩下的工作就由我們的流處理框架完成。
把Kafka作為消息總線
最初PaaStorm是一個Kafka-to-Kafka的轉換框架,慢慢地才演進成也支持了其他類型的終端節(jié)點。把Kafka做為PaaStorm的終端節(jié)點簡化了很多東西:每個對數(shù)據(jù)感興趣的服務都可以注冊到Topic上,關注任意轉換過的數(shù)據(jù)或者原始數(shù)據(jù),有新消息到來就處理就好了,完全不必在意是誰創(chuàng)建了這個Topic。轉換過的數(shù)據(jù)按Kafka的保留策略持久化。因為Kafka是一個發(fā)布-訂閱系統(tǒng),下游系統(tǒng)也可以在任何它想的時候消費數(shù)據(jù)。
用Storm處理一切
當采用了PaaStorm之后,我們該怎樣把我們的Kafka Topic之間的關系可視化呢?因為有些Topic中的數(shù)據(jù)會按照源到端的方式流向別的Topic,我們可以把我們的拓撲結構當成一個有向無環(huán)圖:
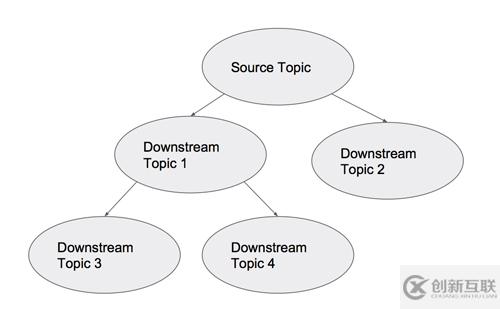
每個節(jié)點都是一個Kafka Topic,箭頭表示PaaStorm提供的轉換操作。這時候“PaaStorm”這個名字就變得更有意義了:象Storm一樣,PaaStorm通過轉換模塊(象Bolt一樣)提供對數(shù)據(jù)流的源(象Spout一樣)的實時轉換。
PaaStorm內部機制
PaaStorm的核心抽象叫做Spolt(Spout和Bolt的結合物)。象名字表示的一樣,Spolt接口也定義了兩個重要的東西:一個輸入數(shù)據(jù)源,一種對那個源的消息數(shù)據(jù)進行的某種處理。
下面例子定義了一個最簡單的Spolt:
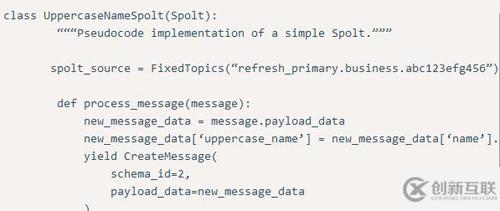
這個Spolt會處理“refresh_primary.business.abc123efg456”這個Topic中的每一條消息,增加一個字段,保存原始消息中的‘name’字段的大寫的值,然后再把這條處理過的新版本的消息發(fā)送出去。
值得一提的是數(shù)據(jù)管道中的所有消息都是不可修改的。要得到一條修改過的消息,就要創(chuàng)建一個新的對象。而且,因為我們在為消息體中增加一個新字段(就是那個增加的“大寫字母的name”字段),新消息的模式已經(jīng)改變了。在生產(chǎn)環(huán)境中,消息的模式ID是從來都不能寫死的。我們要依靠Schematizer服務來為一條修改過的消息注冊并提供合適的模式。
***提一句,數(shù)據(jù)管道的客戶端庫提供了好幾種非常相似的用名字空間、Topic名、源名和模式ID的組合來生成“spolt_source”的方法。這樣就可以很容易地讓某個Spolt去找到它需要的所有源并從中讀取數(shù)據(jù)。
與Kafka相關的處理是怎樣的?
也許你已經(jīng)發(fā)現(xiàn)上面的Spolt中沒有什么代碼是與Kafka Topic相交互的。這是因為在PaaStorm中,所有真正的Kafka接口相關處理都是由一個內部實例(恰好也叫PaaStorm)完成的。PaaStorm實例會把一個特定的Spolt與對應的源和目的關聯(lián)起來,并把消息送給Spolt處理,再把Spolt輸出的消息發(fā)布到正確的Topic上去。
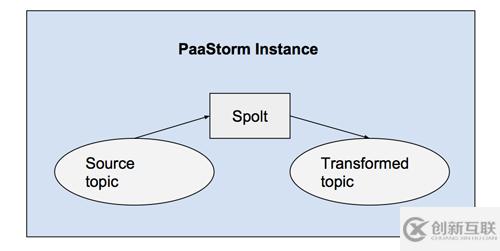
每個PaaStorm實例都用一個Spolt初始化。比如,下面的命令就用上文中定義的UppercaseNameSpolt開啟了一次處理:
PaaStorm(UppercaseNameSpolt()).start()
這就意味著所有有意寫一個新轉換器的人都可以簡單地定義一個新的Spolt子類,壓根不用修改任何PaaStorm運行體相關的東西。
從內部來看,PaaStorm運行體的主方法也是驚人的簡單,偽碼如下:

這個運行體先做了一些設置:初始化了生產(chǎn)者和消費者,以及消息計數(shù)器。然后,它一直等待上游Topic中的新數(shù)據(jù)。如果有新數(shù)據(jù)到來,就用Spolt處理它。Spolt處理之后會輸出一條或多條消息,生產(chǎn)者再把它發(fā)布到下游的Topic。
另外簡單提一下,PaaStorm運行體也提供了比如消費者注冊、心跳機制(名叫“tick”)等。比如某個Spolt要經(jīng)常性地清空它的內容,那就可以用tick來觸發(fā)。
關于狀態(tài)保存
PaaStorm保證可以可靠地從故障中恢復。萬一發(fā)生了崩潰,我們就該從正確的偏移位置開始重新消費。但不幸的是,這個正確的偏移量一般情況下都并不是我們從上游的Topic中消費的***那一條消息。原因是雖然我們已經(jīng)消費了它,但事實上我們還沒來得及把轉換后的版本發(fā)布出去。
所以重新啟動時正確的位置應該是上游Topic與已經(jīng)成功發(fā)布到下游的***一條消息對應的位置。在知道發(fā)到下游的***一條消息的情況之后,我們需要知道它對應的上游的消息是哪一條,這樣就可以從那里恢復了。
為了方便實現(xiàn)這個功能,PaaStorm的Spolt在處理一條原始消息時,會把與這條原始消息相對應的在上游Topic中的Kafka偏移量也加到轉換后的包里。轉換后的消息隨后會在生產(chǎn)者的回調函數(shù)中把這個偏移量傳回來。這樣,我們就可以知道與下游Topic中***一條消息對應的上游Topic的偏移量了。因為回調函數(shù)只有在生產(chǎn)者成功地把轉換后的消息發(fā)布出去之后才會調用,也就意味著原始消息已經(jīng)被成功處理了,在這種情況下,消費者就可以很放心的在那個回調函數(shù)中提交這個偏移量了。萬一發(fā)生崩潰,我們可以直接從還沒有被完全處理的上游消息那里開始繼續(xù)處理。
從上面的偽碼中可以看到,PaaStorm也會統(tǒng)計消費掉的消息數(shù)和發(fā)布的消息數(shù)。這樣,感興趣的用戶可以檢查上游和下游Topic中的吞吐量。這讓我們很輕松地有了對任意轉換操作的監(jiān)控和性能檢查功能。在Yelp,我們是把我們的統(tǒng)計信息發(fā)給SignalFX的:
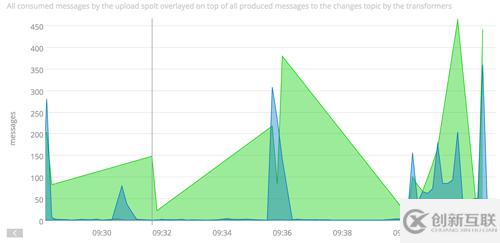
SignalFX圖可以顯示出在一個PaaStorm實例中生產(chǎn)者和消費者的吞吐量。在這個例子中,輸入輸出消息量并不匹配。
在PaaStorm中對生產(chǎn)者和消費者分開做統(tǒng)計的好處之一是我們可以把這兩個吞吐量放在一起,看看瓶頸是在哪里。如果到不了這個粒度,是很難發(fā)現(xiàn)管道中的性能問題的。
到此,關于“Yelp的PaaStorm內部機制是什么”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續(xù)學習更多相關知識,請繼續(xù)關注創(chuàng)新互聯(lián)網(wǎng)站,小編會繼續(xù)努力為大家?guī)砀鄬嵱玫奈恼拢?/p>
網(wǎng)站名稱:Yelp的PaaStorm內部機制是什么
標題來源:http://www.chinadenli.net/article40/ippieo.html
成都網(wǎng)站建設公司_創(chuàng)新互聯(lián),為您提供靜態(tài)網(wǎng)站、外貿網(wǎng)站建設、Google、軟件開發(fā)、App設計、搜索引擎優(yōu)化
聲明:本網(wǎng)站發(fā)布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經(jīng)允許不得轉載,或轉載時需注明來源: 創(chuàng)新互聯(lián)

- 互聯(lián)網(wǎng)營銷時代全網(wǎng)營銷推廣是重點 2021-01-27
- 企業(yè)全網(wǎng)營銷型網(wǎng)站建設的重點有哪一些? 2016-11-07
- 成都全網(wǎng)營銷推廣方式有哪些? 2016-11-11
- 做一個全網(wǎng)營銷網(wǎng)站費用是多少? 2015-06-18
- 企業(yè)制定全網(wǎng)營銷推廣方案有哪些方法 2022-07-17
- 全網(wǎng)營銷比傳統(tǒng)營銷有哪些優(yōu)勢? 2015-06-23
- 全網(wǎng)營銷是什么?中小企業(yè)應如何做好全網(wǎng)營銷? 2016-11-09
- 全網(wǎng)營銷的重點是什么? 2015-06-23
- 你知道全網(wǎng)營銷推廣具體指的哪些方面嗎 2021-09-05
- 外貿營銷新思路:O2O全網(wǎng)營銷 2016-03-09
- 網(wǎng)絡營銷中全網(wǎng)營銷對企業(yè)有什么幫助? 2014-08-02
- 全網(wǎng)營銷占領百度制高點 2014-04-01