kafka分析與單機(jī)使用記錄是怎樣的
這期內(nèi)容當(dāng)中小編將會(huì)給大家?guī)?lái)有關(guān)kafka分析與單機(jī)使用記錄是怎樣的,文章內(nèi)容豐富且以專業(yè)的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
成都創(chuàng)新互聯(lián)公司是專業(yè)的萊州網(wǎng)站建設(shè)公司,萊州接單;提供成都網(wǎng)站建設(shè)、成都做網(wǎng)站,網(wǎng)頁(yè)設(shè)計(jì),網(wǎng)站設(shè)計(jì),建網(wǎng)站,PHP網(wǎng)站建設(shè)等專業(yè)做網(wǎng)站服務(wù);采用PHP框架,可快速的進(jìn)行萊州網(wǎng)站開(kāi)發(fā)網(wǎng)頁(yè)制作和功能擴(kuò)展;專業(yè)做搜索引擎喜愛(ài)的網(wǎng)站,專業(yè)的做網(wǎng)站團(tuán)隊(duì),希望更多企業(yè)前來(lái)合作!
1.使用的系統(tǒng)環(huán)境
root@heidsoft:~# uname -a
Linux heidsoft 4.4.0-63-generic #84-Ubuntu SMP Wed Feb 1 17:20:32 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
2.JDK環(huán)境
root@heidsoft:~# java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
3.軟件版本環(huán)境

4.配置文件環(huán)境
kafka : server.properties 默認(rèn)配置
zookeeper : zoo.cfg 默認(rèn)配置
5.啟動(dòng)應(yīng)用
zookeeper: sh zkServer.sh start
kafka: bin/kafka-server-start.sh config/server.properties &
6.kafka 測(cè)試
生產(chǎn)者測(cè)試--發(fā)送消息
echo "Hello, World" | bin/kafka-console-producer.sh --broker-list localhost:9092 --topic TutorialTopic > /dev/null
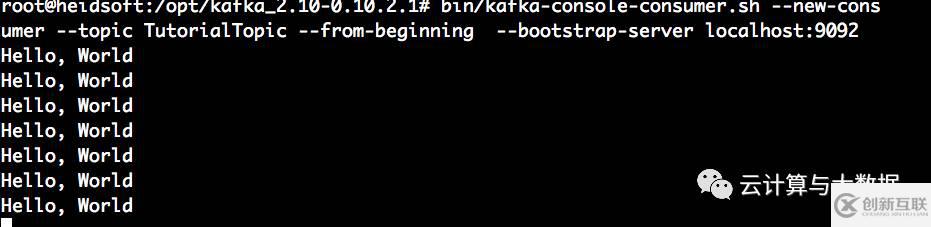
消費(fèi)者測(cè)試--接收消息
bin/kafka-console-consumer.sh --new-consumer --topic TutorialTopic --from-beginning --bootstrap-server localhost:9092
7.ShowDemo

8.概念認(rèn)識(shí)
Broker
Kafka集群包含一個(gè)或多個(gè)服務(wù)器,這種服務(wù)器被稱為brokerTopic
每條發(fā)布到Kafka集群的消息都有一個(gè)類別,這個(gè)類別被稱為T(mén)opic。(物理上不同Topic的消息分開(kāi)存儲(chǔ),邏輯上一個(gè)Topic的消息雖然保存于一個(gè)或多個(gè)broker上但用戶只需指定消息的Topic即可生產(chǎn)或消費(fèi)數(shù)據(jù)而不必關(guān)心數(shù)據(jù)存于何處)Partition
Parition是物理上的概念,每個(gè)Topic包含一個(gè)或多個(gè)Partition.Producer
負(fù)責(zé)發(fā)布消息到Kafka brokerConsumer
消息消費(fèi)者,向Kafka broker讀取消息的客戶端。Consumer Group
每個(gè)Consumer屬于一個(gè)特定的Consumer Group(可為每個(gè)Consumer指定group name,若不指定group name則屬于默認(rèn)的group)。
9.框架認(rèn)識(shí)
Kafka是分布式發(fā)布-訂閱消息系統(tǒng)。它最初由LinkedIn公司開(kāi)發(fā),之后成為Apache項(xiàng)目的一部分。Kafka是一個(gè)分布式的,可劃分的,冗余備份的持久性的日志服務(wù)。它主要用于處理活躍的流式數(shù)據(jù)。
在大數(shù)據(jù)系統(tǒng)中,常常會(huì)碰到一個(gè)問(wèn)題,整個(gè)大數(shù)據(jù)是由各個(gè)子系統(tǒng)組成,數(shù)據(jù)需要在各個(gè)子系統(tǒng)中高性能,低延遲的不停流轉(zhuǎn)。傳統(tǒng)的企業(yè)消息系統(tǒng)并不是非常適合大規(guī)模的數(shù)據(jù)處理。為了已在同時(shí)搞定在線應(yīng)用(消息)和離線應(yīng)用(數(shù)據(jù)文件,日志)Kafka就出現(xiàn)了。Kafka可以起到兩個(gè)作用:
降低系統(tǒng)組網(wǎng)復(fù)雜度。
降低編程復(fù)雜度,各個(gè)子系統(tǒng)不在是相互協(xié)商接口,各個(gè)子系統(tǒng)類似插口插在插座上,Kafka承擔(dān)高速數(shù)據(jù)總線的作用。
10.框架特點(diǎn)
同時(shí)為發(fā)布和訂閱提供高吞吐量。據(jù)了解,Kafka每秒可以生產(chǎn)約25萬(wàn)消息(50 MB),每秒處理55萬(wàn)消息(110 MB)。
可進(jìn)行持久化操作。將消息持久化到磁盤(pán),因此可用于批量消費(fèi),例如ETL,以及實(shí)時(shí)應(yīng)用程序。通過(guò)將數(shù)據(jù)持久化到硬盤(pán)以及replication防止數(shù)據(jù)丟失。
分布式系統(tǒng),易于向外擴(kuò)展。所有的producer、broker和consumer都會(huì)有多個(gè),均為分布式的。無(wú)需停機(jī)即可擴(kuò)展機(jī)器。
消息被處理的狀態(tài)是在consumer端維護(hù),而不是由server端維護(hù)。當(dāng)失敗時(shí)能自動(dòng)平衡。
支持online和offline的場(chǎng)景。
12.Kafka拓?fù)浣Y(jié)構(gòu)
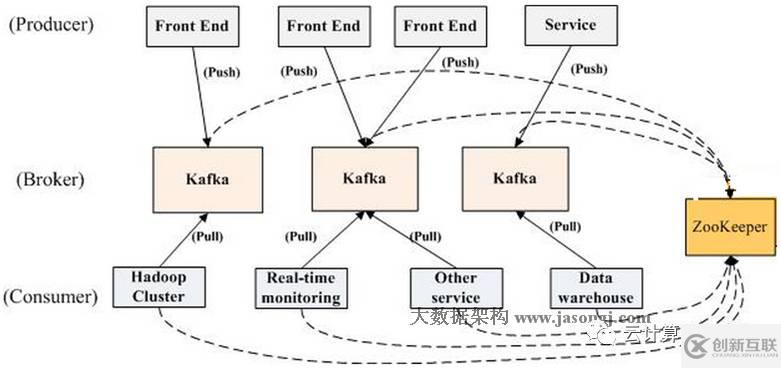
如上圖所示,一個(gè)典型的Kafka集群中包含若干Producer(可以是web前端產(chǎn)生的Page View,或者是服務(wù)器日志,系統(tǒng)CPU、Memory等),若干broker(Kafka支持水平擴(kuò)展,一般broker數(shù)量越多,集群吞吐率越高),若干Consumer Group,以及一個(gè)Zookeeper集群。Kafka通過(guò)Zookeeper管理集群配置,選舉leader,以及在Consumer Group發(fā)生變化時(shí)進(jìn)行rebalance。Producer使用push模式將消息發(fā)布到broker,Consumer使用pull模式從broker訂閱并消費(fèi)消息。
13.Kafka的設(shè)計(jì)
1、吞吐量
高吞吐是kafka需要實(shí)現(xiàn)的核心目標(biāo)之一,為此kafka做了以下一些設(shè)計(jì):
數(shù)據(jù)磁盤(pán)持久化:消息不在內(nèi)存中cache,直接寫(xiě)入到磁盤(pán),充分利用磁盤(pán)的順序讀寫(xiě)性能
zero-copy:減少I(mǎi)O操作步驟
數(shù)據(jù)批量發(fā)送
數(shù)據(jù)壓縮
Topic劃分為多個(gè)partition,提高parallelism
producer根據(jù)用戶指定的算法,將消息發(fā)送到指定的partition
存在多個(gè)partiiton,每個(gè)partition有自己的replica,每個(gè)replica分布在不同的Broker節(jié)點(diǎn)上
多個(gè)partition需要選取出lead partition,lead partition負(fù)責(zé)讀寫(xiě),并由zookeeper負(fù)責(zé)fail over
通過(guò)zookeeper管理broker與consumer的動(dòng)態(tài)加入與離開(kāi)
拉取系統(tǒng)
由于kafka broker會(huì)持久化數(shù)據(jù),broker沒(méi)有內(nèi)存壓力,因此,consumer非常適合采取pull的方式消費(fèi)數(shù)據(jù),具有以下幾點(diǎn)好處:
簡(jiǎn)化kafka設(shè)計(jì)
consumer根據(jù)消費(fèi)能力自主控制消息拉取速度
consumer根據(jù)自身情況自主選擇消費(fèi)模式,例如批量,重復(fù)消費(fèi),從尾端開(kāi)始消費(fèi)等
可擴(kuò)展性
當(dāng)需要增加broker結(jié)點(diǎn)時(shí),新增的broker會(huì)向zookeeper注冊(cè),而producer及consumer會(huì)根據(jù)注冊(cè)在zookeeper上的watcher感知這些變化,并及時(shí)作出調(diào)整。
Kafka的應(yīng)用場(chǎng)景
1.消息隊(duì)列
比起大多數(shù)的消息系統(tǒng)來(lái)說(shuō),Kafka有更好的吞吐量,內(nèi)置的分區(qū),冗余及容錯(cuò)性,這讓Kafka成為了一個(gè)很好的大規(guī)模消息處理應(yīng)用的解決方案。消息系統(tǒng)一般吞吐量相對(duì)較低,但是需要更小的端到端延時(shí),并嘗嘗依賴于Kafka提供的強(qiáng)大的持久性保障。在這個(gè)領(lǐng)域,Kafka足以媲美傳統(tǒng)消息系統(tǒng),如ActiveMR或RabbitMQ。
2.行為跟蹤
Kafka的另一個(gè)應(yīng)用場(chǎng)景是跟蹤用戶瀏覽頁(yè)面、搜索及其他行為,以發(fā)布-訂閱的模式實(shí)時(shí)記錄到對(duì)應(yīng)的topic里。那么這些結(jié)果被訂閱者拿到后,就可以做進(jìn)一步的實(shí)時(shí)處理,或?qū)崟r(shí)監(jiān)控,或放到Hadoop/離線數(shù)據(jù)倉(cāng)庫(kù)里處理。
3.元信息監(jiān)控
作為操作記錄的監(jiān)控模塊來(lái)使用,即匯集記錄一些操作信息,可以理解為運(yùn)維性質(zhì)的數(shù)據(jù)監(jiān)控吧。
4.日志收集
日志收集方面,其實(shí)開(kāi)源產(chǎn)品有很多,包括Scribe、Apache Flume。很多人使用Kafka代替日志聚合(log aggregation)。日志聚合一般來(lái)說(shuō)是從服務(wù)器上收集日志文件,然后放到一個(gè)集中的位置(文件服務(wù)器或HDFS)進(jìn)行處理。然而Kafka忽略掉文件的細(xì)節(jié),將其更清晰地抽象成一個(gè)個(gè)日志或事件的消息流。這就讓Kafka處理過(guò)程延遲更低,更容易支持多數(shù)據(jù)源和分布式數(shù)據(jù)處理。比起以日志為中心的系統(tǒng)比如Scribe或者Flume來(lái)說(shuō),Kafka提供同樣高效的性能和因?yàn)閺?fù)制導(dǎo)致的更高的耐用性保證,以及更低的端到端延遲。
5.流處理
這個(gè)場(chǎng)景可能比較多,也很好理解。保存收集流數(shù)據(jù),以提供之后對(duì)接的Storm或其他流式計(jì)算框架進(jìn)行處理。很多用戶會(huì)將那些從原始topic來(lái)的數(shù)據(jù)進(jìn)行階段性處理,匯總,擴(kuò)充或者以其他的方式轉(zhuǎn)換到新的topic下再繼續(xù)后面的處理。例如一個(gè)文章推薦的處理流程,可能是先從RSS數(shù)據(jù)源中抓取文章的內(nèi)容,然后將其丟入一個(gè)叫做“文章”的topic中;后續(xù)操作可能是需要對(duì)這個(gè)內(nèi)容進(jìn)行清理,比如回復(fù)正常數(shù)據(jù)或者刪除重復(fù)數(shù)據(jù),最后再將內(nèi)容匹配的結(jié)果返還給用戶。這就在一個(gè)獨(dú)立的topic之外,產(chǎn)生了一系列的實(shí)時(shí)數(shù)據(jù)處理的流程。Strom和Samza是非常著名的實(shí)現(xiàn)這種類型數(shù)據(jù)轉(zhuǎn)換的框架。
6.事件源
事件源是一種應(yīng)用程序設(shè)計(jì)的方式,該方式的狀態(tài)轉(zhuǎn)移被記錄為按時(shí)間順序排序的記錄序列。Kafka可以存儲(chǔ)大量的日志數(shù)據(jù),這使得它成為一個(gè)對(duì)這種方式的應(yīng)用來(lái)說(shuō)絕佳的后臺(tái)。比如動(dòng)態(tài)匯總(News feed)。
7.持久性日志(commit log)
Kafka可以為一種外部的持久性日志的分布式系統(tǒng)提供服務(wù)。這種日志可以在節(jié)點(diǎn)間備份數(shù)據(jù),并為故障節(jié)點(diǎn)數(shù)據(jù)回復(fù)提供一種重新同步的機(jī)制。Kafka中日志壓縮功能為這種用法提供了條件。在這種用法中,Kafka類似于Apache BookKeeper項(xiàng)目。
上述就是小編為大家分享的kafka分析與單機(jī)使用記錄是怎樣的了,如果剛好有類似的疑惑,不妨參照上述分析進(jìn)行理解。如果想知道更多相關(guān)知識(shí),歡迎關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道。
當(dāng)前題目:kafka分析與單機(jī)使用記錄是怎樣的
文章源于:http://www.chinadenli.net/article36/jigdpg.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站策劃、App開(kāi)發(fā)、網(wǎng)站建設(shè)、App設(shè)計(jì)、建站公司、營(yíng)銷(xiāo)型網(wǎng)站建設(shè)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)

- 電商APP軟件開(kāi)發(fā)應(yīng)如何選擇軟件開(kāi)發(fā)公司? 2020-11-13
- 上海理財(cái)APP軟件開(kāi)發(fā)需要多少錢(qián)? 2020-11-29
- 如何判斷免費(fèi)自助建站軟件開(kāi)發(fā)商是否值得選擇 2017-06-20
- 成都軟件開(kāi)發(fā)公司哪家好?如何選擇? 2020-08-21
- 影響APP軟件開(kāi)發(fā)質(zhì)量的關(guān)鍵是什么 2022-06-08
- 學(xué)軟件開(kāi)發(fā)很難嗎?大神帶你快速學(xué)會(huì)數(shù)據(jù)結(jié)構(gòu)與算法! 2016-08-30
- 初學(xué)Java軟件開(kāi)發(fā),須熟練掌握的核心技術(shù) 2016-08-17
- 物聯(lián)網(wǎng)為軟件開(kāi)發(fā)帶來(lái)的7大啟示! 2016-08-29
- 安卓APP軟件開(kāi)發(fā)大概需要多少錢(qián)? 2020-11-30
- 學(xué)習(xí)軟件開(kāi)發(fā)技術(shù)是否有前景以及需要注意哪些因素 2021-06-10
- 教育軟件開(kāi)發(fā)之微信公眾號(hào)的好處 2016-08-23
- APP軟件開(kāi)發(fā)如何滿足用戶的需求 2016-08-13