5種JVM垃圾收集器特點和8種JVM內(nèi)存溢出原因
先來看看5種JVM垃圾收集器特點
10年積累的網(wǎng)站制作、做網(wǎng)站經(jīng)驗,可以快速應對客戶對網(wǎng)站的新想法和需求。提供各種問題對應的解決方案。讓選擇我們的客戶得到更好、更有力的網(wǎng)絡服務。我雖然不認識你,你也不認識我。但先網(wǎng)站策劃后付款的網(wǎng)站建設流程,更有剛察免費網(wǎng)站建設讓你可以放心的選擇與我們合作。
一、常見垃圾收集器
現(xiàn)在常見的垃圾收集器有如下幾種:
新生代收集器:
Serial
ParNew
Parallel Scavenge
老年代收集器:
Serial Old
CMS
Parallel Old
堆內(nèi)存垃圾收集器:G1
每種垃圾收集器之間有連線,表示他們可以搭配使用。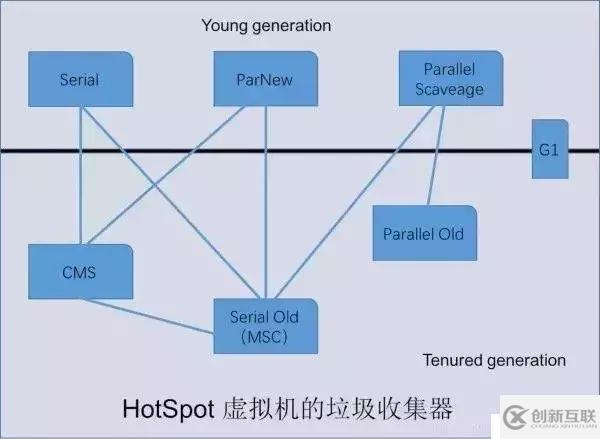
二、新生代垃圾收集器
(1)Serial 收集器
Serial 是一款用于新生代的單線程收集器,采用復制算法進行垃圾收集。Serial 進行垃圾收集時,不僅只用一條線程執(zhí)行垃圾收集工作,它在收集的同時,所有的用戶線程必須暫停(Stop The World)。
就比如媽媽在家打掃衛(wèi)生的時候,肯定不會邊打掃邊讓兒子往地上亂扔紙屑,否則一邊制造垃圾,一遍清理垃圾,這活啥時候也干不完。
如下是 Serial 收集器和 Serial Old 收集器結(jié)合進行垃圾收集的示意圖,當用戶線程都執(zhí)行到安全點時,所有線程暫停執(zhí)行,Serial 收集器以單線程,采用復制算法進行垃圾收集工作,收集完之后,用戶線程繼續(xù)開始執(zhí)行。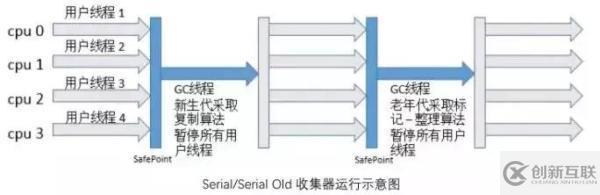
適用場景:Client 模式(桌面應用);單核服務器。
可以用 -XX:+UserSerialGC 來選擇 Serial 作為新生代收集器。
(2)ParNew 收集器
ParNew 就是一個 Serial 的多線程版本,其它與Serial并無區(qū)別。ParNew 在單核 CPU 環(huán)境并不會比 Serial 收集器達到更好的效果,它默認開啟的收集線程數(shù)和 CPU 數(shù)量一致,可以通過 -XX:ParallelGCThreads 來設置垃圾收集的線程數(shù)。
如下是 ParNew 收集器和 Serial Old 收集器結(jié)合進行垃圾收集的示意圖,當用戶線程都執(zhí)行到安全點時,所有線程暫停執(zhí)行,ParNew 收集器以多線程,采用復制算法進行垃圾收集工作,收集完之后,用戶線程繼續(xù)開始執(zhí)行。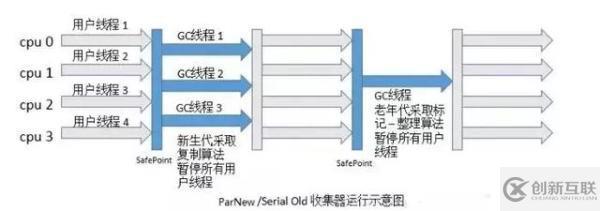
適用場景:多核服務器;與 CMS 收集器搭配使用。當使用 -XX:+UserConcMarkSweepGC 來選擇 CMS 作為老年代收集器時,新生代收集器默認就是 ParNew,也可以用 -XX:+UseParNewGC 來指定使用 ParNew 作為新生代收集器。
(3)Parallel Scavenge 收集器
Parallel Scavenge 也是一款用于新生代的多線程收集器,與 ParNew 的不同之處是ParNew 的目標是盡可能縮短垃圾收集時用戶線程的停頓時間,Parallel Scavenge 的目標是達到一個可控制的吞吐量。
吞吐量就是 CPU 執(zhí)行用戶線程的的時間與 CPU 執(zhí)行總時間的比值【吞吐量 = 運行用戶代代碼時間/(運行用戶代碼時間+垃圾收集時間)】,比如虛擬機一共運行了 100 分鐘,其中垃圾收集花費了 1 分鐘,那吞吐量就是 99% 。比如下面兩個場景,垃圾收集器每 100 秒收集一次,每次停頓 10 秒,和垃圾收集器每 50 秒收集一次,每次停頓時間 7 秒,雖然后者每次停頓時間變短了,但是總體吞吐量變低了,CPU 總體利用率變低了。
可以通過 -XX:MaxGCPauseMillis 來設置收集器盡可能在多長時間內(nèi)完成內(nèi)存回收,可以通過 -XX:GCTimeRatio 來精確控制吞吐量。
如下是 Parallel 收集器和 Parallel Old 收集器結(jié)合進行垃圾收集的示意圖,在新生代,當用戶線程都執(zhí)行到安全點時,所有線程暫停執(zhí)行,ParNew 收集器以多線程,采用復制算法進行垃圾收集工作,收集完之后,用戶線程繼續(xù)開始執(zhí)行;在老年代,當用戶線程都執(zhí)行到安全點時,所有線程暫停執(zhí)行,Parallel Old 收集器以多線程,采用標記整理算法進行垃圾收集工作。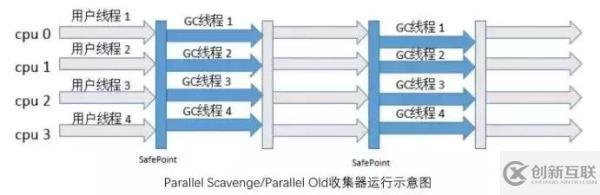
適用場景:注重吞吐量,高效利用 CPU,需要高效運算且不需要太多交互。
可以使用 -XX:+UseParallelGC 來選擇 Parallel Scavenge 作為新生代收集器,jdk7、jdk8 默認使用 Parallel Scavenge 作為新生代收集器。
三、老年代垃圾收集器
(1)Serial Old 收集器
Serial Old 收集器是 Serial 的老年代版本,同樣是一個單線程收集器,采用標記-整理算法。
如下圖是 Serial 收集器和 Serial Old 收集器結(jié)合進行垃圾收集的示意圖: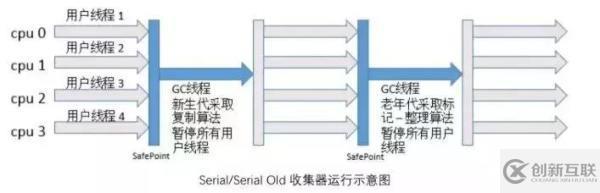
適用場景:Client 模式(桌面應用);單核服務器;與 Parallel Scavenge 收集器搭配;作為 CMS 收集器的后備預案。
(2)CMS(Concurrent Mark Sweep) 收集器
CMS 收集器是一種以最短回收停頓時間為目標的收集器,以 “ 最短用戶線程停頓時間 ” 著稱。整個垃圾收集過程分為 4 個步驟:
① 初始標記:標記一下 GC Roots 能直接關(guān)聯(lián)到的對象,速度較快。
② 并發(fā)標記:進行 GC Roots Tracing,標記出全部的垃圾對象,耗時較長。
③ 重新標記:修正并發(fā)標記階段引用戶程序繼續(xù)運行而導致變化的對象的標記記錄,耗時較短。
④ 并發(fā)清除:用標記-清除算法清除垃圾對象,耗時較長。
整個過程耗時最長的并發(fā)標記和并發(fā)清除都是和用戶線程一起工作,所以從總體上來說,CMS 收集器垃圾收集可以看做是和用戶線程并發(fā)執(zhí)行的。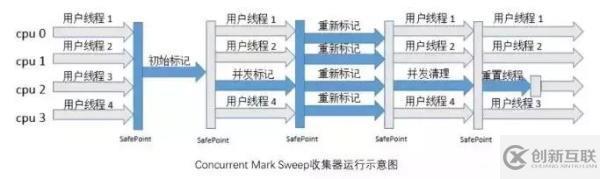
CMS 收集器也存在一些缺點:
對 CPU 資源敏感:默認分配的垃圾收集線程數(shù)為(CPU 數(shù)+3)/4,隨著 CPU 數(shù)量下降,占用 CPU 資源越多,吞吐量越小
無法處理浮動垃圾:在并發(fā)清理階段,由于用戶線程還在運行,還會不斷產(chǎn)生新的垃圾,CMS 收集器無法在當次收集中清除這部分垃圾。同時由于在垃圾收集階段用戶線程也在并發(fā)執(zhí)行,CMS 收集器不能像其他收集器那樣等老年代被填滿時再進行收集,需要預留一部分空間提供用戶線程運行使用。當 CMS 運行時,預留的內(nèi)存空間無法滿足用戶線程的需要,就會出現(xiàn) “ Concurrent Mode Failure ”的錯誤,這時將會啟動后備預案,臨時用 Serial Old 來重新進行老年代的垃圾收集。
因為 CMS 是基于標記-清除算法,所以垃圾回收后會產(chǎn)生空間碎片,可以通過 -XX:UserCMSCompactAtFullCollection 開啟碎片整理(默認開啟),在 CMS 進行 Full GC 之前,會進行內(nèi)存碎片的整理。還可以用 -XX:CMSFullGCsBeforeCompaction 設置執(zhí)行多少次不壓縮(不進行碎片整理)的 Full GC 之后,跟著來一次帶壓縮(碎片整理)的 Full GC。
適用場景:重視服務器響應速度,要求系統(tǒng)停頓時間最短。可以使用 -XX:+UserConMarkSweepGC 來選擇 CMS 作為老年代收集器。
(3)Parallel Old 收集器
Parallel Old 收集器是 Parallel Scavenge 的老年代版本,是一個多線程收集器,采用標記-整理算法。可以與 Parallel Scavenge 收集器搭配,可以充分利用多核 CPU 的計算能力。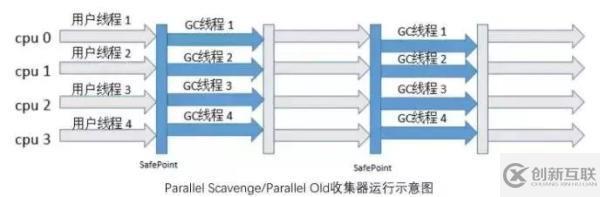
適用場景:與Parallel Scavenge 收集器搭配使用;注重吞吐量。jdk7、jdk8 默認使用該收集器作為老年代收集器,使用 -XX:+UseParallelOldGC 來指定使用 Paralle Old 收集器。
四、新生代和老年代垃圾收集器
G1 收集器
G1 收集器是 jdk1.7 才正式引用的商用收集器,現(xiàn)在已經(jīng)成為 jdk9 默認的收集器。前面幾款收集器收集的范圍都是新生代或者老年代,G1 進行垃圾收集的范圍是整個堆內(nèi)存,它采用 “ 化整為零 ” 的思路,把整個堆內(nèi)存劃分為多個大小相等的獨立區(qū)域(Region),在 G1 收集器中還保留著新生代和老年代的概念,它們分別都是一部分 Region,如下圖: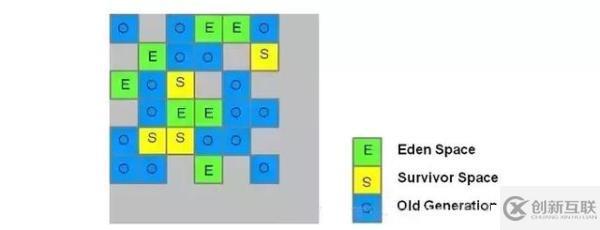
每一個方塊就是一個區(qū)域,每個區(qū)域可能是 Eden、Survivor、老年代,每種區(qū)域的數(shù)量也不一定。JVM 啟動時會自動設置每個區(qū)域的大小(1M ~ 32M,必須是 2 的次冪),最多可以設置 2048 個區(qū)域(即支持的最大堆內(nèi)存為 32M*2048 = 64G),假如設置 -Xmx8g -Xms8g,則每個區(qū)域大小為 8g/2048=4M。
為了在 GC Roots Tracing 的時候避免掃描全堆,在每個 Region 中,都有一個 Remembered Set 來實時記錄該區(qū)域內(nèi)的引用類型數(shù)據(jù)與其他區(qū)域數(shù)據(jù)的引用關(guān)系(在前面的幾款分代收集中,新生代、老年代中也有一個 Remembered Set 來實時記錄與其他區(qū)域的引用關(guān)系),在標記時直接參考這些引用關(guān)系就可以知道這些對象是否應該被清除,而不用掃描全堆的數(shù)據(jù)。
G1 收集器可以 “ 建立可預測的停頓時間模型 ”,它維護了一個列表用于記錄每個 Region 回收的價值大小(回收后獲得的空間大小以及回收所需時間的經(jīng)驗值),這樣可以保證 G1 收集器在有限的時間內(nèi)可以獲得最大的回收效率。
如下圖所示,G1 收集器收集器收集過程有初始標記、并發(fā)標記、最終標記、篩選回收,和 CMS 收集器前幾步的收集過程很相似: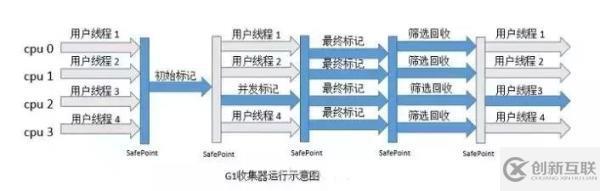
① 初始標記:標記出 GC Roots 直接關(guān)聯(lián)的對象,這個階段速度較快,需要停止用戶線程,單線程執(zhí)行。
② 并發(fā)標記:從 GC Root 開始對堆中的對象進行可達新分析,找出存活對象,這個階段耗時較長,但可以和用戶線程并發(fā)執(zhí)行。
③ 最終標記:修正在并發(fā)標記階段引用戶程序執(zhí)行而產(chǎn)生變動的標記記錄。
④ 篩選回收:篩選回收階段會對各個 Region 的回收價值和成本進行排序,根據(jù)用戶所期望的 GC 停頓時間來指定回收計劃(用最少的時間來回收包含垃圾最多的區(qū)域,這就是 Garbage First 的由來——第一時間清理垃圾最多的區(qū)塊),這里為了提高回收效率,并沒有采用和用戶線程并發(fā)執(zhí)行的方式,而是停頓用戶線程。
適用場景:要求盡可能可控 GC 停頓時間;內(nèi)存占用較大的應用。可以用 -XX:+UseG1GC 使用 G1 收集器,jdk9 默認使用 G1 收集器。
五、JVM垃圾收集器總結(jié)
本文主要介紹了JVM中的垃圾回收器,主要包括串行回收器、并行回收器以及CMS回收器、G1回收器。他們各自都有優(yōu)缺點,通常來說你需要根據(jù)你的業(yè)務,進行基于垃圾回收器的性能測試,然后再做選擇。下面給出配置回收器時,經(jīng)常使用的參數(shù):
-XX:+UseSerialGC:在新生代和老年代使用串行收集器
-XX:+UseParNewGC:在新生代使用并行收集器
-XX:+UseParallelGC :新生代使用并行回收收集器,更加關(guān)注吞吐量
-XX:+UseParallelOldGC:老年代使用并行回收收集器
-XX:ParallelGCThreads:設置用于垃圾回收的線程數(shù)
-XX:+UseConcMarkSweepGC:新生代使用并行收集器,老年代使用CMS+串行收集器
-XX:ParallelCMSThreads:設定CMS的線程數(shù)量
-XX:+UseG1GC:啟用G1垃圾回收器

接下來看看8種JVM內(nèi)存溢出原因
一. Java 堆空間
發(fā)生頻率:5顆星
造成原因
無法在 Java 堆中分配對象
吞吐量增加
應用程序無意中保存了對象引用,對象無法被 GC 回收
應用程序過度使用 finalizer。finalizer 對象不能被 GC 立刻回收。finalizer 由結(jié)束隊列服務的守護線程調(diào)用,有時 finalizer 線程的處理能力無法跟上結(jié)束隊列的增長
解決方案
使用 -Xmx 增加堆大小
修復應用程序中的內(nèi)存泄漏
二. GC 開銷超過限制
發(fā)生頻率:5顆星
造成原因
Java 進程98%的時間在進行垃圾回收,恢復了不到2%的堆空間,最后連續(xù)5個(編譯時常量)垃圾回收一直如此。
解決方案
使用 -Xmx 增加堆大小
使用 -XX:-UseGCOverheadLimit 取消 GC 開銷限制
修復應用程序中的內(nèi)存泄漏
三. 請求的數(shù)組大小超過虛擬機限制
發(fā)生頻率:2顆星
造成原因
應用程序試圖分配一個超過堆大小的數(shù)組
解決方案
使用 -Xmx 增加堆大小
修復應用程序中分配巨大數(shù)組的 bug
四. Perm gen 空間
發(fā)生頻率:3顆星
造成原因
Perm gen 空間包含:
類的名字、字段、方法
與類相關(guān)的對象數(shù)組和類型數(shù)組
JIT 編譯器優(yōu)化
當 Perm gen 空間用盡時,將拋出異常。
解決方案
使用 -XX: MaxPermSize 增加 Permgen 大小
不重啟應用部署應用程序可能會導致此問題。重啟 JVM 解決
五. Metaspace
發(fā)生頻率:3顆星
造成原因
從 Java 8 開始 Perm gen 改成了 Metaspace,在本機內(nèi)存中分配 class 元數(shù)據(jù)(稱為 metaspace)。如果 metaspace 耗盡,則拋出異常
解決方案
通過命令行設置 -XX: MaxMetaSpaceSize 增加 metaspace 大小
取消 -XX: maxmetsspacedize
減小 Java 堆大小,為 MetaSpace 提供更多的可用空間
為服務器分配更多的內(nèi)存
可能是應用程序 bug,修復 bug
六. 無法新建本機線程
發(fā)生頻率:5顆星
造成原因
內(nèi)存不足,無法創(chuàng)建新線程。由于線程在本機內(nèi)存中創(chuàng)建,報告這個錯誤表明本機內(nèi)存空間不足
解決方案
為機器分配更多的內(nèi)存
減少 Java 堆空間
修復應用程序中的線程泄漏。
增加操作系統(tǒng)級別的限制
ulimit -a
用戶進程數(shù)增大 (-u) 1800
使用 -Xss 減小線程堆棧大小
七. 殺死進程或子進程
發(fā)生頻率:1顆星
造成原因
內(nèi)核任務:內(nèi)存不足結(jié)束器,在可用內(nèi)存極低的情況下會殺死進程
解決方案
將進程遷移到不同的機器上
給機器增加更多內(nèi)存
與其他 OOM 錯誤不同,這是由操作系統(tǒng)而非 JVM 觸發(fā)的。
八. 發(fā)生 stack_trace_with_native_method
發(fā)生頻率:1顆星
造成原因
本機方法(native method)分配失敗
打印的堆棧跟蹤信息,最頂層的幀是本機方法
解決方案
使用操作系統(tǒng)本地工具進行診斷
最后
歡迎大家一起交流,喜歡文章記得點個贊喲,感謝支持!
網(wǎng)站題目:5種JVM垃圾收集器特點和8種JVM內(nèi)存溢出原因
鏈接地址:http://www.chinadenli.net/article34/iijose.html
成都網(wǎng)站建設公司_創(chuàng)新互聯(lián),為您提供做網(wǎng)站、虛擬主機、網(wǎng)站改版、域名注冊、關(guān)鍵詞優(yōu)化、網(wǎng)站導航
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)

- 網(wǎng)站建設公司如何與客戶溝通 2021-09-29
- 成都網(wǎng)站建設制作布局 2016-09-05
- 物流網(wǎng)站建設解決方案與行業(yè)市場現(xiàn)狀 2014-02-26
- 影響營銷型網(wǎng)站建設成功與否的因素都有哪些 2022-05-01
- 成都網(wǎng)站建設淺析網(wǎng)站建設和企業(yè)品牌之間的關(guān)系 2022-11-14
- 成都網(wǎng)站建設談如何建設高端網(wǎng)站 2016-11-02
- 創(chuàng)新互聯(lián):門戶網(wǎng)站建設中應注意的問題 2022-11-17
- 深圳網(wǎng)站建設公司|網(wǎng)站優(yōu)化推廣的手段有哪些? 2021-11-21
- 衡量網(wǎng)站建設用戶體驗有四個主要因素 2022-06-02
- 專業(yè)網(wǎng)站建設要做到以下五點 2016-11-05
- 做策劃對網(wǎng)站建設的作用 2022-05-30
- 什么類型的廣州網(wǎng)站建設有利于排名? 2022-12-15