Python基于pandas如何爬取網頁表格數據-創(chuàng)新互聯
這篇文章主要講解了Python基于pandas如何爬取網頁表格數據,內容清晰明了,對此有興趣的小伙伴可以學習一下,相信大家閱讀完之后會有幫助。

該網站數據存在table標簽,直接用requests,需要結合bs4解析正則/xpath/lxml等,沒有幾行代碼是搞不定的。
今天介紹的黑科技是pandas自帶爬蟲功能,pd.read_html(),只需傳人url,一行代碼搞定。
原網頁結構如下:
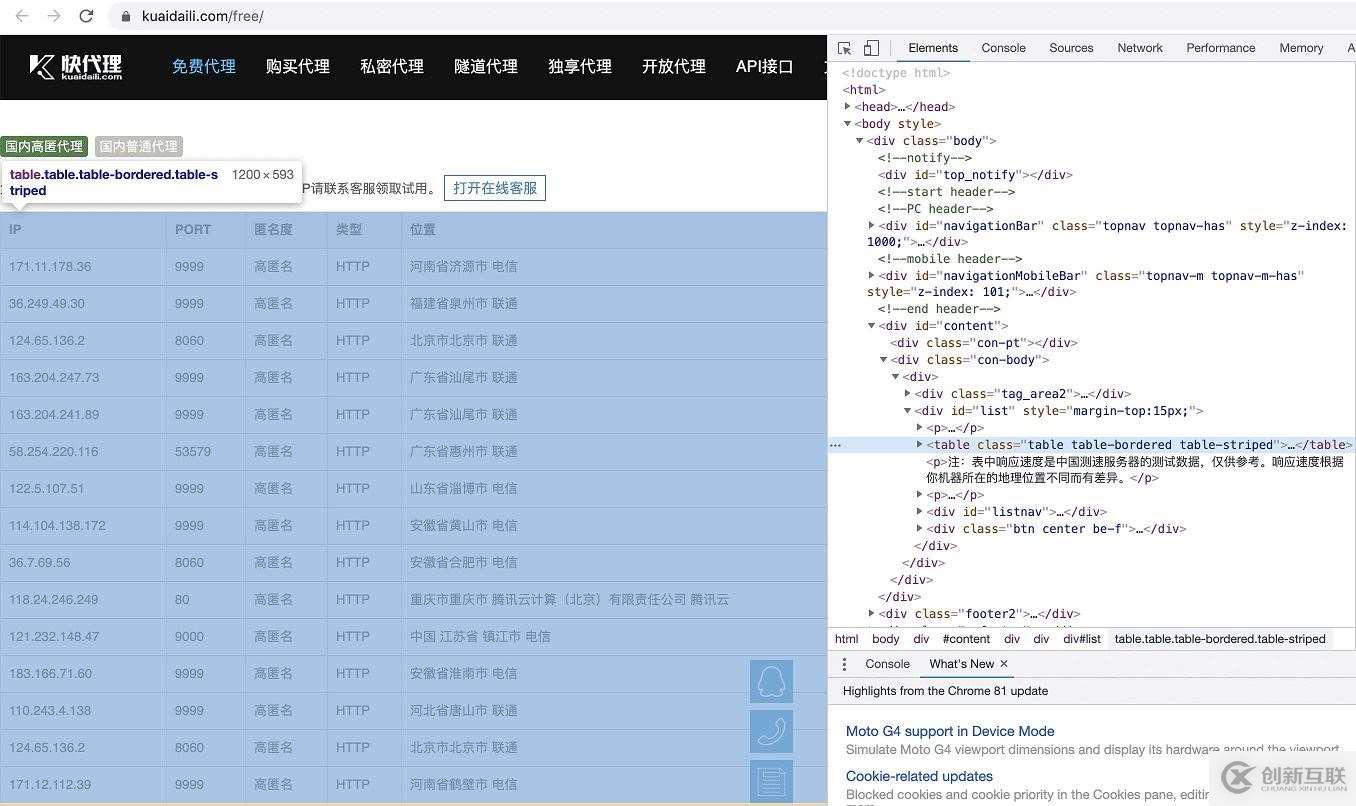
python代碼如下:
import pandas as pd url='http://www.kuaidaili.com/free/' df=pd.read_html(url)[0] # [0]:表示第一個table,多個table需要指定,如果不指定默認第一個 # 如果沒有【0】,輸入dataframe格式組成的list df
另外有需要云服務器可以了解下創(chuàng)新互聯scvps.cn,海內外云服務器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務器、裸金屬服務器、高防服務器、香港服務器、美國服務器、虛擬主機、免備案服務器”等云主機租用服務以及企業(yè)上云的綜合解決方案,具有“安全穩(wěn)定、簡單易用、服務可用性高、性價比高”等特點與優(yōu)勢,專為企業(yè)上云打造定制,能夠滿足用戶豐富、多元化的應用場景需求。
新聞標題:Python基于pandas如何爬取網頁表格數據-創(chuàng)新互聯
網站地址:http://www.chinadenli.net/article30/dgeiso.html
成都網站建設公司_創(chuàng)新互聯,為您提供品牌網站制作、全網營銷推廣、電子商務、網站策劃、小程序開發(fā)、品牌網站建設
聲明:本網站發(fā)布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創(chuàng)新互聯
- 教你如何快速的購買適用的阿里云云服務器ECS 2023-02-16
- 網站維護,網站為何要做維護?云服務器租賃 2021-08-13
- 傳奇云服務器租用應該考慮哪些因素? 2022-10-06
- 為什么獨立ip的云服務器價格比較貴? 2022-10-04
- 高防云服務器有何優(yōu)勢?適用于哪些場景? 2022-10-06
- 企業(yè)開進行網站建設,如何購買合適的云服務器 2022-11-06
- 傳統服務器和和云服務器的區(qū)別 2022-06-21
- 云服務器具備怎樣的優(yōu)勢 2022-10-07
- 虛擬主機、VPS主機、云服務器有什么區(qū)別,哪個更好? 2017-01-04
- 云服務器與傳統服務器之間有什么區(qū)別 2021-02-03
- 淺談物理服務器與云服務器的區(qū)別 2022-10-06
- 云服務器和vps有什么區(qū)別嗎 2016-10-18