萬(wàn)字長(zhǎng)文:ELK(V7)部署與架構(gòu)分析-創(chuàng)新互聯(lián)
作者:秦偉

1.ELK的背景介紹與應(yīng)用場(chǎng)景
在項(xiàng)目應(yīng)用運(yùn)行的過(guò)程中,往往會(huì)產(chǎn)生大量的日志,我們往往需要根據(jù)日志來(lái)定位分析我們的服務(wù)器項(xiàng)目運(yùn)行情況與BUG產(chǎn)生位置。一般情況下直接在日志文件中tailf、 grep、awk 就可以獲得自己想要的信息。但在規(guī)模較大的場(chǎng)景中,此方法效率低下,面臨問(wèn)題包括日志量過(guò)大、文本搜索太慢、如何多維度查詢。這就需要對(duì)服務(wù)器上的日志收集匯總。常見(jiàn)解決思路是建立集中式日志收集系統(tǒng),將所有節(jié)點(diǎn)上的日志統(tǒng)一收集,管理,訪問(wèn)。
一般大型系統(tǒng)往往是一種分布式部署的架構(gòu),不同的服務(wù)模塊部署在不同的服務(wù)器上,問(wèn)題出現(xiàn)時(shí),大部分情況需要根據(jù)問(wèn)題暴露的關(guān)鍵信息,定位到具體的服務(wù)器和服務(wù)模塊,所以構(gòu)建一套集中式日志系統(tǒng),可以提高定位問(wèn)題的效率。一個(gè)完整的集中式日志系統(tǒng),需要包含以下幾個(gè)主要特點(diǎn):
收集-能夠采集多種來(lái)源的日志數(shù)據(jù),服務(wù)日志與系統(tǒng)日志。
傳輸-能夠穩(wěn)定的把日志數(shù)據(jù)傳輸?shù)街醒胂到y(tǒng)
存儲(chǔ)-如何存儲(chǔ)日志數(shù)據(jù),持久化數(shù)據(jù)。
分析-可以支持 UI 分析,界面化定制查看日志操作。
ELK提供了一整套解決方案,并且都是開(kāi)源軟件,之間互相配合使用,完美銜接,高效的滿足了很多場(chǎng)合的應(yīng)用。是目前主流的一種日志系統(tǒng)。
2.ELK簡(jiǎn)介:
ELK是三個(gè)開(kāi)源軟件的縮寫(xiě),分別表示:Elasticsearch, Logstash, Kibana , 它們都是開(kāi)源軟件。其中后來(lái)新增了一個(gè)FileBeat。
即ELK主要由Elasticsearch(搜索)、Logstash(收集與分析)和Kibana(展示)三部分組件組成;
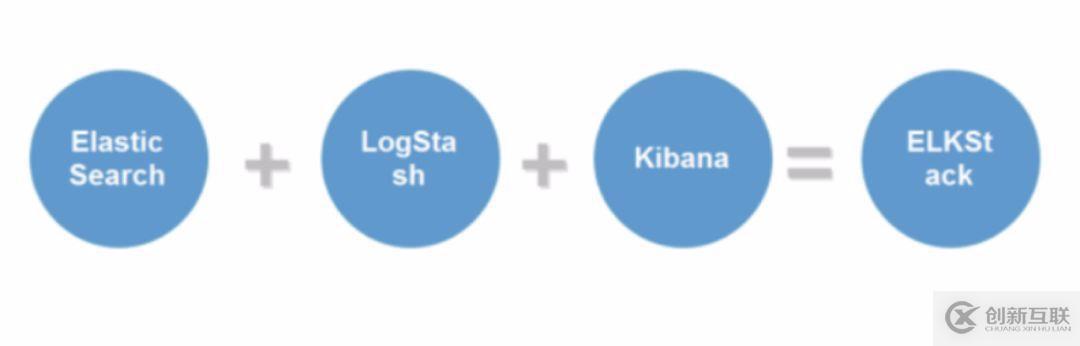
其中各組件說(shuō)明如下:
Filebeat:輕量級(jí)數(shù)據(jù)收集引擎。早期的ELK架構(gòu)中使用Logstash收集、解析日志,但是Logstash對(duì)內(nèi)存、cpu、io等資源消耗比較高。如果用它來(lái)對(duì)服務(wù)器進(jìn)行日志收集,將加重服務(wù)器的負(fù)載。相比 Logstash,Beats所占系統(tǒng)的CPU和內(nèi)存幾乎可以忽略不計(jì),所以filebeat作為一個(gè)輕量級(jí)的日志收集處理工具(Agent),它可以用來(lái)替代Logstash,由于其占用資源少,所以更適合于在各個(gè)服務(wù)器上搜集日志后傳輸給Logstash,這也是官方推薦的一種做法。【收集日志】
Logstash:數(shù)據(jù)收集處理引擎。支持動(dòng)態(tài)的從各種數(shù)據(jù)源搜集數(shù)據(jù),并對(duì)數(shù)據(jù)進(jìn)行過(guò)濾、分析、豐富、統(tǒng)一格式等操作,然后存儲(chǔ)以供后續(xù)使用。【對(duì)日志進(jìn)行過(guò)濾、分析】
Elasticsearch:分布式搜索引擎。是基于Lucene的開(kāi)源分布式搜索服務(wù)器,具有高可伸縮、高可靠、易管理等特點(diǎn)。可以用于全文檢索、結(jié)構(gòu)化檢索和分析,并能將這三者結(jié)合起來(lái)。【搜集、分析、存儲(chǔ)數(shù)據(jù)】
Kibana:可視化平臺(tái)。它能夠搜索、展示存儲(chǔ)在 Elasticsearch 中索引數(shù)據(jù)。使用它可以很方便的用圖表、表格、地圖展示和分析數(shù)據(jù)。【圖形化展示日志】
結(jié)合以上,常見(jiàn)的日志系統(tǒng)架構(gòu)圖如下:
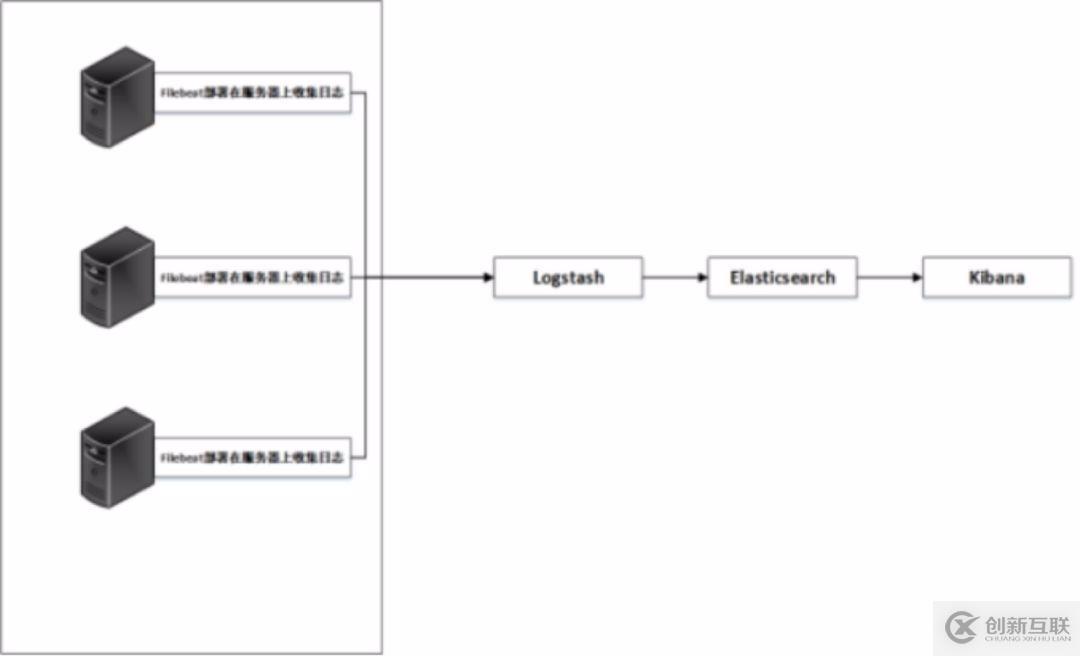
如上圖所示,日志文件分別由filebeat在服務(wù)器上進(jìn)行收集,收集的日志文件匯總到logstash上并對(duì)文件數(shù)據(jù)進(jìn)行過(guò)濾、分析、豐富、統(tǒng)一格式等操作,然后發(fā)送到Elasticsearch,進(jìn)一步對(duì)日志進(jìn)行結(jié)構(gòu)化檢索和分析,并存儲(chǔ)下來(lái),最后由kibana進(jìn)行展示。
這只是日志系統(tǒng)的一種最初級(jí)結(jié)構(gòu),生產(chǎn)環(huán)境中需要對(duì)此結(jié)構(gòu)進(jìn)行進(jìn)一步的優(yōu)化。
3.ELK系統(tǒng)的部署(配置將在生產(chǎn)環(huán)境架構(gòu)中進(jìn)行說(shuō)明)
環(huán)境:CentOS7.5部署ELK 7版本
準(zhǔn)備工作: CentOS7.5
elasticsearch7, logstash7, kibana7
關(guān)閉防火墻和SELinux并更新yum源(非必須):yum -y update
本次分布式部署的ELK版本為2019年五月份左右最新發(fā)布的版本,更新了許多新特性,后面將詳細(xì)說(shuō)明。在安裝上面本次極大簡(jiǎn)化了安裝步驟,可以源碼,組件安裝,本次采用YUM+插件docker安裝,能達(dá)到相同的效果。
3.1Filebeat安裝與配置
#!/bin/bash
安裝Filebeat
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
cat>/etc/yum.repos.d/elk-elasticsearch.repo<<EOF
[elastic-7.x]
name=Elasticrepository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
yum -yinstall filebeat
systemctl enablefilebeat
systemctl startfilebeat
3.2 整套軟件:elasticsearch,Logstash,Kibana和Filebeat的安裝(分開(kāi)部署請(qǐng)分別安裝三個(gè)組件)
- java環(huán)境(7版本自帶Java)
yum -yinstall java - 導(dǎo)入elasticsearch PGP key文件
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch - 配置yum源
vim/etc/yum.repos.d/elasticsearch.repo
[elasticsearch-7.x]
name=Elasticsearchrepository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md - yum -yinstall elasticsearch logstash kibana
##########關(guān)于安裝環(huán)境,也可以參照以下二種方式,也比較簡(jiǎn)便#################
----即通過(guò)RPM包的方式,此處給出Filebeat的方式,其他組件雷同
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.0.0-x86_64.rpm
sudo rpm -vifilebeat-7.0.0-x86_64.rpm
----Logstash實(shí)例另一種方式(優(yōu)先采用)
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.0.0.rpm
yum install -y java
yum install -y logstash-7.0.0.rpm
服務(wù)啟動(dòng)前必看,由于配置文件在下一章節(jié)給出,此處是前提準(zhǔn)備,等配置完成后再啟動(dòng)
3.3 關(guān)于elasticsearch需要重點(diǎn)關(guān)注的地方
1.elasticsearch在分詞方面,需要添加中文分詞的插件。在其安裝代碼的plugins目錄,即/usr/share/elasticsearch/plugins,需要增加中文分詞插件。
[root@192-168-108-35plugins]# ll
total 3192
[root@192-168-108-35 plugins]# pwd
/usr/share/elasticsearch/plugins
[root@192-168-108-35 plugins]# wget https://codeload.github.com/medcl/elasticsearch-analysis-ik/tar.gz/v7.0.0
下載后重啟時(shí)需要?jiǎng)h除插件源文件,否則報(bào)錯(cuò)如下:
Caused by: java.nio.file.FileSystemException:
/usr/share/elasticsearch/plugins/v7.0.0/plugin-descriptor.properties: Not adirectory
所以安裝完成后必須刪除源文件v7.0.0
2.elasticsearch服務(wù)的啟動(dòng)問(wèn)題與前提準(zhǔn)備
-- 首先在安裝完畢后會(huì)生成很多文件,包括配置文件日志文件等等,下面幾個(gè)是最主要的配置文件路徑
/etc/elasticsearch/elasticsearch.yml # els的配置文件
/etc/elasticsearch/jvm.options # JVM相關(guān)的配置,內(nèi)存大小等等
/etc/elasticsearch/log4j2.properties # 日志系統(tǒng)定義
/usr/share/elasticsearch # elasticsearch 默認(rèn)安裝目錄
/var/lib/elasticsearch # 數(shù)據(jù)的默認(rèn)存放位置
-- 創(chuàng)建用于存放數(shù)據(jù)與日志的目錄
數(shù)據(jù)文件會(huì)隨著系統(tǒng)的運(yùn)行飛速增長(zhǎng),所以默認(rèn)的日志文件與數(shù)據(jù)文件的路徑不能滿足我們的需求,那么手動(dòng)創(chuàng)建日志與數(shù)據(jù)文件路徑
mkdir -p /data/elkdata
mkdir -p /data/elklogs
-- JVM配置 (7.0版本針對(duì)此做出優(yōu)化,可以基本保障溢出問(wèn)題,但最好設(shè)置一下)
由于Elasticsearch是Java開(kāi)發(fā)的,所以可以通過(guò)/etc/elasticsearch/jvm.options配置文件來(lái)設(shè)定JVM的相關(guān)設(shè)定。如果沒(méi)有特殊需求按默認(rèn)即可。
不過(guò)其中還是有兩項(xiàng)最重要的-Xmx1g與-Xms1gJVM的大最小內(nèi)存。如果太小會(huì)導(dǎo)致Elasticsearch剛剛啟動(dòng)就立刻停止。太大會(huì)拖慢系統(tǒng)本身。
vim /etc/elasticsearch/jvm.options #JVM大、最小使用內(nèi)存
-Xms1g
-Xmx1g
-- 使用ROOT賬戶執(zhí)行命令
elasticsearch的相關(guān)配置已經(jīng)完成,下面需要啟動(dòng)elasticsearch集群。但是由于安全的考慮,elasticsearch不允許使用root用戶來(lái)啟動(dòng),所以需要?jiǎng)?chuàng)建一個(gè)新的用戶,并為這個(gè)賬戶賦予相應(yīng)的權(quán)限來(lái)啟動(dòng)elasticsearch集群。
創(chuàng)建ES運(yùn)行用戶
創(chuàng)建用戶組 group add elk
創(chuàng)建用戶并添加至用戶組 useradd elk -g elk
(可選)更改用戶密碼
passwd elasticsearch
同時(shí)修改ES目錄權(quán)限,以下操作都是為了賦予es用戶操作權(quán)限
-- 安裝源碼文件目錄
[root@192-168-108-35 share]# chown -R elk :elk/usr/share/elasticsearch/
[root@192-168-108-35 share]# chown -R elk :elk /var/log/elasticsearch/
[root@192-168-108-35 share]# chown -R elk :elk /data
-- 運(yùn)行常見(jiàn)的報(bào)錯(cuò)信息
[1]文件數(shù)目不足
修改系統(tǒng)配置文件屬性
vim/etc/security/limits.conf 添加
elk soft memlock unlimited
elk hard memlock unlimited
elk soft nofile 65536
elk hard nofile 131072
退出用戶重新登錄,使配置生效
[2]: max virtual memoryareas vm.max_map_count [65530] is too low, increase to at least [262144]
解決辦法:
在 /etc/sysctl.conf文件最后添加一行
vm.max_map_count=262144
即可永久修改
- 啟動(dòng)elasticsearch服務(wù)
前臺(tái)啟動(dòng)服務(wù)需切換為es用戶
su elk
啟動(dòng)服務(wù)(當(dāng)前的路徑為:/usr/share/elasticsearch/)
./bin/elasticsearch
后臺(tái)運(yùn)行ES
可以加入-p 命令 讓es在后臺(tái)運(yùn)行, -p 參數(shù) 記錄進(jìn)程ID為一個(gè)文件
設(shè)置后臺(tái)啟動(dòng)
./bin/elasticsearch -p ./elasticsearch-pid -d
一般情況下,直接執(zhí)行一下命令即可
./bin/elasticsearch-d
結(jié)束進(jìn)程
查看運(yùn)行的pid,并查殺 cat /tmp/elasticsearch-pid && echo
kill -SIGTERM {pid}
暴力結(jié)束進(jìn)程(另一種方式)
kill -9 `ps -ef |grep elasticsearch|awk '{print $2}'
驗(yàn)證一下服務(wù)是否正常
curl -i "http://192.168.60.200:9200"
4.安裝elasticsearch-head插件(支持前端界面查看數(shù)據(jù))
安裝docker鏡像或者通過(guò)github下載elasticsearch-head項(xiàng)目都是可以的,1或者2兩種方式選擇一種安裝使用即可
【1】使用docker的集成好的elasticsearch-head
dockerrun -p 9100:9100 mobz/elasticsearch-head:5
docker容器下載成功并啟動(dòng)以后,運(yùn)行瀏覽器打開(kāi)http://localhost:9100/
【2】使用git安裝elasticsearch-head
yum install -y npm
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start
檢查端口是否起來(lái)
netstat -antp |grep 9100
瀏覽器訪問(wèn)測(cè)試是否正常
http://IP:9100/
【注意】由于elasticsearch-head:5鏡像對(duì)elasticsearch的7版本好像適配性不夠,所以部分顯示可能會(huì)有空白。推薦另外一個(gè)鏡像lmenezes/cerebro,下載后執(zhí)行docker run -d -p 9000:9000lmenezes/cerebro就可以在9000端口查看了。
最后,filebeat logstash kibana可以在配置文件后,正常啟動(dòng),如果需要切換用戶的話,也可以參照上面。本次這三個(gè)組件全部默認(rèn)用root用戶啟動(dòng)。由于分開(kāi)部署,與ES互不影響。
附:kafka三節(jié)點(diǎn)集群搭建
環(huán)境準(zhǔn)備
1.zookeeper集群環(huán)境,本次采用Kafka自帶的Zookeeper環(huán)境。
kafka是依賴于zookeeper注冊(cè)中心的一款分布式消息對(duì)列,所以需要有zookeeper單機(jī)或者集群環(huán)境。
2.三臺(tái)服務(wù)器:
192.168.108.200 ELK-kafka-cluster
192.168.108.165 ELK-kafka-salve1
192.168.108.103 ELK-kafka-salve2
3.下載kafka安裝包
在 http://kafka.apache.org/downloads 中下載,目前最新版本的kafka已經(jīng)到2.2.0,這里下載的是kafka_2.11-2.2.0.tgz
安裝kafka集群
1.上傳壓縮包到三臺(tái)服務(wù)器解壓縮到/opt/目錄下
tar -zxvf kafka_2.11-2.2.0.tgz -C /opt/
ls -s kafka_2.11-2.2.0 kafka
2.修改server.properties (/opt/kafka/config目錄下)
############################# Server Basics#############################
broker.id=0
######################## Socket Server Settings########################
listeners=PLAINTEXT://192.168.108.200:9092
advertised.listeners=PLAINTEXT://192.168.108.200:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
############################# Log Basics#############################
log.dirs=/var/log/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
######################## Internal Topic Settings#########################
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
######################### Log Retention Policy########################
The minimum age of a log file to be eligiblefor deletion due to age
log.retention.hours=168
The maximum size of a log segment file. Whenthis size is reached a new log segment will be created.
log.segment.bytes=1073741824
The interval at which log segments are checkedto see if they can be deleted according
to the retention policies
log.retention.check.interval.ms=300000
############################# Zookeeper#############################
zookeeper.connect=192.168.108.200:2181,192.168.108.165:2181,192.168.108.103:2181
Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
delete.topic.enable=true
######################## Group CoordinatorSettings ##########################
group.initial.rebalance.delay.ms=0
3.拷貝兩份到192.168.108.165和192.168.108.103
[root@192.168.108.165 config]# catserver.properties
broker.id=1
listeners=PLAINTEXT://192.168.108.165:9092
advertised.listeners=PLAINTEXT://192.168.108.165:9092
[root@k8s-n3 config]# cat server.properties
broker.id=2
listeners=PLAINTEXT://192.168.108.103:9092
advertised.listeners=PLAINTEXT://192.168.108.103:9092
然后添加環(huán)境變量 在/etc/profile 中添加
export ZOOKEEPER_HOME=/opt/kafka
export PATH=$PATH:$ZOOKEEPER_HOME/bin
source /etc/profile 重載生效
4.修改zookeeper.properties:
1.設(shè)置連接參數(shù),添加如下配置
maxClientCnxns=100
tickTime=2000
initLimit=10
syncLimit=5
2.設(shè)置broker Id的服務(wù)地址
server.0=192.168.108.200:2888:3888
server.1=192.168.108.165:2888:3888
server.2=192.168.108.103:2888:3888
總結(jié)就在Kafka源碼目錄的/kafka/config/zookeeper.properties文件設(shè)置如下
dataDir=/opt/zookeeper # 這時(shí)需要在/opt/zookeeper文件夾下,新建myid文件,把broker.id填寫(xiě)進(jìn)去,本次本節(jié)點(diǎn)為0。
the port at which the clients will connect
clientPort=2181
disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=100
tickTime=2000
initLimit=10
syncLimit=5
server.0=192.168.108.200:2888:3888
server.1=192.168.108.165:2888:3888
server.2=192.168.108.103:2888:3888
然后在zookeeper數(shù)據(jù)目錄添加id配置(dataDir=/opt/zookeeper)
在zookeeper.properties的數(shù)據(jù)目錄中創(chuàng)建myid文件
在各臺(tái)服務(wù)的zookeeper數(shù)據(jù)目錄添加myid文件,寫(xiě)入服務(wù)broker.id屬性值,如這里的目錄是/usr/local/zookeeper/data
第一臺(tái)broker.id為0的服務(wù)到該目錄下執(zhí)行:echo 0 > myid
[root@192-168-108-165 kafka]# cd /opt/zookeeper/
[root@192-168-108-165 zookeeper]# ls
myid version-2
[root@192-168-108-165 zookeeper]# cat myid
1
[root@192-168-108-165 zookeeper]#
集群?jiǎn)?dòng)
集群?jiǎn)?dòng):cd /opt/kafka
先分別啟動(dòng)zookeeper
kafka使用到了zookeeper,因此你要首先啟動(dòng)一個(gè)zookeeper服務(wù),如果你沒(méi)有zookeeper服務(wù)。kafka中打包好了一個(gè)簡(jiǎn)潔版的單節(jié)點(diǎn)zookeeper實(shí)例。
kafka啟動(dòng)時(shí)先啟動(dòng)zookeeper,再啟動(dòng)kafka;關(guān)閉時(shí)相反,先關(guān)閉kafka,再關(guān)閉zookeep
前臺(tái)啟動(dòng):bin/zookeeper-server-start.sh config/zookeeper.properties
[root@192-168-108-200 ~]# lsof -i:2181
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODENAME
java 5197 root 98u IPv6 527171 0t0 TCP *:eforward(LISTEN)
可以看到已經(jīng)啟動(dòng)
后臺(tái)啟動(dòng):bin/zookeeper-server-start.sh-daemon config/zookeeper.properties
再分別啟動(dòng)kafka
前臺(tái)啟動(dòng):bin/kafka-server-start.sh config/server.properties
[root@192-168-108-200 ~]# lsof -i:9092
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 5519 root 157u IPv6 528511 0t0 TCP 192-168-108-200:XmlIpcRegSvc (LISTEN)
java 5519 root 167u IPv6 528515 0t0 TCP 192-168-108-200:XmlIpcRegSvc->192.168.108.191:56656(ESTABLISHED)
java 5519 root 169u IPv6 528516 0t0 TCP192-168-108-200:XmlIpcRegSvc->192.168.108.187:49368 (ESTABLISHED)
java 5519 root 176u IPv6 528096 0t0 TCP192-168-108-200:48062->192-168-108-200:XmlIpcRegSvc (ESTABLISHED)
java 5519 root 177u IPv6 528518 0t0 TCP192-168-108-200:XmlIpcRegSvc->192-168-108-200:48062 (ESTABLISHED)
java 5519 root 178u IPv6 528097 0t0 TCP192-168-108-200:XmlIpcRegSvc->192.168.108.187:49370 (ESTABLISHED)
后臺(tái)啟動(dòng):bin/kafka-server-start.sh -daemon config/server.properties
服務(wù)啟動(dòng)腳本
cd /opt/kafka
kill -9 ps -ef |grep kafka|awk '{print $2}'
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
bin/kafka-server-start.sh -daemonconfig/server.properties
Zookeeper+Kafka集群測(cè)試
/opt/kafka/bin
1.創(chuàng)建topic:
kafka-topics.sh --create--zookeeper
192.168.108.200:2181,192.168.108.165:2181,192.168.108.103:2181--replication-factor 3 --partitions 3 --topic test
2.顯示topic
kafka-topics.sh --describe--zookeeper 192.168.108.200:2181,192.168.108.165:2181,192.168.108.103:2181--topic test
[root@192-168-108-200 bin]# kafka-topics.sh--describe --zookeeper192.168.108.200:2181,192.168.108.165:2181,192.168.108.103:2181 --topic tyun
Topic:tyun PartitionCount:3 ReplicationFactor:3Configs:
Topic: tyun Partition: 0 Leader: 1 Replicas: 1,0,2Isr: 1,0,2
Topic: tyun Partition: 1 Leader: 2 Replicas: 2,1,0Isr: 2,1,0
Topic: tyun Partition: 2 Leader: 0 Replicas: 0,2,1Isr: 0,2,1
PartitionCount:partition個(gè)數(shù) ??
ReplicationFactor:副本個(gè)數(shù) ??
Partition:partition編號(hào),從0開(kāi)始遞增 ??
Leader:當(dāng)前partition起作用的broker.id ??
Replicas: 當(dāng)前副本數(shù)據(jù)所在的broker.id,是一個(gè)列表,排在最前面的其作用??
Isr:當(dāng)前kakfa集群中可用的broker.id列表

3.列出topic
kafka-topics.sh --list --zookeeper192.168.108.200:2181,192.168.108.165:2181,192.168.108.103:2181
test
創(chuàng)建 producer(生產(chǎn)者);
kafka-console-producer.sh --broker-list192.168.108.200:9092 --topic test
hello
創(chuàng)建 consumer(消費(fèi)者)
kafka-console-consumer.sh --bootstrap-server192.168.108.200:9092 --topic test --from-beginning
hello
4.查看寫(xiě)入kafka集群中的消息(重要命令,判斷日志是否寫(xiě)入Kafka的重要依據(jù))
bin/kafka-console-consumer.sh--bootstrap-server 192.168.108.200:9092 --topic tiops --from-beginning
5.刪除 Topic----命令標(biāo)記刪除后,再次刪除對(duì)應(yīng)的數(shù)據(jù)目錄
bin/kafka-topics.sh--delete --zookeeper master:2181,slave1:2181,slave2:2181 --topic topic_name
若 delete.topic.enable=true
直接徹底刪除該 Topic。
若delete.topic.enable=false
如果當(dāng)前 Topic 沒(méi)有使用過(guò)即沒(méi)有傳輸過(guò)信息:可以徹底刪除。
如果當(dāng)前 Topic 有使用過(guò)即有過(guò)傳輸過(guò)信息:并沒(méi)有真正刪除 Topic 只是把這個(gè) Topic 標(biāo)記為刪除(marked for deletion),重啟 Kafka Server 后刪除。
注:delete.topic.enable=true 配置信息位于配置文件 config/server.properties 中(較新的版本中無(wú)顯式配置,默認(rèn)為 true)。
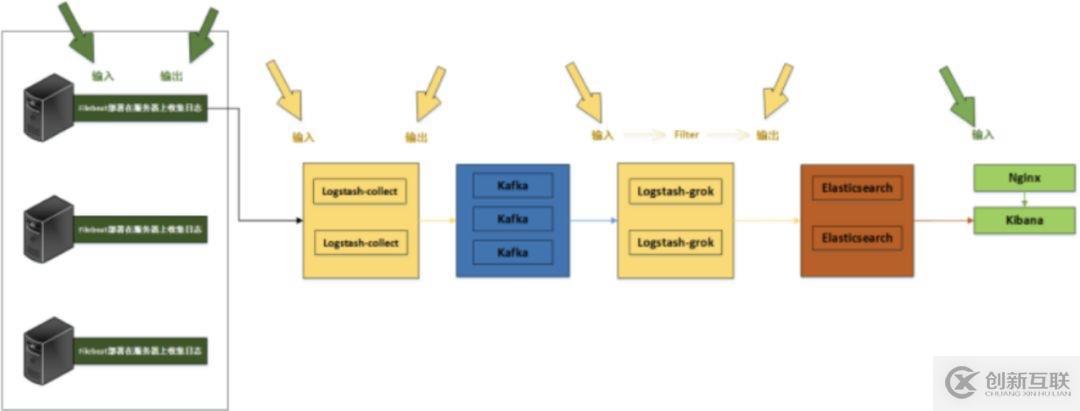
- 日志系統(tǒng)架構(gòu)解析
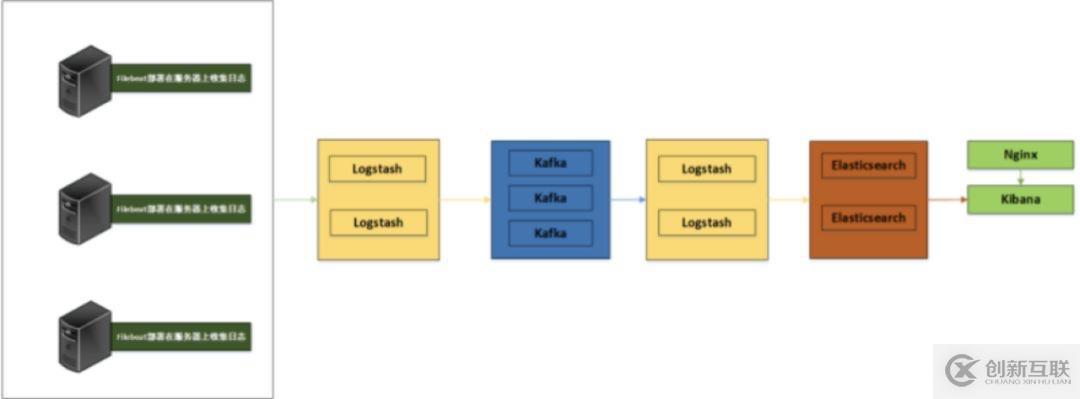
整個(gè)系統(tǒng)一共含有10臺(tái)主機(jī)(filebeat部署在客戶端,不計(jì)算在內(nèi)),其中Logstash有四臺(tái),Elasticsearch有二臺(tái),Kafka集群三臺(tái),kibana一臺(tái)并配置Nginx代理。
架構(gòu)解釋:
(1)首先用戶通過(guò)nginx代理訪問(wèn)ELK日志統(tǒng)計(jì)平臺(tái),這里的Nginx可以設(shè)置界面密碼。
(2)Nginx將請(qǐng)求轉(zhuǎn)發(fā)到kibana
(3)kibana到Elasticsearch中去獲取數(shù)據(jù),這里的Elasticsearch是兩臺(tái)做的集群,日志數(shù)據(jù)會(huì)隨機(jī)保存在任意一臺(tái)Elasticsearch服務(wù)器。
(4)Logstash2從Kafka中取出數(shù)據(jù)并發(fā)送到Elasticsearch中。
(5)Kafka服務(wù)器做日志數(shù)據(jù)的持久化保存,避免web服務(wù)器日志量過(guò)大的時(shí)候造成的數(shù)據(jù)收集與保存不一致而導(dǎo)致日志丟失,其中Kafka可以做集群,然后再由Logstash服務(wù)器從Kafka持續(xù)的取出數(shù)據(jù)。
(6)logstash3從Filebeat取出的日志信息,并放入Kafka中進(jìn)行保存。
(7)Filebeat在客戶端進(jìn)行日志的收集。
注1:【Kafka的加入原因與作用】
整個(gè)架構(gòu)加入Kafka,是為了讓整個(gè)系統(tǒng)更好的分層,Kafka作為一個(gè)消息流處理與持久化存儲(chǔ)軟件,能夠幫助我們?cè)谥鞴?jié)點(diǎn)上屏蔽掉多個(gè)從節(jié)點(diǎn)之間不同日志文件的差異,負(fù)責(zé)管理日志端(從節(jié)點(diǎn))的人可以專注于向 Kafka里生產(chǎn)數(shù)據(jù),而負(fù)責(zé)數(shù)據(jù)分析聚合端的人則可以專注于從 Kafka內(nèi)消費(fèi)數(shù)據(jù)。所以部署時(shí)要把Kafka加進(jìn)去。
而且使用Kafka進(jìn)行日志傳輸?shù)脑蜻€在于其有數(shù)據(jù)緩存的能力,并且它的數(shù)據(jù)可重復(fù)消費(fèi),Kafka本身具有高可用性,能夠很好的防止數(shù)據(jù)丟失,它的吞吐量相對(duì)來(lái)說(shuō)比較好并且使用廣泛。可以有效防止日志丟失和防止logsthash掛掉。綜合來(lái)說(shuō):它均衡了網(wǎng)絡(luò)傳輸,從而降低了網(wǎng)絡(luò)閉塞,尤其是丟失數(shù)據(jù)的可能性,
注2:【雙層的Logstash作用】
這里為什么要在Kafka前面增加二臺(tái)logstash呢?是因?yàn)樵诖罅康娜罩緮?shù)據(jù)寫(xiě)入時(shí),容易導(dǎo)致數(shù)據(jù)的丟失和混亂,為了解決這一問(wèn)題,增加二臺(tái)logstash可以通過(guò)類型進(jìn)行匯總分類,降低數(shù)據(jù)傳輸?shù)挠纺[。
如果只有一層的Logstash,它將處理來(lái)自不同客戶端Filebeat收集的日志信息匯總,并且進(jìn)行處理分析,在一定程度上會(huì)造成在大規(guī)模日志數(shù)據(jù)下信息的處理混亂,并嚴(yán)重加深負(fù)載,所以有二層的結(jié)構(gòu)進(jìn)行負(fù)載均衡處理,并且職責(zé)分工,一層匯聚簡(jiǎn)單分流,一層分析過(guò)濾處理信息,并且內(nèi)層都有二臺(tái)Logstash來(lái)保障服務(wù)的高可用性,以此提升整個(gè)架構(gòu)的穩(wěn)定性。
接下來(lái)分別說(shuō)明原理與各個(gè)組件之間的交互(配置文件)。
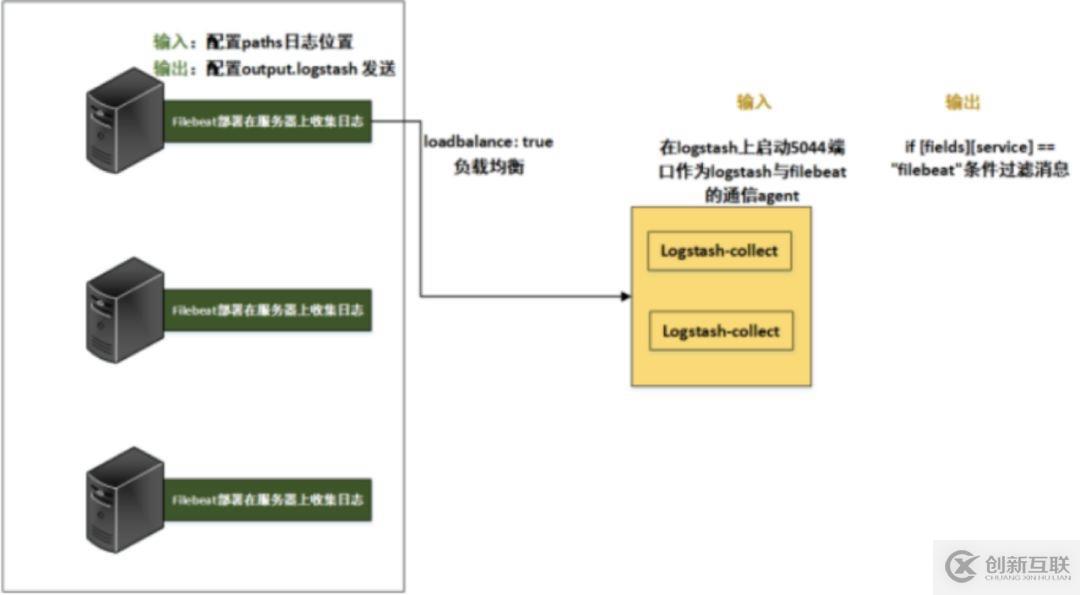
1.Filebeat與Logstash-collect連接配置
這里為了方便記憶,把此處的Logstash稱為L(zhǎng)ogstash-collect,首先看Filebeat的配置文件:
其中,filebeat配置輸出到logstash:5044端口,在logstash上啟動(dòng)5044端口作為logstash與filebeat的通信agent,而logstash本身服務(wù)起在9600端口.
[root@192-168-108-191 logstash]# ss -lnt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 :::5044 :::
LISTEN 0 50 ::ffff:192.168.108.191:9600 :::
vim /etc/filebeat/filebeat.yml # 對(duì)幾個(gè)重要配置進(jìn)行設(shè)置如下
type: log
Change to true to enable this inputconfiguration.
enabled: true
Paths that should be crawled and fetched.Glob based paths.
paths:
- /var/log/*.log
- /var/log/tiops/*/.log # 即tiops平臺(tái)的所有日志位置, 指定數(shù)據(jù)的輸入路徑為/tiops/*/.log結(jié)尾的所有文件,注意/tiops/子目錄下的日志不會(huì)被讀取,孫子目錄下的日志可以
#- c:\programdata\elasticsearch\logs*
fields:
service: filebeat
multiline: # 多行日志合并為一行,適用于日志中每一條日志占據(jù)多行的情況,比如各種語(yǔ)言的報(bào)錯(cuò)信息調(diào)用棧。
pattern: ‘^[‘
negate: true
match: afterExcludelines. A list of regular expressions to match. It drops the lines that are
刪除以DBG開(kāi)頭的行:
exclude_lines: ['^DBG']
filebeat的日志可發(fā)送到logstash、elasticsearch、kibana,選擇一個(gè)即可,本次默認(rèn)選擇logstash,其他二個(gè)可以注釋
output.logstash:
The Logstash hosts
hosts:["192.168.108.191:5044", "192.168.108.87:5044"] # 發(fā)往二臺(tái)Logstash-collect
loadbalance: true
worker: 2
#output.elasticsearch:
#hosts: ["http://192.168.108.35:9200"]
#username: "elk"
#password: ""
#setup.kibana:
#host: "192.168.108.182:5601"
注1:【Filebeat與Logstash-collect的日志消息流轉(zhuǎn)】
注意事項(xiàng):Logstash-collect怎么接收到Filebeat發(fā)送的消息,并再次發(fā)向下一級(jí)呢?
不僅僅配置發(fā)往二臺(tái)Logstash-collect的ip地址加端口,還要注意fields字段,可以理解為是一個(gè)Key,當(dāng)Logstash-collect收到多個(gè)Key時(shí),它可以選擇其中一個(gè)或者多個(gè)Key來(lái)進(jìn)行下一級(jí)發(fā)送,達(dá)到日志消息的轉(zhuǎn)發(fā)。
在使用了6.2.3版本的ELK以后,如果使用if [type]配置,則匹配不到在filebeat里面使用document_type定義的字符串。因?yàn)?.0版本以上已經(jīng)取消了document_type的定義。如果要實(shí)現(xiàn)以上的配置只能使用如下配置:
fields:
service: filebeat
service : filebeat都是自己定義的,定義完成后使用Logstash的if 判斷,條件為if [fields][service] == "filebeat".就可以了,具體可以看下面的轉(zhuǎn)發(fā)策略。
注2:【Filebeat負(fù)載平衡主機(jī)的輸出】
這里還有一點(diǎn)需要說(shuō)明一下,就是關(guān)于Filebeat與Logstash-collect連接的負(fù)載均衡設(shè)置。
logstash是一個(gè)無(wú)狀態(tài)的流處理軟件。logstash怎么集群配置只能橫向擴(kuò)展,然后自己用配置管理工具分發(fā),因?yàn)樗麄儍?nèi)部并沒(méi)有交流的。
Filebeat提供配置選項(xiàng),可以使用它來(lái)調(diào)整負(fù)載平衡時(shí)發(fā)送消息到多個(gè)主機(jī)。要啟用負(fù)載均衡,您指定loadbalance的值為true。
output.logstash:
The Logstash hosts
hosts: ["192.168.108.191:5044","192.168.108.87:5044"] # 發(fā)往二臺(tái)Logstash-collect
loadbalance:true
worker: 2loadbalance: false # 消息只是往一個(gè)logstash里發(fā),如果這個(gè)logstash掛了,就會(huì)自動(dòng)將數(shù)據(jù)發(fā)到另一個(gè)logstash中。(主備模式)
loadbalance: true # 如果為true,則將數(shù)據(jù)均分到各個(gè)logstash中,掛了就不發(fā)了,往存活的logstash里面發(fā)送。
即logstash地址如果為一個(gè)列表,如果loadbalance開(kāi)啟,則負(fù)載到里表中的服務(wù)器,當(dāng)一個(gè)logstash服務(wù)器不可達(dá),事件將被分發(fā)到可到達(dá)的logstash服務(wù)器(雙活模式)
loadbalance選項(xiàng)可供Redis,Logstash, Elasticsearch輸出。Kafka的輸出可以在其自身內(nèi)部處理負(fù)載平衡。
同時(shí)每個(gè)主機(jī)負(fù)載平衡器還支持多個(gè)workers。默認(rèn)是1。如果你增加workers的數(shù)量, 將使用額外的網(wǎng)絡(luò)連接。workers參與負(fù)載平衡的總數(shù)=主機(jī)數(shù)量*workers。
在這個(gè)小節(jié),配置總體結(jié)構(gòu),與日志數(shù)據(jù)流向如下圖:
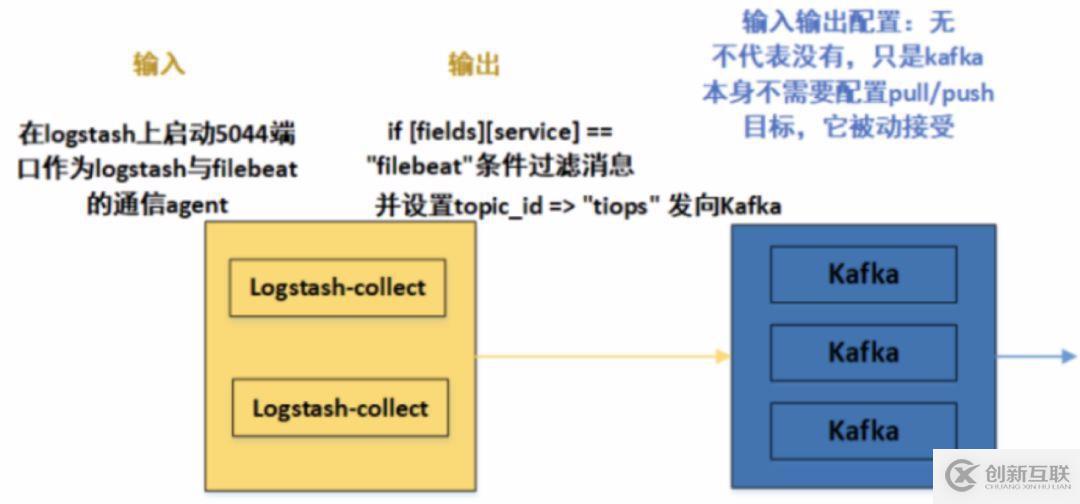
2.Logstash-collect與Kafka連接配置
首先看/etc/logstash/logstash.yml文件,作為L(zhǎng)ogstash-collect的公共配置文件,我們需要做一下的更改:
vim/etc/logstash/logstash.yml
path.data: /var/lib/logstash #數(shù)據(jù)存放路徑
path.config: /etc/logstash/conf.d #配置文件的讀取路徑
path.logs: /var/log/logstash #日志文件的保存路徑
pipeline.workers: 2 # 默認(rèn)為CPU的核數(shù)
http.host: "192.168.108.186"
http.port: 9600-9700 # logstash will pick up thefirst available ports
注意上面配置文件的讀取路徑 /etc/logstash/conf.d,在這個(gè)文件夾里面,我們可以設(shè)置Logstash的輸入輸出。logstash支持把配置寫(xiě)入文件/etc/logstash/conf.d/xxx.conf,然后通過(guò)讀取配置文件來(lái)采集數(shù)據(jù)。
logstash收集日志基本流程:input–>codec–>filter–>codec–>output ,所以配置文件可以設(shè)置輸入輸出與過(guò)濾的基本格式如下:(這里暫時(shí)忽略filter,因?yàn)檫@一層的Logstash主要匯聚數(shù)據(jù),暫不分析匹配)
關(guān)于codec => json # json處理
logstash最終會(huì)把數(shù)據(jù)封裝成json類型,默認(rèn)會(huì)添加@timestamp時(shí)間字段、host主機(jī)字段、type字段。原消息數(shù)據(jù)會(huì)整個(gè)封裝進(jìn)message字段。如果數(shù)據(jù)處理過(guò)程中,用戶解析添加了多個(gè)字段,則最終結(jié)果又會(huì)多出多個(gè)字段。也可以在數(shù)據(jù)處理過(guò)程中移除多個(gè)字段,總之,logstash最終輸出的數(shù)據(jù)格式是json格式。所以數(shù)據(jù)經(jīng)過(guò)Logstash會(huì)增加額外的字段,可以選擇過(guò)濾。
Logstash主要由 input,filter,output三個(gè)組件去完成采集數(shù)據(jù)。
input {
指定輸入
}
filter {
}
output {
指定輸出
解釋說(shuō)明如下:
input
input組件負(fù)責(zé)讀取數(shù)據(jù),可以采用file插件讀取本地文本文件,stdin插件讀取標(biāo)準(zhǔn)輸入數(shù)據(jù),tcp插件讀取網(wǎng)絡(luò)數(shù)據(jù),log4j插件讀取log4j發(fā)送過(guò)來(lái)的數(shù)據(jù)等等。本次用beats插件讀取Filebeat發(fā)送過(guò)來(lái)的日志消息。
filter
filter插件負(fù)責(zé)過(guò)濾解析input讀取的數(shù)據(jù),可以用grok插件正則解析數(shù)據(jù),date插件解析日期,json插件解析json等等。
output
output插件負(fù)責(zé)將filter處理過(guò)的數(shù)據(jù)輸出。可以用elasticsearch插件輸出到es,redis插件輸出到redis,stdout插件標(biāo)準(zhǔn)輸出,kafka插件輸出到kafka等等
在實(shí)際的Tiops平臺(tái)日志處理流程中,配置如下:
二個(gè)Logstash-collect均采用此相同的配置
在/etc/logstash/conf.d目錄下,創(chuàng)建filebeat-kafka.conf文件,內(nèi)容如下:
input {
beats {
port => 5044 # logstash上啟動(dòng)5044端口作為logstash與filebeat的通信agent
codec => json # json處理
}
}
#此處附加Redis作為緩存消息的配置,本次采用Kafka,所以此部分暫時(shí)注釋
#output {
if [fields][service] == "filebeat"{
redis {
data_type => "list"
host => "192.168.108.200"
db => "0"
port => "6379"
key => "tiops-tcmp"
}
}
#}
output {
if [fields][service] == "filebeat"{ # 參照第一部分,Logstash-collect怎么接收到Filebeat發(fā)送的消息,并再次發(fā)向下一級(jí)呢?這里就是取filebeat的Fields字段的Key值,進(jìn)行向下發(fā)送
kafka {
bootstrap_servers =>"192.168.108.200:9092,192.168.108.165:9092,192.168.108.103:9092" # kafka集群配置,全部IP:端口都要加上
topic_id => "tiops" # 設(shè)置Kafka的topic,這樣發(fā)送到kafka中時(shí),kafka就會(huì)自動(dòng)創(chuàng)建該topic
}
}
}
在這個(gè)小節(jié),配置總體結(jié)構(gòu)與日志數(shù)據(jù)流向如下圖:
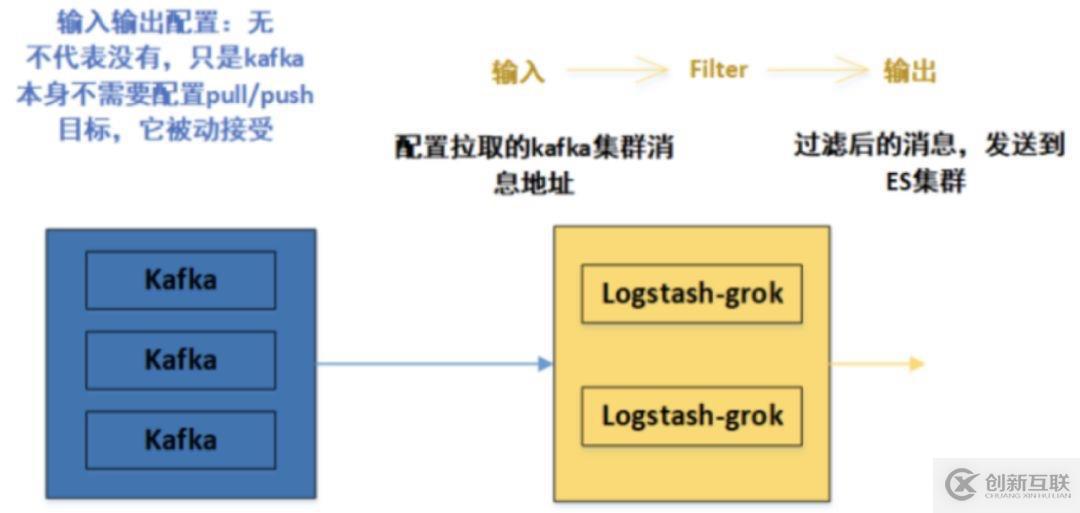
3.Kafka與Logstash-grok連接配置
在上面第二部分,我們已經(jīng)成功把數(shù)據(jù)從Logstash-collect發(fā)送到Kafka,而Kafka本身的輸入輸出并沒(méi)有配置。而是Logstash-collect指定了一個(gè)topic,這并不代表kafka不需要配置參數(shù),只是kafka本身不需要配置pull/push目標(biāo)參數(shù),它被動(dòng)接受
別的生產(chǎn)者發(fā)送過(guò)來(lái)的數(shù)據(jù),因?yàn)長(zhǎng)ogstash-collect指定了Kafka集群的IP地址和端口。那么數(shù)據(jù)將會(huì)被發(fā)送到Kafka中,那么Kafka如何處理這些日志數(shù)據(jù),那么這時(shí)候就需要Kafka配置消息處理參數(shù)了。
這個(gè)我們現(xiàn)在暫時(shí)先給出參數(shù),至于具體原因涉及到MQ的高可用、消息過(guò)期策略、如何保證消息不重復(fù)消費(fèi)、如何保證消息不丟失、如何保證消息按順序執(zhí)行以及消息積壓在消息隊(duì)列里怎么辦等問(wèn)題,我們之后詳細(xì)分析并解決。
以下是Kafka集群中,某一臺(tái)的配置文件,在Kafka源碼目錄的/kafka/config/server.properties文件設(shè)置如下:(加粗的為重要配置文件)
broker.id=0
listeners=PLAINTEXT://192.168.108.200:9092
advertised.listeners=PLAINTEXT://192.168.108.200:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/var/log/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.108.200:2181,192.168.108.165:2181,192.168.108.103:2181 # zookeeper 集群
delete.topic.enable=true
同時(shí)kafka是依賴于zookeeper注冊(cè)中心的一款分布式消息隊(duì)列,所以需要有zookeeper單機(jī)或者集群環(huán)境。本次采用Kafka自帶的Zookeeper環(huán)境。
在Kafka源碼目錄的/kafka/config/zookeeper.properties文件設(shè)置如下:
dataDir=/opt/zookeeper # 這時(shí)需要在/opt/zookeeper文件夾下,新建myid文件,把broker.id填寫(xiě)進(jìn)去,本次本節(jié)點(diǎn)為0。
the port at which the clients will connect
clientPort=2181
disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=100
tickTime=2000
initLimit=10
syncLimit=5
server.0=192.168.108.200:2888:3888
server.1=192.168.108.165:2888:3888
server.2=192.168.108.103:2888:3888
其他注意事項(xiàng),請(qǐng)看之前的Kafka集群安裝步驟,這里主要給出集群某一節(jié)點(diǎn)的配置文件參數(shù)。
到目前為止,我們配置了kafka的參數(shù),對(duì)消息進(jìn)行了處理(持久化...),接下來(lái)就需要對(duì)Kafka中的消息進(jìn)行下一步的傳輸,即傳送到Logstash-grok。
這里需要注意的是:并不是Kafka主動(dòng)把消息發(fā)送出去的,當(dāng)然Kafka也支持這種操作,但是在這里,采用的是Logstash-grok作為消費(fèi)者,主動(dòng)拉取Kafka中的消息,來(lái)進(jìn)行消費(fèi)。
所以就需要像第二步Logstash-collect那樣進(jìn)行輸入輸出設(shè)置,這里L(fēng)ogstash-grok不僅僅配置輸入輸出,最重要的是它的過(guò)濾filter作用。
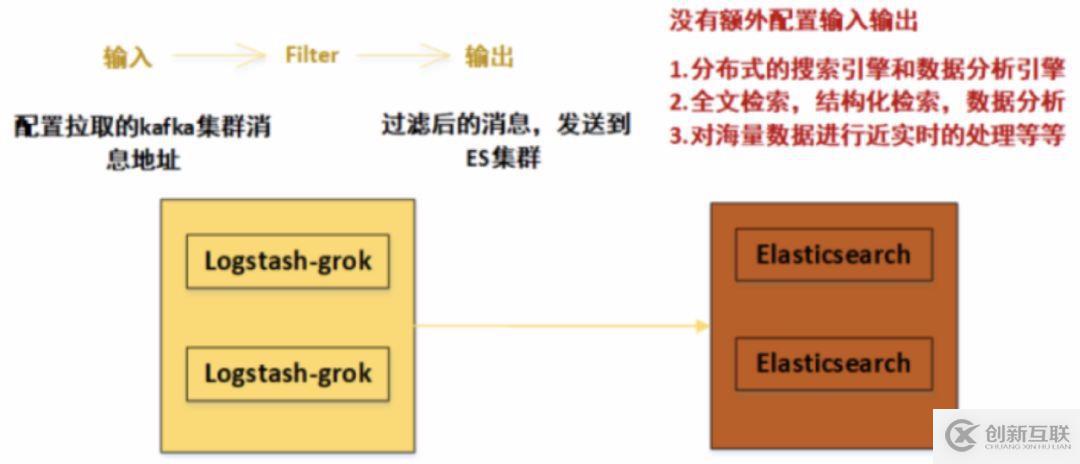
在/etc/logstash/conf.d目錄下,創(chuàng)建logstash-es.conf文件,這里給出Logstash-grok中一個(gè)的內(nèi)容如下(二個(gè)Logstash-grok配置一樣):
#input {
redis {
data_type => "list"
host => "192.168.108.200"
db => "0"
port => "6379"
key => "tiops-tcmp"
password => "123456"
}
#}
input{
kafka{
bootstrap_servers =>["192.168.108.200:9092,192.168.108.165:9092,192.168.108.103:9092"] #配置拉取的kafka集群消息地址
group_id => "tyun" # 設(shè)置group_id,對(duì)于這個(gè)消費(fèi)組而言會(huì)有一個(gè)消費(fèi) offset,消費(fèi)掉是 auto_commit 部分控制的,這個(gè)參數(shù)會(huì)定期將你消費(fèi)的 offset 提交到 kafka,下次啟動(dòng)的時(shí)候已經(jīng)消費(fèi)過(guò)的就不會(huì)重復(fù)消費(fèi)了;
如果想重新消費(fèi),可以換一個(gè) group_id 即可
auto_offset_reset =>"earliest"
consumer_threads => "3" #多個(gè)實(shí)例的consumer_threads數(shù)之和應(yīng)該等于topic分區(qū)數(shù)近似達(dá)到logstash多實(shí)例的效果。
decorate_events => "false"
topics => ["tiops"] # kafka topic 名稱,獲取指定topic內(nèi)的消息
type => "log"
codec => json
}}
filter { # 此處Logstash最主要的過(guò)濾作用,可以自定義正則表達(dá)式,選擇性輸出消息
grok {
match => {
#截取
"message" =>"(?<LOG>(?<=architecture=x86_64}|containerized=true})(.*)/?)"
}
}
}
output { #過(guò)濾后的消息,發(fā)送到ES集群
elasticsearch {
hosts =>["192.168.108.35:9200","192.168.108.194:9200"]
codec => json
index =>"tiops-%{+YYYY.MM.dd}" # 自定義索引名稱
}
在這個(gè)小節(jié),配置總體結(jié)構(gòu)與日志數(shù)據(jù)流向如下圖:
4.Logstash-grok與Elasticsearch(ES)集群連接配置
ElasticSearch集群
在第三步中,我們已經(jīng)將Logstash-grok過(guò)濾后的消息,發(fā)送到了ES集群,這里的ES集群被動(dòng)接受發(fā)送過(guò)來(lái)的消息,即ES集群本身不需要配置輸入源,已經(jīng)由其他組件發(fā)送決定了。
ES的配置將集中體現(xiàn)在集群自身的配置上。
Elasticsearch 可以橫向擴(kuò)展至數(shù)百(甚至數(shù)千)的服務(wù)器節(jié)點(diǎn),同時(shí)可以處理PB級(jí)數(shù)據(jù)
Elasticsearch 天生就是分布式的,并且在設(shè)計(jì)時(shí)屏蔽了分布式的復(fù)雜性。
ES功能:(1)分布式的搜索引擎和數(shù)據(jù)分析引擎
(2)全文檢索,結(jié)構(gòu)化檢索,數(shù)據(jù)分析
(3)對(duì)海量數(shù)據(jù)進(jìn)行近實(shí)時(shí)的處理
安裝后的ES集群,配置在/etc/elasticsearch/elasticsearch.yml文件,集群中,各個(gè)節(jié)點(diǎn)配置大體相同,不同之處下面有紅字標(biāo)出,主要就是節(jié)點(diǎn)名稱與網(wǎng)絡(luò)監(jiān)聽(tīng)地址,需要每個(gè)節(jié)點(diǎn)自行按實(shí)際填寫(xiě)。
cluster.name: elk-cluster #集群名稱
node.name: elk-node1 #節(jié)點(diǎn)名稱,一個(gè)集群之內(nèi)節(jié)點(diǎn)的名稱不能重復(fù)
path.data: /data/elkdata #數(shù)據(jù)路徑
path.logs: /data/elklogs #日志路徑
bootstrap.memory_lock: true #鎖住es內(nèi)存,保證內(nèi)存不分配至交換分區(qū)。
network.host: 192.168.108.35 #網(wǎng)絡(luò)監(jiān)聽(tīng)地址,可以訪問(wèn)elasticsearch的ip, 默認(rèn)只有本機(jī)
http.port: 9200 #用戶訪問(wèn)查看的端口,9300是ES組件訪問(wèn)使用
discovery.seed_hosts: ["192.168.108.35","192.168.108.194"] 單播(配置一臺(tái)即可,生產(chǎn)可以使用組播方式)
cluster.initial_master_nodes: ["192.168.108.35"] # Master
http.cors.enabled: true # 這二個(gè)是ES插件的web顯示設(shè)置,head插件防止跨域
http.cors.allow-origin: "*"
可見(jiàn)集群配置中最重要的兩項(xiàng)是node.name與network.host,每個(gè)節(jié)點(diǎn)都必須不同。其中node.name是節(jié)點(diǎn)名稱主要是在Elasticsearch自己的日志加以區(qū)分每一個(gè)節(jié)點(diǎn)信息。
discovery.seed_hosts是集群中的節(jié)點(diǎn)信息,可以使用IP地址、可以使用主機(jī)名(必須可以解析)。
當(dāng)ElasticSearch的節(jié)點(diǎn)啟動(dòng)后,它會(huì)利用多播(multicast)(或者單播),如果用戶更改了配置)尋找集群中的其它節(jié)點(diǎn),并與之建立連接。(節(jié)點(diǎn)發(fā)現(xiàn))
這里沒(méi)有配置分片的數(shù)目,在ES的7版本中,默認(rèn)為1,這個(gè)包括replicas可后來(lái)自定義設(shè)置。
在這個(gè)小節(jié),配置總體結(jié)構(gòu)與日志數(shù)據(jù)流向如下圖:
5.Elasticsearch(ES)集群與Kibana連接配置
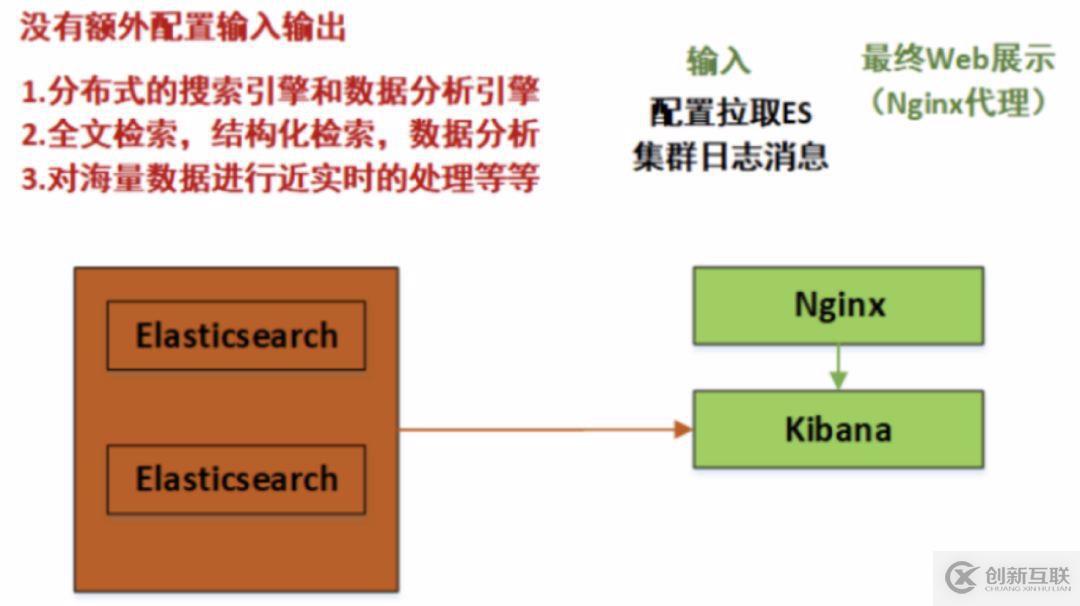
Kibana是一個(gè)開(kāi)源的分析和可視化平臺(tái),和Elasticsearch一起工作時(shí),就可以用Kibana來(lái)搜索,查看,并和存儲(chǔ)在Elasticsearch索引中的數(shù)據(jù)進(jìn)行交互。
可以輕松地執(zhí)行高級(jí)數(shù)據(jù)分析,并且以各種圖標(biāo)、表格和地圖的形式可視化數(shù)據(jù)。
同時(shí)Kibana使得理解大量數(shù)據(jù)變得很容易。它簡(jiǎn)單的、基于瀏覽器的界面使你能夠快速創(chuàng)建和共享動(dòng)態(tài)儀表板,實(shí)時(shí)顯示Elasticsearch查詢的變化。
在第四步中,我們已經(jīng)將ES集群中的數(shù)據(jù)進(jìn)行了處理,建立了索引(相當(dāng)于MySQL的database概念),并且分片、副本等都存在,而且處理后的數(shù)據(jù)更加方便于檢索。
Kibana的配置在/etc/kibana/kibana.yml文件中,如下:
server.port: 5601 #監(jiān)聽(tīng)端口
server.host: "192.168.108.182" #監(jiān)聽(tīng)I(yíng)P地址,建議內(nèi)網(wǎng)ip
#kibana.index: ".newkibana"
elasticsearch.hosts: ["http://192.168.108.35:9200","http://192.168.108.194:9200"] # ES機(jī)器的IP,這里的所有host必須來(lái)自于同一個(gè)ES集群
#xpack.security.enabled: false #添加這條,這條是配置kibana的安全機(jī)制,暫時(shí)關(guān)閉。
可以看出,這里的Kibana會(huì)主動(dòng)去ES集群中去拉取數(shù)據(jù),最后在瀏覽器Web端進(jìn)行實(shí)時(shí)展示。
這時(shí),我們打開(kāi)瀏覽器界面如下,看看最終的結(jié)果:
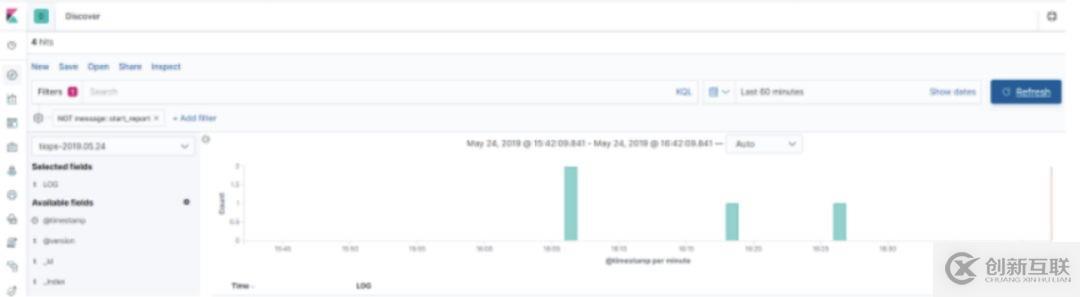
注:Nginx代理配置,可以通過(guò)自定義域名訪問(wèn)并設(shè)置密碼,提升安全性。(可選)
upstream kibana_server {
server 192.168.108.182:5601weight=1 max_fails=3 fail_timeout=60;
}
server {
listen 80;
server_name www.kibana.com;
auth_basic "RestrictedAccess";
auth_basic_user_file/etc/nginx/conf.d/htpasswd.users;
location / {
proxy_pass http://kibana_server;
proxy_http_version 1.1;
在這個(gè)小節(jié),配置總體結(jié)構(gòu)與日志數(shù)據(jù)流向如下圖:
6.總結(jié)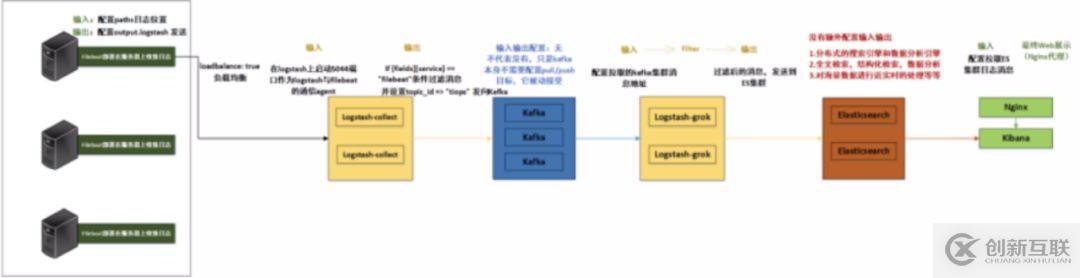
再將日志流向的配置文件輸入輸出標(biāo)注一下:
另外有需要云服務(wù)器可以了解下創(chuàng)新互聯(lián)cdcxhl.cn,海內(nèi)外云服務(wù)器15元起步,三天無(wú)理由+7*72小時(shí)售后在線,公司持有idc許可證,提供“云服務(wù)器、裸金屬服務(wù)器、高防服務(wù)器、香港服務(wù)器、美國(guó)服務(wù)器、虛擬主機(jī)、免備案服務(wù)器”等云主機(jī)租用服務(wù)以及企業(yè)上云的綜合解決方案,具有“安全穩(wěn)定、簡(jiǎn)單易用、服務(wù)可用性高、性價(jià)比高”等特點(diǎn)與優(yōu)勢(shì),專為企業(yè)上云打造定制,能夠滿足用戶豐富、多元化的應(yīng)用場(chǎng)景需求。
當(dāng)前標(biāo)題:萬(wàn)字長(zhǎng)文:ELK(V7)部署與架構(gòu)分析-創(chuàng)新互聯(lián)
URL地址:http://www.chinadenli.net/article30/dccepo.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供品牌網(wǎng)站設(shè)計(jì)、營(yíng)銷型網(wǎng)站建設(shè)、企業(yè)網(wǎng)站制作、關(guān)鍵詞優(yōu)化、自適應(yīng)網(wǎng)站、做網(wǎng)站
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- 星外主機(jī)管理系統(tǒng)與ZKEYS公有云管理系統(tǒng)對(duì)比-創(chuàng)新互聯(lián)
- ionic2中如何使用自動(dòng)生成器-創(chuàng)新互聯(lián)
- Android項(xiàng)目中如何使用adapter對(duì)數(shù)據(jù)進(jìn)行處理-創(chuàng)新互聯(lián)
- ASP.NETDatagridview自動(dòng)換行的方法教程-創(chuàng)新互聯(lián)
- SQL如何使用分類語(yǔ)句-創(chuàng)新互聯(lián)
- UniDAC使用教程(三):主從關(guān)系-創(chuàng)新互聯(lián)
- TreeList用含有樹(shù)形結(jié)構(gòu)的數(shù)據(jù)源綁定顯示-創(chuàng)新互聯(lián)

- 哪些因素會(huì)影響關(guān)鍵詞優(yōu)化排名 2022-12-03
- SEO關(guān)鍵詞優(yōu)化效果不顯著應(yīng)該重視什么內(nèi)容? 2015-03-24
- 創(chuàng)新互聯(lián)分享網(wǎng)站關(guān)鍵詞優(yōu)化的技巧 2018-01-03
- 成都如何估算關(guān)鍵詞優(yōu)化難度 2023-03-04
- 需要網(wǎng)站關(guān)鍵詞優(yōu)化的網(wǎng)站在建設(shè)時(shí)需要注意什么呢 2016-10-30
- 網(wǎng)站優(yōu)化:seo關(guān)鍵詞優(yōu)化小技巧有哪些? 2023-03-31
- 品牌關(guān)鍵詞優(yōu)化的作用是什么? 2015-07-18
- 網(wǎng)站要想發(fā)展好,關(guān)鍵詞優(yōu)化建設(shè)要趁早! 2022-08-06
- 網(wǎng)站關(guān)鍵詞優(yōu)化人員應(yīng)該具備哪些能力和素質(zhì)呢 2016-10-30
- 為什么要做長(zhǎng)尾關(guān)鍵詞優(yōu)化? 2016-11-08
- 關(guān)鍵詞優(yōu)化和B2B推廣的對(duì)比 2016-11-02
- 運(yùn)營(yíng)人必知的SEO優(yōu)化實(shí)用技巧——關(guān)鍵詞優(yōu)化 2016-09-01