Spark筆記整理(五):SparkRDD持久化、廣播變量和累加器
[TOC]
成都創(chuàng)新互聯(lián)公司服務(wù)項(xiàng)目包括城口網(wǎng)站建設(shè)、城口網(wǎng)站制作、城口網(wǎng)頁(yè)制作以及城口網(wǎng)絡(luò)營(yíng)銷策劃等。多年來(lái),我們專注于互聯(lián)網(wǎng)行業(yè),利用自身積累的技術(shù)優(yōu)勢(shì)、行業(yè)經(jīng)驗(yàn)、深度合作伙伴關(guān)系等,向廣大中小型企業(yè)、政府機(jī)構(gòu)等提供互聯(lián)網(wǎng)行業(yè)的解決方案,城口網(wǎng)站推廣取得了明顯的社會(huì)效益與經(jīng)濟(jì)效益。目前,我們服務(wù)的客戶以成都為中心已經(jīng)輻射到城口省份的部分城市,未來(lái)相信會(huì)繼續(xù)擴(kuò)大服務(wù)區(qū)域并繼續(xù)獲得客戶的支持與信任!
Spark RDD持久化
RDD持久化工作原理
Spark非常重要的一個(gè)功能特性就是可以將RDD持久化在內(nèi)存中。當(dāng)對(duì)RDD執(zhí)行持久化操作時(shí),每個(gè)節(jié)點(diǎn)都會(huì)將自己操作的RDD的partition持久化到內(nèi)存中,并且在之后對(duì)該RDD的反復(fù)使用中,直接使用內(nèi)存緩存的partition。這樣的話,對(duì)于針對(duì)一個(gè)RDD反復(fù)執(zhí)行多個(gè)操作的場(chǎng)景,就只要對(duì)RDD計(jì)算一次即可,后面直接使用該RDD,而不需要反復(fù)計(jì)算多次該RDD。
巧妙使用RDD持久化,甚至在某些場(chǎng)景下,可以將spark應(yīng)用程序的性能提升10倍。對(duì)于迭代式算法和快速交互式應(yīng)用來(lái)說(shuō),RDD持久化,是非常重要的。
要持久化一個(gè)RDD,只要調(diào)用其cache()或者persist()方法即可。在該RDD第一次被計(jì)算出來(lái)時(shí),就會(huì)直接緩存在每個(gè)節(jié)點(diǎn)中。而且Spark的持久化機(jī)制還是自動(dòng)容錯(cuò)的,如果持久化的RDD的任何partition丟失了,那么Spark會(huì)自動(dòng)通過(guò)其源RDD,使用transformation操作重新計(jì)算該partition。
cache()和persist()的區(qū)別在于,cache()是persist()的一種簡(jiǎn)化方式,cache()的底層就是調(diào)用的persist()的無(wú)參版本,同時(shí)就是調(diào)用persist(MEMORY_ONLY),將數(shù)據(jù)持久化到內(nèi)存中。如果需要從內(nèi)存中去除緩存,那么可以使用unpersist()方法。
RDD持久化使用場(chǎng)景
1、第一次加載大量的數(shù)據(jù)到RDD中
2、頻繁的動(dòng)態(tài)更新RDD Cache數(shù)據(jù),不適合使用Spark Cache、Spark lineage
RDD持久化策略

持久化策略的選擇
? 默認(rèn)情況下,性能最高的當(dāng)然是MEMORY_ONLY,但前提是你的內(nèi)存必須足夠足夠大,可以綽綽有余地存放下整個(gè)RDD的所有數(shù)據(jù)。因?yàn)椴贿M(jìn)行序列化與反序列化操作,就避免了這部分的性能開(kāi)銷;對(duì)這個(gè)RDD的后續(xù)算子操作,都是基于純內(nèi)存中的數(shù)據(jù)的操作,不需要從磁盤文件中讀取數(shù)據(jù),性能也很高;而且不需要復(fù)制一份數(shù)據(jù)副本,并遠(yuǎn)程傳送到其他節(jié)點(diǎn)上。但是這里必須要注意的是,在實(shí)際的生產(chǎn)環(huán)境中,恐怕能夠直接用這種策略的場(chǎng)景還是有限的,如果RDD中數(shù)據(jù)比較多時(shí)(比如幾十億),直接用這種持久化級(jí)別,會(huì)導(dǎo)致JVM的OOM內(nèi)存溢出異常。
? 如果使用MEMORY_ONLY級(jí)別時(shí)發(fā)生了內(nèi)存溢出,那么建議嘗試使用MEMORY_ONLY_SER級(jí)別。該級(jí)別會(huì)將RDD數(shù)據(jù)序列化后再保存在內(nèi)存中,此時(shí)每個(gè)partition僅僅是一個(gè)字節(jié)數(shù)組而已,大大減少了對(duì)象數(shù)量,并降低了內(nèi)存占用。這種級(jí)別比MEMORY_ONLY多出來(lái)的性能開(kāi)銷,主要就是序列化與反序列化的開(kāi)銷。但是后續(xù)算子可以基于純內(nèi)存進(jìn)行操作,因此性能總體還是比較高的。此外,可能發(fā)生的問(wèn)題同上,如果RDD中的數(shù)據(jù)量過(guò)多的話,還是可能會(huì)導(dǎo)致OOM內(nèi)存溢出的異常。
? 如果純內(nèi)存的級(jí)別都無(wú)法使用,那么建議使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因?yàn)榧热坏搅诉@一步,就說(shuō)明RDD的數(shù)據(jù)量很大,內(nèi)存無(wú)法完全放下。序列化后的數(shù)據(jù)比較少,可以節(jié)省內(nèi)存和磁盤的空間開(kāi)銷。同時(shí)該策略會(huì)優(yōu)先盡量嘗試將數(shù)據(jù)緩存在內(nèi)存中,內(nèi)存緩存不下才會(huì)寫入磁盤。
? 通常不建議使用DISK_ONLY和后綴為_(kāi)2的級(jí)別:因?yàn)橥耆诖疟P文件進(jìn)行數(shù)據(jù)的讀寫,會(huì)導(dǎo)致性能急劇降低,有時(shí)還不如重新計(jì)算一次所有RDD。后綴為_(kāi)2的級(jí)別,必須將所有數(shù)據(jù)都復(fù)制一份副本,并發(fā)送到其他節(jié)點(diǎn)上,數(shù)據(jù)復(fù)制以及網(wǎng)絡(luò)傳輸會(huì)導(dǎo)致較大的性能開(kāi)銷,除非是要求作業(yè)的高可用性,否則不建議使用。
測(cè)試案例
測(cè)試代碼如下:
package cn.xpleaf.bigdata.spark.scala.core.p3
import org.apache.log4j.{Level, Logger}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
/**
* Spark RDD的持久化
*/
object _01SparkPersistOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName(_01SparkPersistOps.getClass.getSimpleName())
val sc = new SparkContext(conf)
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
var start = System.currentTimeMillis()
val linesRDD = sc.textFile("D:/data/spark/sequences.txt")
// linesRDD.cache()
// linesRDD.persist(StorageLevel.MEMORY_ONLY)
// 執(zhí)行第一次RDD的計(jì)算
val retRDD = linesRDD.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
// retRDD.cache()
// retRDD.persist(StorageLevel.DISK_ONLY)
retRDD.count()
println("第一次計(jì)算消耗的時(shí)間:" + (System.currentTimeMillis() - start) + "ms")
// 執(zhí)行第二次RDD的計(jì)算
start = System.currentTimeMillis()
// linesRDD.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).count()
retRDD.count()
println("第二次計(jì)算消耗的時(shí)間:" + (System.currentTimeMillis() - start) + "ms")
// 持久化使用結(jié)束之后,要想卸載數(shù)據(jù)
// linesRDD.unpersist()
sc.stop()
}
}設(shè)置相關(guān)的持久化策略,再觀察執(zhí)行時(shí)間就可以有一個(gè)較為直觀的理解。
共享變量
提供了兩種有限類型的共享變量,廣播變量和累加器。
介紹之前,先直接看下面一個(gè)例子:
package cn.xpleaf.bigdata.spark.scala.core.p3
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
/**
* 共享變量
* 我們?cè)赿irver中聲明的這些局部變量或者成員變量,可以直接在transformation中使用,
* 但是經(jīng)過(guò)transformation操作之后,是不會(huì)將最終的結(jié)果重新賦值給dirver中的對(duì)應(yīng)的變量。
* 因?yàn)橥ㄟ^(guò)action,觸發(fā)了transformation的操作,transformation的操作,都是通過(guò)
* DAGScheduler將代碼打包 序列化 交由TaskScheduler傳送到各個(gè)Worker節(jié)點(diǎn)中的Executor去執(zhí)行,
* 在transformation中執(zhí)行的這些變量,是自己節(jié)點(diǎn)上的變量,不是dirver上最初的變量,我們只不過(guò)是將
* driver上的對(duì)應(yīng)的變量拷貝了一份而已。
*
*
* 這個(gè)案例也反映出,我們需要有一些操作對(duì)應(yīng)的變量,在driver和executor上面共享
*
* spark給我們提供了兩種解決方案——兩種共享變量
* 廣播變量
* 累加器
*/
object _02SparkShareVariableOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName(_01SparkPersistOps.getClass.getSimpleName())
val sc = new SparkContext(conf)
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
val linesRDD = sc.textFile("D:/data/spark/hello.txt")
val wordsRDD = linesRDD.flatMap(_.split(" "))
var num = 0
val parisRDD = wordsRDD.map(word => {
num += 1
println("map--->num = " + num)
(word, 1)
})
val retRDD = parisRDD.reduceByKey(_ + _)
println("num = " + num)
retRDD.foreach(println)
println("num = " + num)
sc.stop()
}
}輸出結(jié)果如下:
num = 0
map--->num = 1
map--->num = 1
map--->num = 2
map--->num = 2
map--->num = 3
map--->num = 4
(hello,3)
(you,1)
(me,1)
(he,1)
num = 0廣播變量
Spark的另一種共享變量是廣播變量。通常情況下,當(dāng)一個(gè)RDD的很多操作都需要使用driver中定義的變量時(shí),每次操作,driver都要把變量發(fā)送給worker節(jié)點(diǎn)一次,如果這個(gè)變量中的數(shù)據(jù)很大的話,會(huì)產(chǎn)生很高的傳輸負(fù)載,導(dǎo)致執(zhí)行效率降低。使用廣播變量可以使程序高效地將一個(gè)很大的只讀數(shù)據(jù)發(fā)送給多個(gè)worker節(jié)點(diǎn),而且對(duì)每個(gè)worker節(jié)點(diǎn)只需要傳輸一次,每次操作時(shí)executor可以直接獲取本地保存的數(shù)據(jù)副本,不需要多次傳輸。
這樣理解, 一個(gè)worker中的executor,有5個(gè)task運(yùn)行,假如5個(gè)task都需要這從份共享數(shù)據(jù),就需要向5個(gè)task都傳遞這一份數(shù)據(jù),那就十分浪費(fèi)網(wǎng)絡(luò)資源和內(nèi)存資源了。使用了廣播變量后,只需要向該worker傳遞一次就可以了。
創(chuàng)建并使用廣播變量的過(guò)程如下:
在一個(gè)類型T的對(duì)象obj上使用SparkContext.brodcast(obj)方法,創(chuàng)建一個(gè)Broadcast[T]類型的廣播變量,obj必須滿足Serializable。 通過(guò)廣播變量的.value()方法訪問(wèn)其值。 另外,廣播過(guò)程可能由于變量的序列化時(shí)間過(guò)程或者序列化變量的傳輸過(guò)程過(guò)程而成為瓶頸,而Spark Scala中使用的默認(rèn)的Java序列化方法通常是低效的,因此可以通過(guò)spark.serializer屬性為不同的數(shù)據(jù)類型實(shí)現(xiàn)特定的序列化方法(如Kryo)來(lái)優(yōu)化這一過(guò)程。
測(cè)試代碼如下:
package cn.xpleaf.bigdata.spark.scala.core.p3
import org.apache.log4j.{Level, Logger}
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.{SparkConf, SparkContext}
/**
* 使用Spark廣播變量
*
* 需求:
* 用戶表:
* id name age gender(0|1)
*
* 要求,輸出用戶信息,gender必須為男或者女,不能為0,1
*/
object _03SparkBroadcastOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName(_01SparkPersistOps.getClass.getSimpleName())
val sc = new SparkContext(conf)
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
val userList = List(
"001,劉向前,18,0",
"002,馮 劍,28,1",
"003,李志杰,38,0",
"004,郭 鵬,48,2"
)
val genderMap = Map("0" -> "女", "1" -> "男")
val genderMapBC:Broadcast[Map[String, String]] = sc.broadcast(genderMap)
val userRDD = sc.parallelize(userList)
val retRDD = userRDD.map(info => {
val prefix = info.substring(0, info.lastIndexOf(",")) // "001,劉向前,18"
val gender = info.substring(info.lastIndexOf(",") + 1)
val genderMapValue = genderMapBC.value
val newGender = genderMapValue.getOrElse(gender, "男")
prefix + "," + newGender
})
retRDD.foreach(println)
sc.stop()
}
}輸出結(jié)果如下:
001,劉向前,18,女
003,李志杰,38,女
002,馮 劍,28,男
004,郭 鵬,48,男下面是一個(gè)更加精簡(jiǎn)的案例:
package cn.xpleaf.spark.p5
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author xpleaf
* @date 2019/1/10 4:53 PM
*/
object SampleSpark {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${SampleSpark.getClass.getSimpleName}")
.setMaster("local[2]")
val sc = new SparkContext(conf)
val genderMap = Map("0" -> "女", "1" -> "男")
val genderMapBC:Broadcast[Map[String, String]] = sc.broadcast(genderMap)
val rdd = sc.parallelize(Seq(("0", "Amy"), ("0", "Spring"), ("0", "Sunny"), ("1", "Mike"), ("1", "xpleaf")))
val retRDD = rdd.map{
case (sex, name) =>
val genderMapValue = genderMapBC.value
(genderMapValue.getOrElse(sex, "男"), name)
}
retRDD.foreach(println)
sc.stop()
}
}
輸出結(jié)果如下:
(女,Amy)
(女,Sunny)
(女,Spring)
(男,Mike)
(男,xpleaf)當(dāng)然這個(gè)案例只是演示一下代碼的使用,并不能看出其運(yùn)行的機(jī)制。
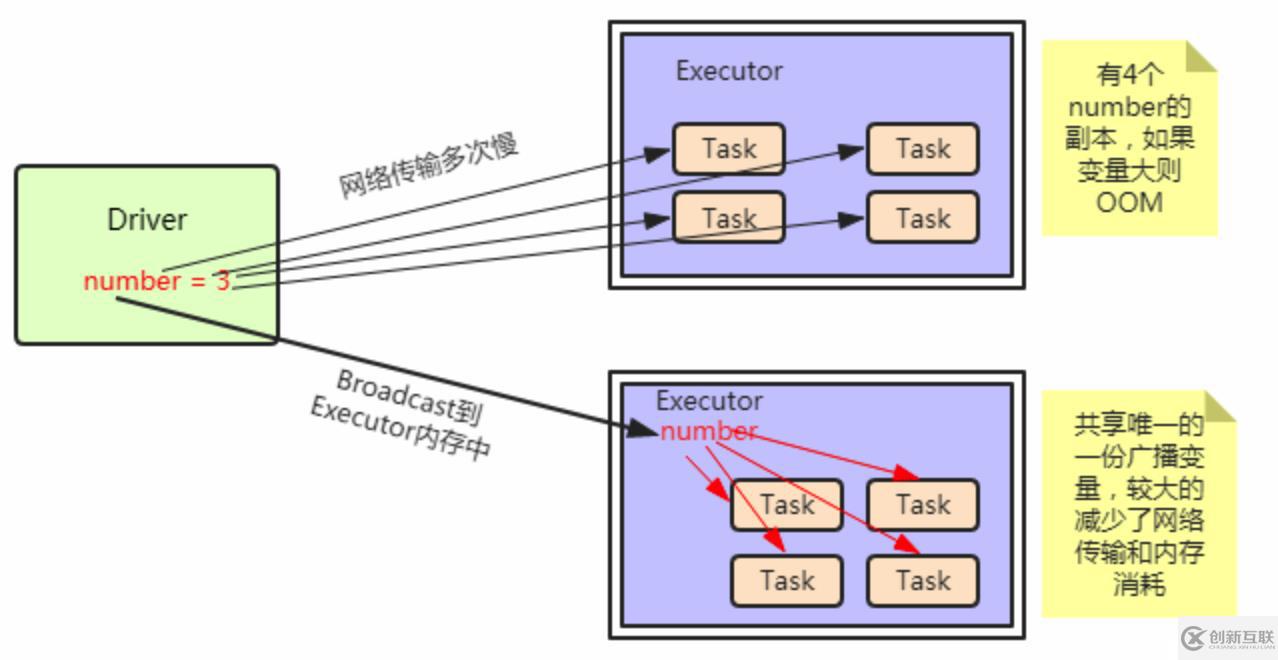
不過(guò)可以分析一下其原理,假如在執(zhí)行map操作時(shí),在某個(gè)Worker的一個(gè)Executor上有分配5個(gè)task來(lái)進(jìn)行計(jì)算,在不使用廣播變量的情況下,因?yàn)镈river會(huì)將我們的代碼通過(guò)DAGScheduler劃分會(huì)不同stage,交由taskScheduler,taskScheduler再將封裝好的一個(gè)個(gè)task分發(fā)到Worker的Excutor中,也就是說(shuō),這個(gè)過(guò)程當(dāng)中,我們的genderMap也會(huì)被封裝到這個(gè)task中,顯然這個(gè)過(guò)程的粒度是task級(jí)別的,每個(gè)task都會(huì)封裝一個(gè)genderMap,在該變量數(shù)據(jù)量不大的情況下,是沒(méi)有問(wèn)題的,然后,當(dāng)數(shù)據(jù)量很大時(shí),同時(shí)向一個(gè)Excutor上傳遞5份這樣相同的數(shù)據(jù),這是很浪費(fèi)網(wǎng)絡(luò)中的帶寬資源的;廣播變量的使用可以避免這一問(wèn)題的發(fā)生,將genderMap廣播出去之后,其只需要發(fā)送給Excutor即可,它會(huì)保存在Excutor的BlockManager中,此時(shí),Excutor下面的task就可以共享這個(gè)變量了,這顯然可以帶來(lái)一定性能的提升。
這里放上從網(wǎng)上找的一個(gè)圖,就不自己畫了,原理跟上面講的是一樣的:
累加器
Spark提供的Accumulator,主要用于多個(gè)節(jié)點(diǎn)對(duì)一個(gè)變量進(jìn)行共享性的操作。Accumulator只提供了累加的功能。但是確給我們提供了多個(gè)task對(duì)一個(gè)變量并行操作的功能。但是task只能對(duì)Accumulator進(jìn)行累加操作,不能讀取它的值。只有Driver程序可以讀取Accumulator的值。
非常類似于在MR中的一個(gè)Counter計(jì)數(shù)器,主要用于統(tǒng)計(jì)各個(gè)程序片段被調(diào)用的次數(shù),和整體進(jìn)行比較,來(lái)對(duì)數(shù)據(jù)進(jìn)行一個(gè)評(píng)估。
測(cè)試代碼如下:
package cn.xpleaf.bigdata.spark.scala.core.p3
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Spark共享變量之累加器Accumulator
*
* 需要注意的是,累加器的執(zhí)行必須需要Action觸發(fā)
*/
object _04SparkAccumulatorOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName(_01SparkPersistOps.getClass.getSimpleName())
val sc = new SparkContext(conf)
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
// 要對(duì)這些變量都*7,同時(shí)統(tǒng)計(jì)能夠被3整除的數(shù)字的個(gè)數(shù)
val list = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13)
val listRDD:RDD[Int] = sc.parallelize(list)
var counter = 0
val counterAcc = sc.accumulator[Int](0)
val mapRDD = listRDD.map(num => {
counter += 1
if(num % 3 == 0) {
counterAcc.add(1)
}
num * 7
})
// 下面這種操作又執(zhí)行了一次RDD計(jì)算,所以可以考慮上面的方案,減少一次RDD的計(jì)算
// val ret = mapRDD.filter(num => num % 3 == 0).count()
mapRDD.foreach(println)
println("counter===" + counter)
println("counterAcc===" + counterAcc.value)
sc.stop()
}
}輸出結(jié)果如下:
49
56
7
63
14
70
21
77
28
84
35
91
42
counter===0
counterAcc===4下面是一個(gè)更加精簡(jiǎn)的案例:
package cn.xpleaf.spark.p5
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author xpleaf
* @date 2019/1/10 6:14 PM
*/
object SampleSpark2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${SampleSpark2.getClass.getSimpleName}")
.setMaster("local[2]")
val sc = new SparkContext(conf)
// 累加器,用來(lái)統(tǒng)計(jì)rdd中的偶數(shù)
val counterAcc = sc.accumulator[Int](0)
// 普通的counter變量
var counter = 0
val rdd = sc.parallelize(List(1, 2, 3, 4, 5, 6))
// 需要觸發(fā)transformation的執(zhí)行
rdd.map {
num =>
if (num % 2 == 0) {
// 累加器和普通counter變量都加1
counterAcc.add(1)
counter += 1
}
}.count()
println(s"counterAcc: ${counterAcc.value}, counter: $counter")
sc.stop()
}
}輸出結(jié)果如下:
counterAcc: 3, counter: 0
網(wǎng)站欄目:Spark筆記整理(五):SparkRDD持久化、廣播變量和累加器
文章來(lái)源:http://www.chinadenli.net/article20/jdhpjo.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供定制開(kāi)發(fā)、手機(jī)網(wǎng)站建設(shè)、網(wǎng)站策劃、動(dòng)態(tài)網(wǎng)站、建站公司、網(wǎng)站收錄
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)

- SEO優(yōu)化之代碼優(yōu)化與標(biāo)簽優(yōu)化 2015-02-08
- 企業(yè)網(wǎng)站標(biāo)簽優(yōu)化有哪些作用? 2023-04-07
- 淺析網(wǎng)站tags標(biāo)簽優(yōu)化的重要性 2022-07-27
- HTML標(biāo)簽優(yōu)化的注意事項(xiàng)有哪些 2020-09-22
- 網(wǎng)站優(yōu)化中細(xì)節(jié):注意h1、h2、h3、strong標(biāo)簽優(yōu)化 2021-07-26
- 網(wǎng)站Tags標(biāo)簽優(yōu)化的幾大技巧 2022-06-08
- 新手seo不知道的優(yōu)化秘訣:tag標(biāo)簽優(yōu)化 2020-08-25
- 現(xiàn)網(wǎng)站建設(shè)分析網(wǎng)站Tag標(biāo)簽優(yōu)化幾點(diǎn)如下: 2022-06-04
- 網(wǎng)站標(biāo)簽優(yōu)化技巧 2016-11-03
- SEO標(biāo)簽優(yōu)化,網(wǎng)站流量快速提升! 2023-04-04
- 網(wǎng)站的優(yōu)化-網(wǎng)站代碼標(biāo)簽優(yōu)化有哪些技巧 2014-10-11
- 做好TAG標(biāo)簽優(yōu)化,讓更多長(zhǎng)尾關(guān)鍵詞獲取排名! 2016-11-07