如何進行大數據分布式的深度學習
本篇文章為大家展示了如何進行大數據分布式的深度學習,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
目前成都創(chuàng)新互聯已為數千家的企業(yè)提供了網站建設、域名、網頁空間、網站托管、服務器租用、企業(yè)網站設計、霞山網站維護等服務,公司將堅持客戶導向、應用為本的策略,正道將秉承"和諧、參與、激情"的文化,與客戶和合作伙伴齊心協力一起成長,共同發(fā)展。
為什么要進行分布式地訓練?
一方面使不得已而為之,比如:數據量太大,數據無法加載或者模型太復雜,一個GPU放不下參數。 另一方面,可以使用分布式提高訓練速度
分布式訓練策略
模型并行:用于模型過大的情況,需要把模型的不同層放在不同節(jié)點或者GPU上,計算效率不高,不常用。
數據并行:把數據分成多份,每份數據單獨進行前向計算和梯度更新,效率高,較常用。
分布式并行模式
同步訓練:所有進程前向完成后統(tǒng)一計算梯度,統(tǒng)一反向更新。
異步訓練:每個進程計算自己的梯度,并拷貝主節(jié)點的參數進行更新,容易造成錯亂,陷入次優(yōu)解。
分布式訓練架構
Parameter Server 參數服務器
集群中有一個parameter server和多個worker,server需要等待所有節(jié)點計算完畢統(tǒng)一計算梯度,在server上更新參數,之后把新的參數廣播給worker。 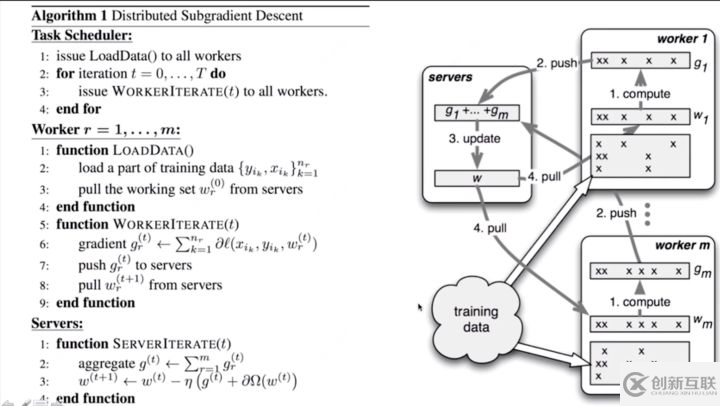
基本流程如下:
woker加載數據,進行訓練,更新梯度
將梯度上傳到server
server進行聚合梯度并且更新參數
woker進行拉取最新的參數,進行下一次訓練
Ring All-Reduce
只有worker,所有worker形成一個閉環(huán),接受上家的梯度,再把累加好的梯度傳給下家,最終計算完成后更新整個環(huán)上worker的梯度(這樣所有worker上的梯度就相等了),然后求梯度反向傳播。比PS架構要高效。
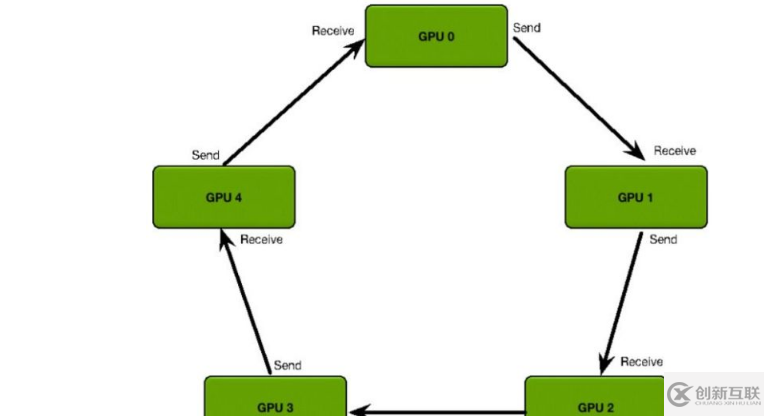
算法主要分兩步:
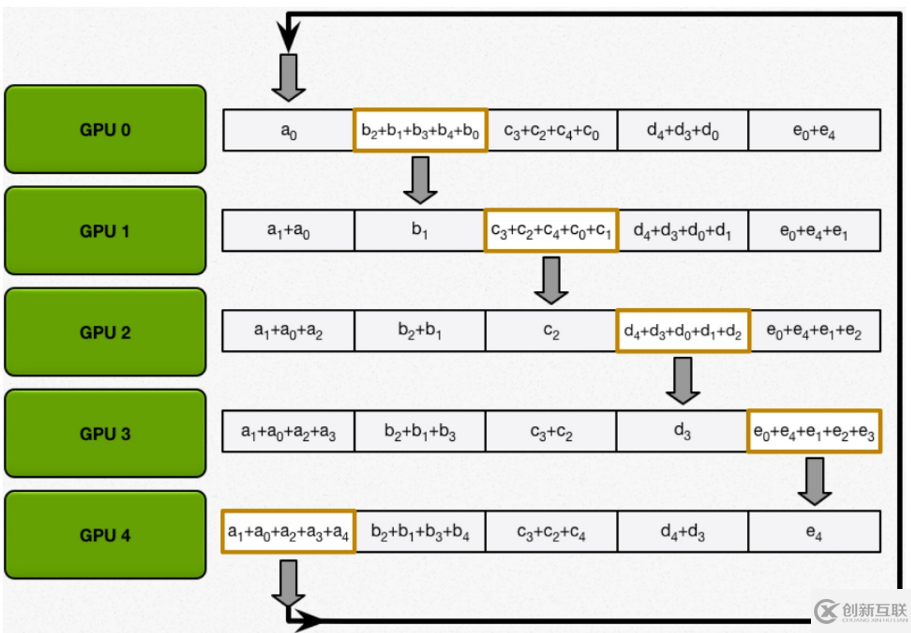
scatter-reduce:會逐步交換彼此的梯度并融合,最后每個 GPU 都會包含完整融合梯度的一部分。
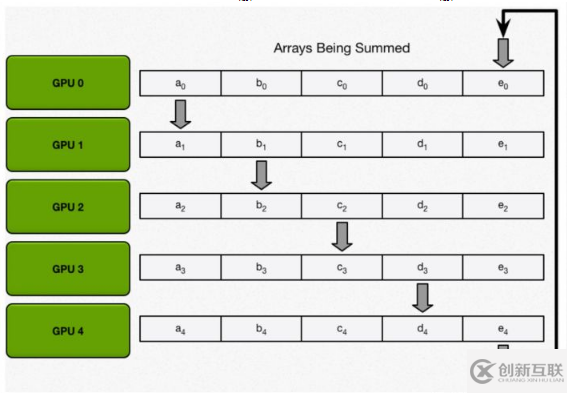
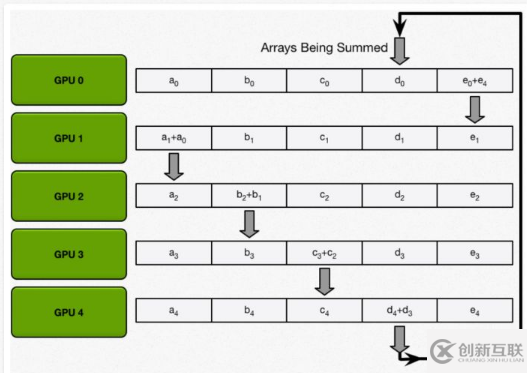
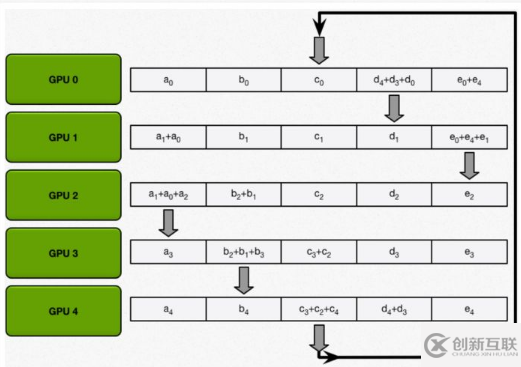
allgather:GPU 會逐步交換彼此不完整的融合梯度,最后所有 GPU 都會得到完整的融合梯度
#分布式深度學習框架
Elephas https://github.com/maxpumperla/elephas
Elephas是Keras的擴展,它使您可以使用Spark大規(guī)模運行分布式深度學習模型。 原理上,Elephas如下圖所示: 
Elephas使用Spark的RDD和Dataframe實現了一個架構在Keras之上的數據并行算法。Keras模型在Spark Driver上進行初始化,之后進行序列化,連同數據和廣播模型參數一起發(fā)送給Spark Worker。Spark Worker對模型進行反序列化,然后訓練數據塊,并將訓練后的梯度發(fā)回Driver,Driver上的優(yōu)化器進行同步或者異步地更新梯度,之后更新主模型。 總結:
使用十分簡單,
spark_model = SparkModel(model, frequency='epoch', mode='asynchronous')一行代碼就可以實現其功能有使用者發(fā)現Driver會出現存儲數據失敗的情況,在相同epoch下,準確率大幅度降低
由于采用PS架構,Driver的內存要求比較高,官方要求至少1G內存
TensorFlowOnSpark https://github.com/yahoo/TensorFlowOnSpark
TensorFlowOnSpark由Yahoo開發(fā),用于在Yahoo私有云中的Hadoop集群上進行大規(guī)模分布式深度學習。 TensorFlowOnSpark具有一些重要的優(yōu)勢(請參閱我們的博客):
只需不到10行代碼更改即可輕松遷移現有TensorFlow程序。
支持所有TensorFlow功能:同步/異步訓練,模型/數據并行性,推理和TensorBoard。
服務器到服務器直接通信在可用時可以更快地學習。
允許HDFS上的數據集以及由Spark推送或由TensorFlow推送的其他來源。
輕松與您現有的Spark數據處理管道集成。
輕松部署在云或本地以及CPU或GPU上。
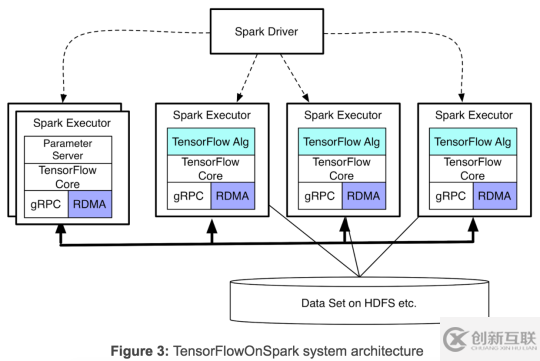
總結:
TensorFlowOnSpark依然是使用參數服務器與數據并行的結構
IO耗費時間多,有用戶反映For 10 epochs of training, it took about 8.5 hours on a Yarn-Spark cluster with 2 nodes and 2 GPU, but the I/O took more than 3 hours.
dist-keras https://github.com/cerndb/dist-keras
dist-keras(DK)是在Apache Spark和Keras之上構建的分布式深度學習框架,其目標是使用分布式機器學習算法來顯著減少培訓時間。設計框架的方式是,開發(fā)人員可以輕松實現新的分布式優(yōu)化器,從而使人們能夠專注于研究和模型開發(fā)。
遵循大型分布式深度網絡論文中所述的數據并行方法。在此范例中,模型的副本分布在多個“訓練器”上,并且每個模型副本都將在數據集的不同分區(qū)上進行訓練。每次梯度更新后,梯度(或所有網絡權重,取決于實現細節(jié))將與參數服務器通信。參數服務器負責處理所有Worker的梯度更新,并將所有梯度更新合并到單個主模型中,該模型將在訓練過程完成后返回給用戶。
總結:
使用簡單,功能少,主要是實現了分布式的optimizer
個人開發(fā),目前已經項目已經歸檔,不再活躍開發(fā)
Horovod https://github.com/horovod/horovod
Horovod是Uber開源的又一個深度學習工具,它的發(fā)展吸取了Facebook "Training ImageNet In 1 Hour" 與百度 "Ring Allreduce" 的優(yōu)點,可為用戶實現分布式訓練提供幫助。本文將簡要介紹如何使用Horovod配合pytorch更高效地進行分布式訓練。 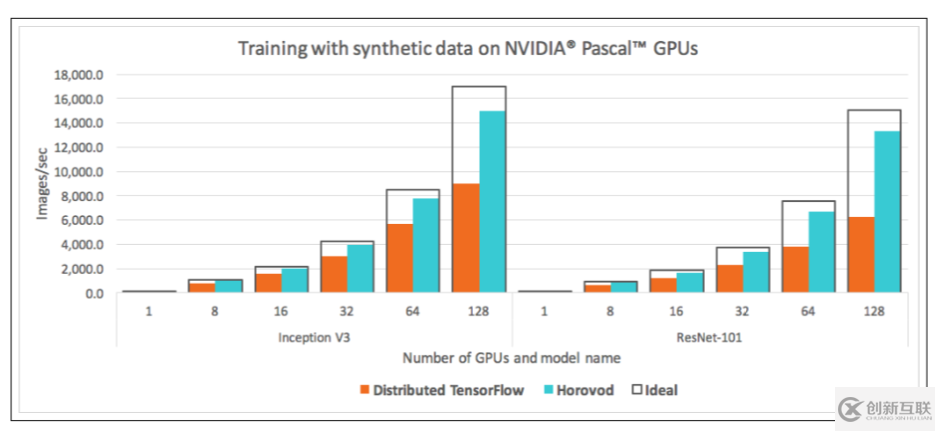
總結:
Uber開發(fā),社區(qū)活躍
支持多個深度學習框架,TensorFlow以及Pytorch和Keras
horovod的分布式貌似只支持同步更新式的數據并行,模型并行和異步更新式的數據并行都不支持
determined-ai https://determined.ai/product/
determined AI 是一個深度學習分布式訓練平臺,從算法上講,determined架構在horovod上,使用horovod來進行深度學習。除此之外,使用更高級的超參數調整,從而找到更好的模型。借助智能的GPU調度功能,提高GPU調度效率提高性能。以及安裝方便,圖形界面功能齊全。 
Angel https://github.com/Angel-ML/angel
Angel 是一個基于參數服務器(Parameter Server)理念開發(fā)的高性能分布式機器學習平臺,它基于騰訊內部的海量數據進行了反復的調優(yōu),并具有廣泛的適用性和穩(wěn)定性,模型維度越高,優(yōu)勢越明顯。 Angel 由騰訊和北京大學聯合開發(fā),兼顧了工業(yè)界的高可用性和學術界的創(chuàng)新性。
Angel 的核心設計理念圍繞模型。它將高維度的大模型合理切分到多個參數服務器節(jié)點,并通過高效的模型更新接口和運算函數,以及靈活的同步協議,輕松實現各種高效的機器學習算法。
Angel 基于 Java 和 Scala 開發(fā),能在社區(qū)的 Yarn 上直接調度運行,并基于 PS Service ,支持 Spark on Angel ,未來將會支持圖計算和深度學習框架集成。 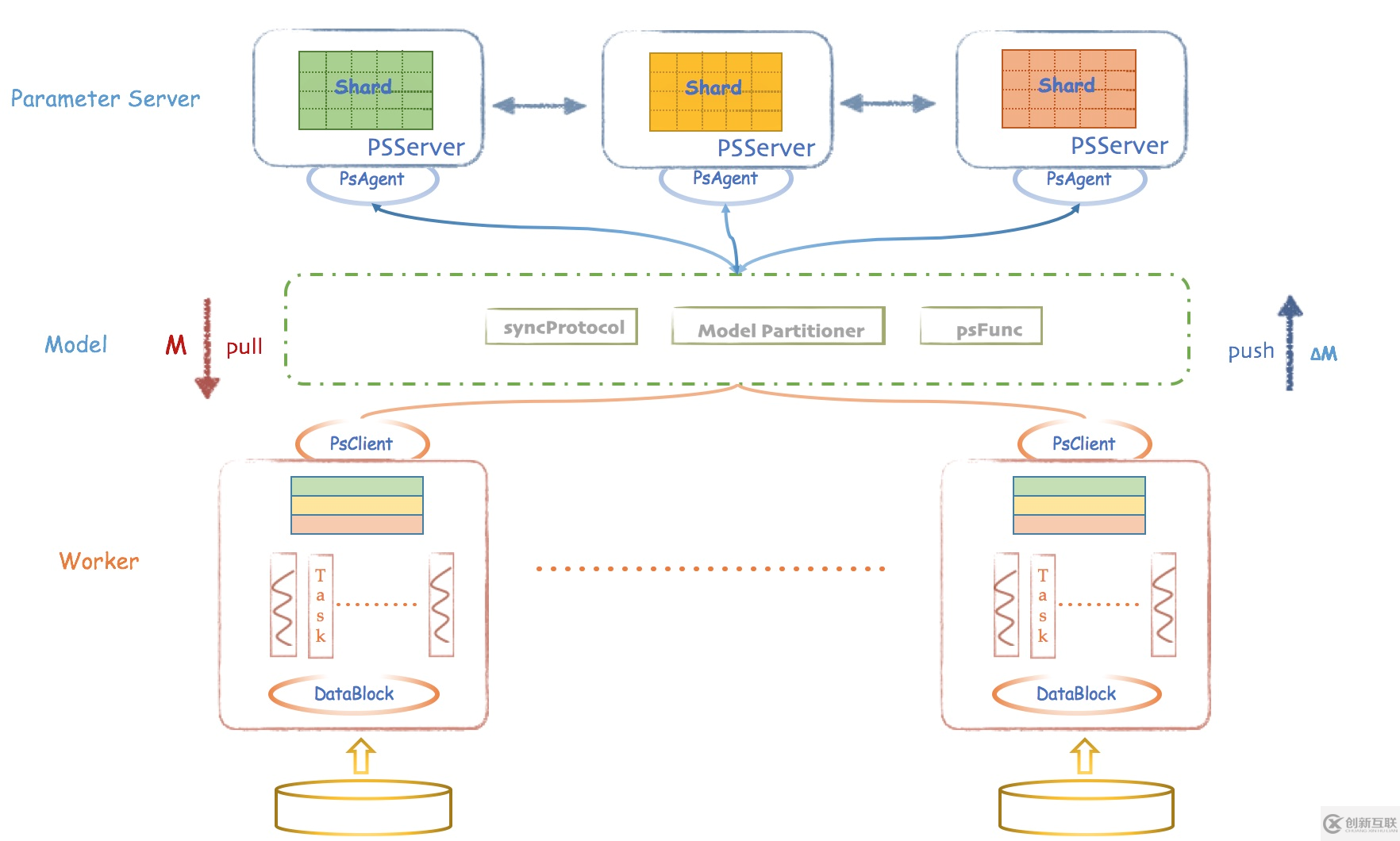 總結:
總結:
國產,社區(qū)活躍,但是目前算法支持少。
使用Scala進行編程,而不借助于Python的深度學習框架
支持多個參數服務器模型
BigDL
BigDL,是 Intel 開源的一個基于 Apache Spark 的分布式深度學習庫。使用 BigDL ,用戶可以將他們的深度學習應用程序作為標準的 Spark 程序,它可以直接運行在現有的 Spark 或 Hadoop 集群之上。 特性:
豐富的深度學習支持。BigDL 模仿 Torch,提供對深度學習的全方位支持,包括數值計算(通過Tensor)和高層次神經網絡。此外,用戶可以使用 BigDL 將預訓練的 Caffe 或 Torch 模型加載到 Spark 程序中。
極其高的性能。為了達到高性能,BigDL 在每個 Spark 任務中使用 Intel MKL和多線程編程。因此,它比單節(jié)點 Xeon 上的開箱即用的 Caffe、Torch 或 TensorFlow 快幾個數量級。
有效地橫向擴展。 BigDL 可以通過利用 Apache Spark 以及高效實施同步 SGD, 全面減少 Spark 上的通信,有效地向外擴展,以“大數據規(guī)模”執(zhí)行數據分析。
上述內容就是如何進行大數據分布式的深度學習,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注創(chuàng)新互聯行業(yè)資訊頻道。
分享名稱:如何進行大數據分布式的深度學習
網頁鏈接:http://www.chinadenli.net/article2/jdhsic.html
成都網站建設公司_創(chuàng)新互聯,為您提供定制網站、微信公眾號、小程序開發(fā)、營銷型網站建設、網頁設計公司、ChatGPT
聲明:本網站發(fā)布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創(chuàng)新互聯

- 網頁設計公司如何面對越來越成熟的市場競爭 2016-09-29
- 注意網頁設計公司的服務內容、簽約項目 2019-11-14
- 企業(yè)建網站找外包網頁設計公司時應看哪幾點 2015-06-13
- 北京網頁設計公司 2021-05-19
- 【成都網頁設計公司】不同網站需要注意的方面 2023-02-14
- 【成都網頁設計公司】如何讓網站建設別具一格? 2023-03-07
- 福田網頁設計公司選擇難,是因為您沒看這些 2022-08-27
- 成都教育培訓型營銷網頁設計公司哪家好? 2016-10-26
- 成都網頁設計公司:滾動型長頁面怎么設計? 2016-11-02
- 選擇優(yōu)質的成都網頁設計公司需考慮哪些問題 2016-10-09
- 網頁設計公司針對您的業(yè)務的標準 2022-10-27
- 如何尋找專業(yè)的網頁設計公司 2016-11-01