python-xpath如何獲取html文檔的部分內(nèi)容-創(chuàng)新互聯(lián)
小編給大家分享一下python-xpath如何獲取html文檔的部分內(nèi)容,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!

python常用的庫:1.requesuts;2.scrapy;3.pillow;4.twisted;5.numpy;6.matplotlib;7.pygama;8.ipyhton等。
有些時(shí)候我在們需要的用正則提取出html中某一個(gè)部分的文字內(nèi)容,如圖:
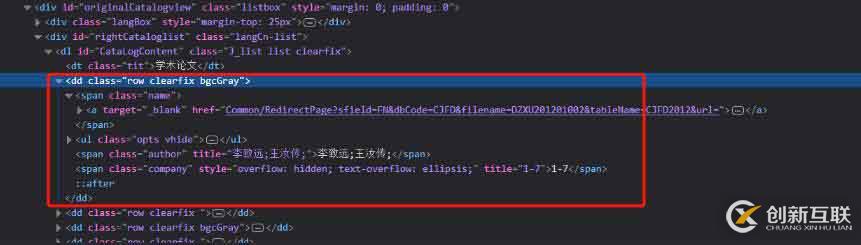
獲取dd部分的html文檔,我們要通過它的一個(gè)屬性去確定他的位置才可以拿到他這個(gè)部分我們可以看到他的這個(gè)屬性class='row clearfix ',然后用xpath去獲取到這部分:
name = tree.xpath("//dd[@class='row clearfix ']")
from lxml import html
import requests
url = 'http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pageIdx=0&pcode=CJFD'
res = requests.get(url)
tree = html.fromstring(res.text)
name = tree.xpath("//dd[@class='row clearfix ']")
print(name)如果直接打印他是不能夠出來的,

我們需要對(duì)Element進(jìn)行處理,用到name1 = html.tostring(name[0]),代碼如下:
from lxml import html
import requests
url = 'http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pageIdx=0&pcode=CJFD'
res = requests.get(url)
tree = html.fromstring(res.text)
name = tree.xpath("//dd[@class='row clearfix ']")
name1 = html.tostring(name[0])
print(name1)打印截圖:

但是大家可以看到里面的等內(nèi)容并不是中文,原因是我們使用tostring方法輸出的是修正后的HTML代碼,但是結(jié)果是bytes類型,在python中bytes類型是不可以進(jìn)行編碼的,需要轉(zhuǎn)換成字符串,使用代碼name1.decode(),此時(shí)我們將bytes類型轉(zhuǎn)換為str(字符串)類型。
那么此時(shí)我們關(guān)鍵是如何將$#26080;此類的符號(hào)轉(zhuǎn)換成漢字!!!那么首先要搞清楚這是什么編碼?這類符號(hào)是HTML、XML 等 SGML 類語言的轉(zhuǎn)義序列。它們不是”編碼“,也就是說我們不能使用utf-8、gbk等編碼進(jìn)行處理,需要使用HTMLParse進(jìn)行處理,完整代碼如下:
from lxml import html
import requests
from html.parser import HTMLParser #導(dǎo)入html解析庫
url = 'http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pageIdx=0&pcode=CJFD'
res = requests.get(url)
tree = html.fromstring(res.text)
name = tree.xpath("//dd[@class='row clearfix ']")
name1 = html.tostring(name[0])
name2 = HTMLParser().unescape(name1.decode())
print(name2)此時(shí)運(yùn)行結(jié)果如下:

以上是“python-xpath如何獲取html文檔的部分內(nèi)容”這篇文章的所有內(nèi)容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內(nèi)容對(duì)大家有所幫助,如果還想學(xué)習(xí)更多知識(shí),歡迎關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道!
當(dāng)前標(biāo)題:python-xpath如何獲取html文檔的部分內(nèi)容-創(chuàng)新互聯(lián)
分享地址:http://www.chinadenli.net/article2/dcssoc.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站維護(hù)、品牌網(wǎng)站設(shè)計(jì)、網(wǎng)站內(nèi)鏈、軟件開發(fā)、網(wǎng)站設(shè)計(jì)、關(guān)鍵詞優(yōu)化
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場,如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來源: 創(chuàng)新互聯(lián)

- 商城網(wǎng)站定制開發(fā)有哪些功能模塊-大連微信開發(fā) 2022-07-15
- 母嬰商城成都網(wǎng)站建設(shè)站定制開發(fā) 2016-11-14
- app定制開發(fā)的具體流程是什么? 2020-12-06
- 網(wǎng)站定制開發(fā)都有哪些特點(diǎn)? 2016-10-29
- 現(xiàn)在的網(wǎng)站開發(fā)中為什么選擇定制開發(fā)主要原因在哪里呢 2016-10-27
- 企業(yè)軟件定制開發(fā)有哪些優(yōu)勢 2023-03-27
- 上海如何快速微信小程序定制開發(fā) 2020-12-17
- 上海直播類APP定制開發(fā)需要多少錢? 2023-03-22
- 網(wǎng)站定制開發(fā)要素及價(jià)格為何差距大 2021-05-28
- 上海網(wǎng)站定制開發(fā)時(shí)網(wǎng)頁排版布局有哪些原則 2020-12-02
- 提高定制開發(fā)網(wǎng)站的核心競爭力 2017-11-25
- 企業(yè)進(jìn)行網(wǎng)站定制開發(fā)之前有哪些準(zhǔn)備要做 2016-11-09