IDEA中怎么運(yùn)行MapReduce程序
IDEA 中怎么運(yùn)行MapReduce 程序,針對(duì)這個(gè)問(wèn)題,這篇文章詳細(xì)介紹了相對(duì)應(yīng)的分析和解答,希望可以幫助更多想解決這個(gè)問(wèn)題的小伙伴找到更簡(jiǎn)單易行的方法。
成都創(chuàng)新互聯(lián)是一家專業(yè)從事網(wǎng)站設(shè)計(jì)、網(wǎng)站建設(shè)的網(wǎng)絡(luò)公司。作為專業(yè)網(wǎng)站建設(shè)公司,成都創(chuàng)新互聯(lián)依托的技術(shù)實(shí)力、以及多年的網(wǎng)站運(yùn)營(yíng)經(jīng)驗(yàn),為您提供專業(yè)的成都網(wǎng)站建設(shè)、全網(wǎng)整合營(yíng)銷推廣及網(wǎng)站設(shè)計(jì)開發(fā)服務(wù)!
1、Idea 本地獨(dú)立模式運(yùn)行 MapReduce
1.1、解壓 Hadoop 和設(shè)置環(huán)境變量
將 Hadoop 解壓本地目錄,例如 C:\Hadoop
設(shè)置環(huán)境變量:
HADOOP_HOME 指向 Hadoop 解壓目錄
HADOOP_USER_NAME : 用戶名,Hadoop 運(yùn)行的用戶名(下一節(jié) 遠(yuǎn)程提交需要,跟 HDFS 集群所用的一樣)
PATH:添加指向 HADOOP_HOME\bin 和 HADOOP_HOME\sbin 的值
重要:Windows 系統(tǒng):Windows 運(yùn)行 Hadoop 需要 winutils.exe 和 hadoop.dll 這兩個(gè)文件:
https://github.com/cdarlint/winutils 下載對(duì)應(yīng) Hadoop 版本的
hadoop.dll 復(fù)制到 C:\Windows\System32
winutils.exe 復(fù)制到 HADOOP_HOME\bin
1.2、新建項(xiàng)目
示例項(xiàng)目在 src/hadoop
選擇 Gradle 或者 Maven 等構(gòu)建工具,添加如下依賴:version 對(duì)應(yīng) Hadoop 的版本。
// https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common compile group: 'org.apache.hadoop', name: 'hadoop-common', version: '3.2.1' // https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client compile group: 'org.apache.hadoop', name: 'hadoop-client', version: '3.2.1'
日志輸出配置:項(xiàng)目/src/main/resource/log4j.properties
log4j.appender.A1.Encoding=UTF-8
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} | %-5.5p | %-16.16t | %-32.32c{1} | %-32.32C %4L | %m%n新建:org.xiao.hadoop.chapter01.WordCount.class :
public class WordCount {
public static class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable ONE = new IntWritable(1);
private final Text word = new Text();
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 按照空格切割字符串,一行一行輸入的
// Context 將輸出內(nèi)容寫入 《Hadoop 權(quán)威指南》P25
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, ONE);
}
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private final IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
// 讀取配置文件
Configuration conf = new Configuration();
// 設(shè)置任務(wù)名稱
Job job = Job.getInstance(conf, "WordCount");
// 設(shè)置運(yùn)行的 jar 包,通過(guò) class 的形式 TODO:驗(yàn)證直接設(shè)置 jar 包
job.setJarByClass(WordCount.class);
// Map 的類,
job.setMapperClass(WordCountMapper.class);
// Reducer 類的設(shè)置
// Combiner 是非必須的,屬于優(yōu)化方案,用于找出每個(gè) Map 的結(jié)果,然后再通過(guò) Reducer 再次聚合
// 作用是減少每個(gè) map 輸出結(jié)果量,有他沒(méi)他最終結(jié)果是一樣的 ,《Hadoop 權(quán)威指南》中文第三版 P35
job.setCombinerClass(WordCountReducer.class);
job.setReducerClass(WordCountReducer.class);
// 設(shè)置輸出的 key--value 的類型,Hadoop 的 org.apache.hadoop.io 包提供了一套可優(yōu)化的網(wǎng)絡(luò)序列化傳輸基本類型。
// 并不直接使用 Java 的內(nèi)嵌類型
// Text 相當(dāng)于 String
job.setOutputKeyClass(Text.class);
// IntWritable 相當(dāng)于 Integer
job.setOutputValueClass(IntWritable.class);
// 設(shè)置輸入文件的路徑,可以直接指定或者通過(guò)傳入?yún)?shù)
FileInputFormat.addInputPath(job, new Path("input/chapter01/WordCount"));
// 設(shè)置輸出文件的存放路徑
FileOutputFormat.setOutputPath(job, new Path("output/chapter01/WordCount"));
// true 表示打印 job 和 Task 的運(yùn)行日志,如果正常運(yùn)行結(jié)束則返回零
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
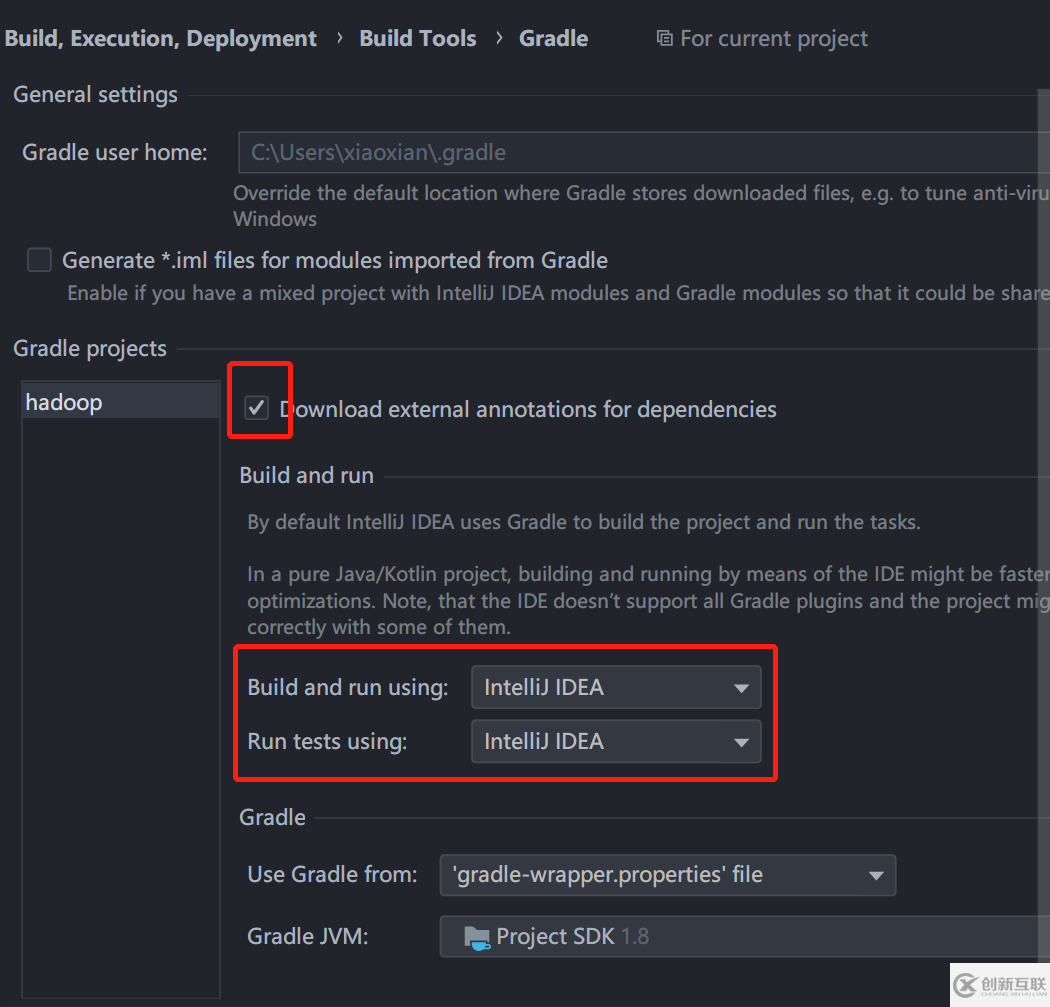
}如果是 Windows 系統(tǒng)和 Gradle 項(xiàng)目,需要打開 Idea 設(shè)置,將 Gradle 的設(shè)置如下,不然日志會(huì)亂碼
Hadoop 輸入文件:input/chapter01/WordCount/word.txt
hello world hello hadoop hello bigdata hello hadoop and bigdata
Hadoop 輸出文件夾,output/chapter01/WordCount 運(yùn)行程序前需要?jiǎng)h除。
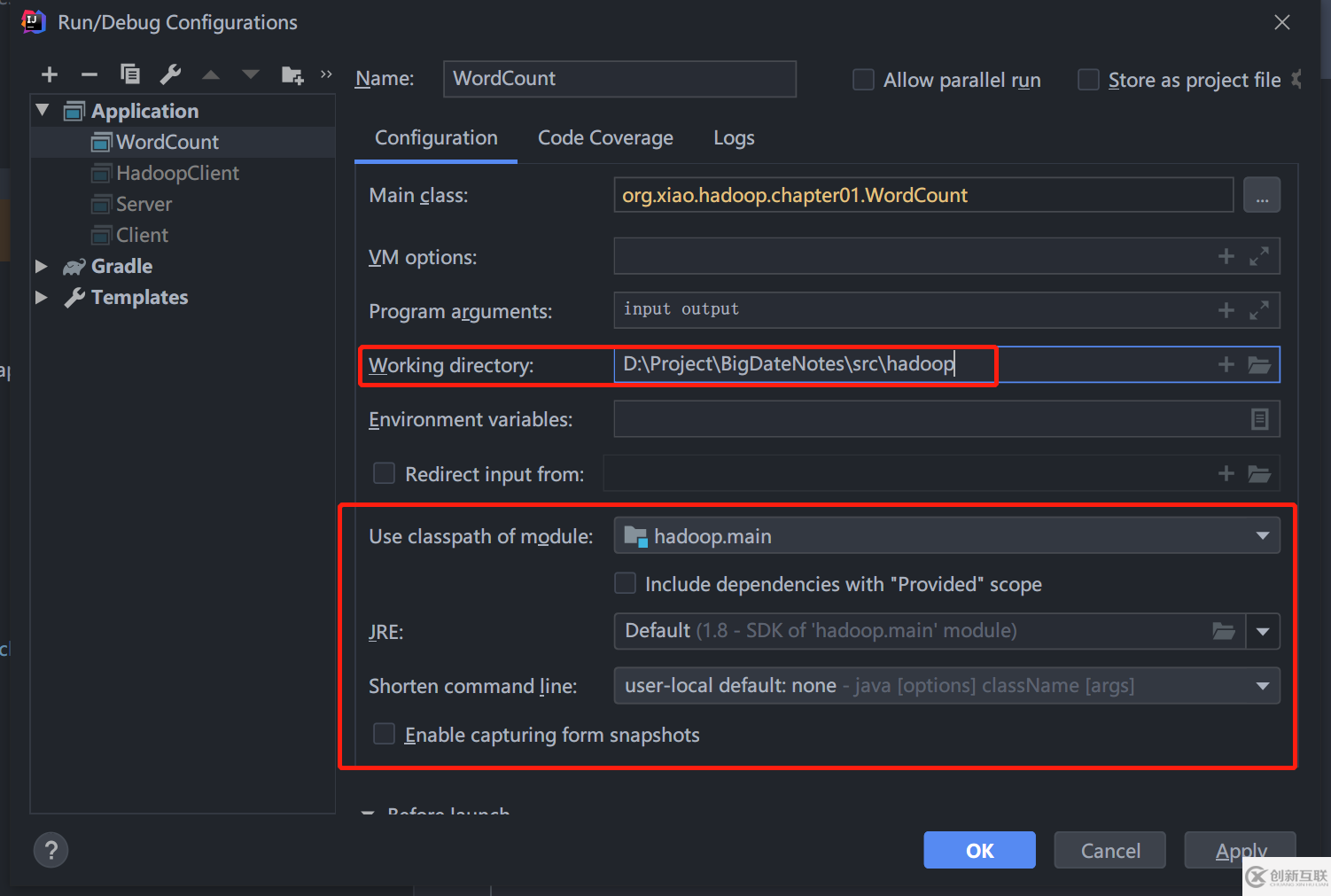
在 WordCount.class 按 Ctrl + Shift + F10 直接運(yùn)行程序即可。項(xiàng)目運(yùn)行配置:
輸出示例:src/hadoop/output/chapter01/WordCount/part-r-00000,沒(méi)有錯(cuò)誤。
and 1 bigdata 2 hadoop 2 hello 4 world 1
2、Idea 遠(yuǎn)程提交 MapReduce
前提已經(jīng)完成:Hadoop 安裝和配置
2020.05.07 更新:追蹤源碼發(fā)現(xiàn),這只是使用集群中的文件,并沒(méi)有提交到集群。見 2.5 真遠(yuǎn)程提交。
2.1、在上一節(jié)的基礎(chǔ)上,增加如下配置:
文件: resource/core-site.xml
<configuration> <property> <!-- URI 定義主機(jī)名稱和 namenode 的 RPC 服務(wù)器工作的端口號(hào) --> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <!-- <property> 這個(gè)可以設(shè)置為本地路徑,但沒(méi)有什么用,這個(gè)路徑是 Hadoop 集群用的 Hadoop 臨時(shí)目錄,默認(rèn)是系統(tǒng)的臨時(shí)目錄下,/tmp/hadoop-${username} 下 <name>hadoop.tmp.dir</name> <value>/home/xian/hadoop/cluster</value> </property> --> </configuration>
文件 resource/mapred-site.xml
<configuration> <!-- 遠(yuǎn)程提交到 Linux 的平臺(tái)上 --> <property> <name>mapred.remote.os</name> <value>Linux</value> <description>Remote MapReduce framework's OS, can be either Linux or Windows</description> </property> <!--允許跨平臺(tái)提交 解決 /bin/bash: line 0: fg: no job control --> <property> <name>mapreduce.app-submission.cross-platform</name> <value>true</value> </property> </configuration>
hdfs-site.xml 和 yarn-site.xml 可以直接復(fù)制集群上的配置文件。
2.2、安裝 BigDataTools 插件
安裝 Idea 官方的 BigDataTools插件,配置連接到 HDFS 集群。可以方便的上傳、下載、刪除文件。
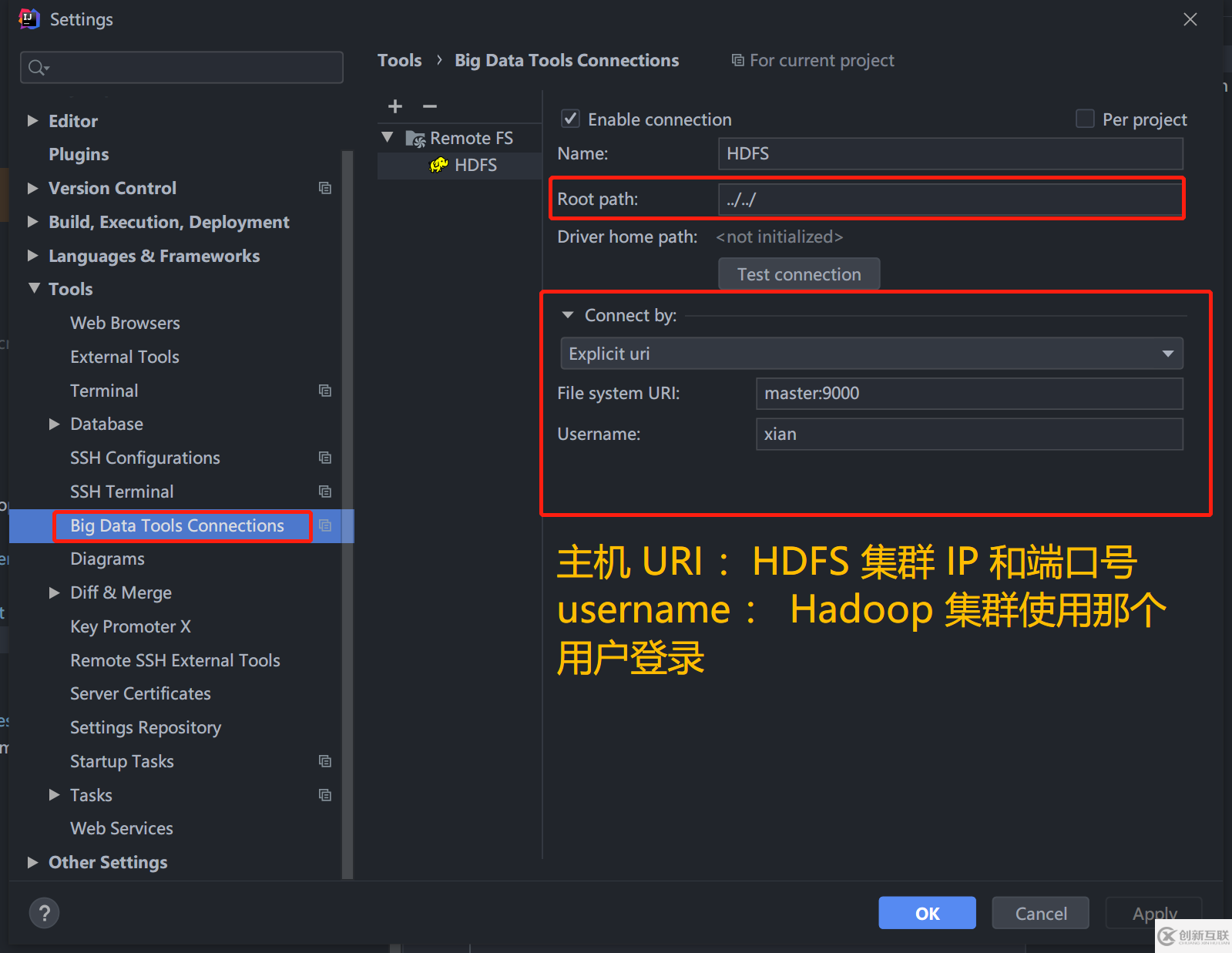
2.3、修改一下代碼
Map 輸入文件路徑可以是絕對(duì)路徑,也可以是相對(duì)路徑。
// 讀取配置文件,自動(dòng)讀取 resource 的那幾個(gè) xml
Configuration conf = new Configuration();
// 省略其他
// 設(shè)置輸入文件的路徑,可以直接指定或者通過(guò)傳入?yún)?shù)
// new Path(arg[0]) 通過(guò) Programmer argument 傳入
// Path("input") 等于 hdfs://master:9000/user/{HADOOP_USER_NAME}/input
FileInputFormat.addInputPath(job, new Path("input"));
// 設(shè)置輸出文件的存放路徑
FileOutputFormat.setOutputPath(job, new Path("output"));將 input/chapter01/WordCount/word.txt 上傳到 hdfs://master:9000/user/{HADOOP_USER_NAME}/input,(上文:解壓 Hadoop 和設(shè)置環(huán)境變量)
2.4、運(yùn)行項(xiàng)目
如果已經(jīng)存在 output 文件夾,需要先刪除了。
同樣,按 Ctrl + Shift + F10 運(yùn)行項(xiàng)目,結(jié)果存儲(chǔ)在 hdfs://master:9000/user/{HADOOP_USER_NAME}/output/part-r-00000 中。
2.5、真遠(yuǎn)程提交方式
首先,使用 Gradle 將代碼打包成 jar 文件,修改文件 src/hadoop/build.gradle,添加
dependencies {
// 省略依賴
}
// 支持中文編碼和注釋
tasks.withType(JavaCompile) {options.encoding = "UTF-8"}使用 Gradle 打包成 jar ,點(diǎn)擊右邊 框起來(lái)的 jar 命令,左邊是生產(chǎn)的 jar 文件。
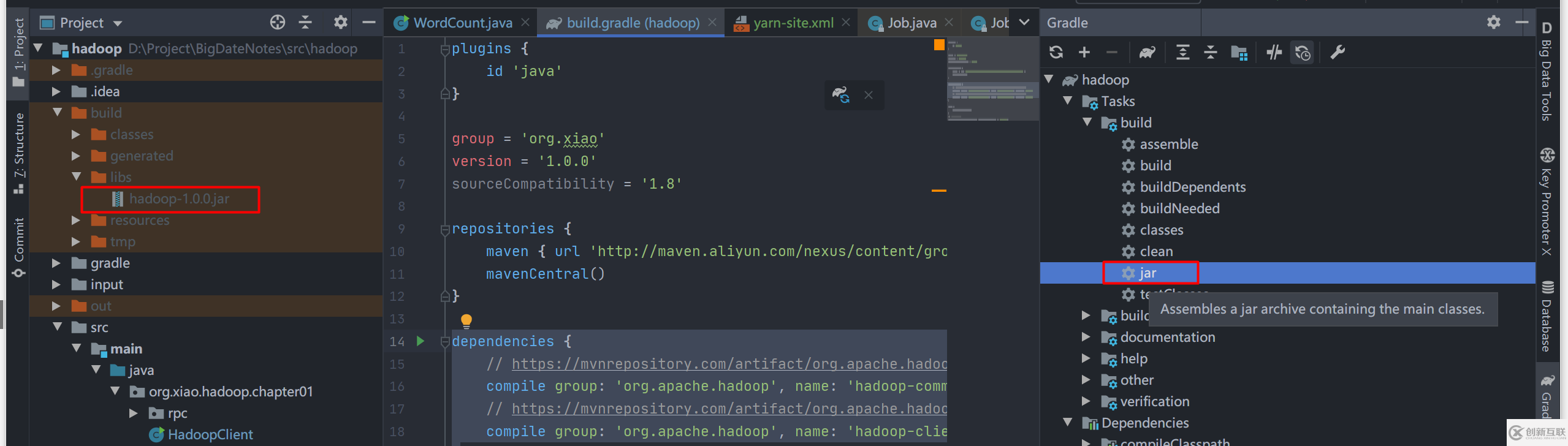
將 jar 提交到遠(yuǎn)程,以下兩種方式:
方式一:文件 src/hadoop/src/main/java/org/xiao/hadoop/chapter01/WordCount.java 讀取配置文件的地方
// 讀取配置文件
Configuration conf = new Configuration();
conf.set("mapreduce.job.jar","D:/Project/BigDateNotes/src/hadoop/build/libs/hadoop-1.0.0.jar");或者 mapred-site.xml 文件添加,注意不管方式一還是方式二,都必須指定 :mapreduce.framework.name 為 yarn。
<configuration> <property> <!-- 使用 Yarn Windows 下遠(yuǎn)程提交去掉這個(gè) https://www.oschina.net/question/2478160_2231358 會(huì)導(dǎo)致找不 Map Reduce 類,原因是遠(yuǎn)程提交,job.setJarByClass 失效 --> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <!-- 設(shè)置提交的 jar 文件路徑 方式二 --> <name>mapreduce.job.jar</name> <value>D:/Project/BigDateNotes/src/hadoop/build/libs/hadoop-1.0.0.jar</value> </property> </configuration>
提交運(yùn)行就行了
小結(jié):
Window 下運(yùn)行 Hadoop 需要 winutils.exe 和 hadoop.dll
推薦使用構(gòu)建工具如 Maven、Gradle 管理 Hadoop 依賴
Windows 下 需要設(shè)置 Gradle 的 build and run using、tests run using 為 IDEA(因?yàn)橹形淖⑨尯徒K端輸出亂碼問(wèn)題)
Idea 遠(yuǎn)程提交需要設(shè)置 mapred.remote.os,mapreduce.app-submission.cross-platform,mapreduce.job.jar 這三個(gè)配置。
關(guān)于IDEA 中怎么運(yùn)行MapReduce 程序問(wèn)題的解答就分享到這里了,希望以上內(nèi)容可以對(duì)大家有一定的幫助,如果你還有很多疑惑沒(méi)有解開,可以關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道了解更多相關(guān)知識(shí)。
分享標(biāo)題:IDEA中怎么運(yùn)行MapReduce程序
轉(zhuǎn)載來(lái)源:http://www.chinadenli.net/article18/jdhjgp.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站排名、靜態(tài)網(wǎng)站、網(wǎng)站導(dǎo)航、外貿(mào)建站、用戶體驗(yàn)、企業(yè)建站
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)

- 佛山網(wǎng)站制作中域名注冊(cè)的問(wèn)題 2022-11-30
- 域名注冊(cè)中的常見問(wèn)題 2022-11-16
- 網(wǎng)站域名注冊(cè)-域名注冊(cè)應(yīng)該注意哪些事項(xiàng)? 2016-11-09
- 價(jià)格不是關(guān)鍵因素 網(wǎng)站建設(shè)前域名注冊(cè)絕非小事 2022-05-20
- 網(wǎng)站開發(fā)有哪些流程步驟?先注冊(cè)域名嗎 2015-01-23
- 網(wǎng)站域名注冊(cè)5個(gè)問(wèn)題 2021-09-09
- 注冊(cè)域名,網(wǎng)站域名注冊(cè) 2023-03-28
- 成都網(wǎng)站制作中域名注冊(cè)的問(wèn)題 2016-11-16
- 國(guó)際域名注冊(cè)要實(shí)名認(rèn)證了? 2014-02-21
- 域名注冊(cè)哪家靠譜 2022-07-13
- 關(guān)于選擇便宜域名注冊(cè)商的技巧 2021-11-11
- 域名選擇技巧:地方網(wǎng)站域名注冊(cè)的一點(diǎn)建議 2022-06-03