Python如何批量爬取某網(wǎng)站圖片
這篇文章給大家分享的是有關(guān)Python如何批量爬取某網(wǎng)站圖片的內(nèi)容。小編覺得挺實(shí)用的,因此分享給大家做個(gè)參考,一起跟隨小編過來看看吧。
讓客戶滿意是我們工作的目標(biāo),不斷超越客戶的期望值來自于我們對(duì)這個(gè)行業(yè)的熱愛。我們立志把好的技術(shù)通過有效、簡(jiǎn)單的方式提供給客戶,將通過不懈努力成為客戶在信息化領(lǐng)域值得信任、有價(jià)值的長(zhǎng)期合作伙伴,公司提供的服務(wù)項(xiàng)目有:域名注冊(cè)、網(wǎng)頁空間、營(yíng)銷軟件、網(wǎng)站建設(shè)、岳塘網(wǎng)站維護(hù)、網(wǎng)站推廣。
1.需要用到的庫有:
Requests re os time 如果沒有安裝的請(qǐng)自己安裝一下,pycharm中打開終端輸入命令就可以安裝
IDE : pycharm
python 版本: 3.8.1
2.爬取地址:
https://www.vmgirls.com/9384.html
-------------------廢話不多說了,不懂的可以給我留言哦,接下來我們一步一步來操作------------------
1.請(qǐng)求網(wǎng)頁
# 請(qǐng)求網(wǎng)頁
import requests
response=requests.get('https://www.vmgirls.com/9384.html')
print(response.text)發(fā)現(xiàn)請(qǐng)求到的是403,直接禁止了我們?cè)L問,requests庫會(huì)告訴他我們是python過來的,他知道我們是一個(gè)python禁止我們反爬
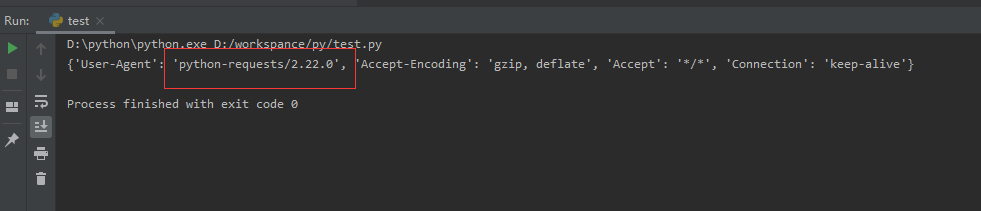
解決:
我們可以偽裝頭,把頭設(shè)置一下
# 請(qǐng)求網(wǎng)頁
import requests
headers={ 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
print(response.request.headers)執(zhí)行結(jié)果:
這樣頭就偽裝了

2.解析網(wǎng)頁
# 請(qǐng)求網(wǎng)頁
import requests
import reheaders={ 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
# print(response.request.headers)
# print(response.text)
html=response.text#解析網(wǎng)頁urls=re.findall('<img alt=".*?">結(jié)果:

可能對(duì)re.findall后面不太理解怎么來的,關(guān)鍵就是要找到圖片的dom然后根據(jù)re庫的一個(gè)匹配規(guī)則來匹配,要匹配的用(.*?)來表示,不需要匹配的用.*?來代替就可以了,
打開網(wǎng)址,按f12查看源碼找到圖片的代碼

復(fù)制圖片代碼,打開網(wǎng)頁源碼按 ctrl+f 進(jìn)行搜索,找到圖片源碼的位置
3.保存圖片
具體可以看源碼,我給這些圖片創(chuàng)建了一個(gè)文件夾(需要os庫),并且命了名,這樣分類下次看小姐姐就比較容易找到啦
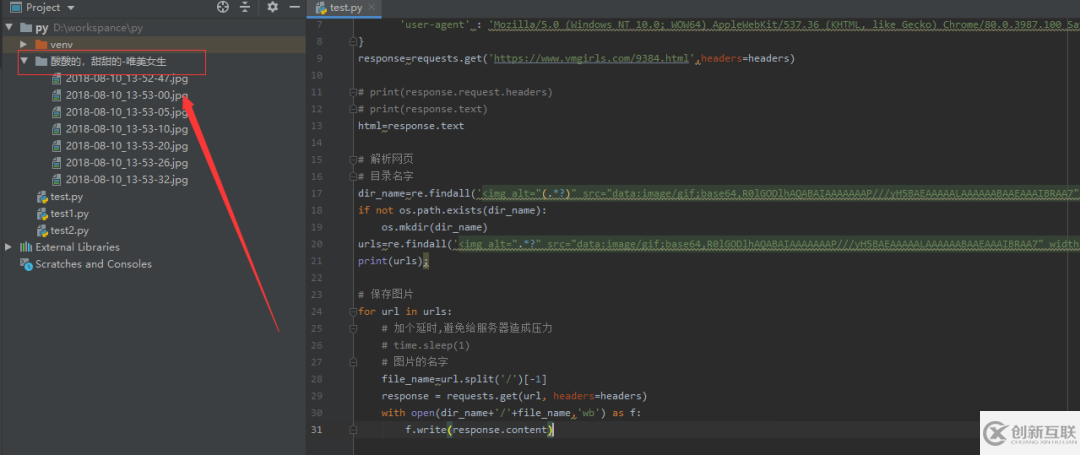
import time
import requestsimport reimport osheaders={ 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
# print(response.request.headers)
# print(response.text)
html=response.text# 解析網(wǎng)頁# 目錄名字dir_name=re.findall('<img alt="(.*?)">感謝各位的閱讀!關(guān)于“Python如何批量爬取某網(wǎng)站圖片”這篇文章就分享到這里了,希望以上內(nèi)容可以對(duì)大家有一定的幫助,讓大家可以學(xué)到更多知識(shí),如果覺得文章不錯(cuò),可以把它分享出去讓更多的人看到吧!
名稱欄目:Python如何批量爬取某網(wǎng)站圖片
網(wǎng)頁鏈接:http://www.chinadenli.net/article18/gpddgp.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供品牌網(wǎng)站制作、手機(jī)網(wǎng)站建設(shè)、、軟件開發(fā)、搜索引擎優(yōu)化、小程序開發(fā)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來源: 創(chuàng)新互聯(lián)

- 網(wǎng)站建設(shè)步驟詳解-要做網(wǎng)站的看這里 2022-12-31
- 做網(wǎng)站優(yōu)化建立關(guān)鍵詞庫的好處有哪些? 2016-09-03
- 怎么樣選擇關(guān)鍵詞更加的有利于做網(wǎng)站優(yōu)化呢? 2022-08-12
- 企業(yè)做網(wǎng)站該如何選擇域名 2017-05-11
- 公司為什么要做網(wǎng)站? 2015-02-21
- 合理清晰的網(wǎng)站布局是做網(wǎng)站的重點(diǎn) 2022-09-24
- 做網(wǎng)站前期要做好哪些工作?企業(yè)應(yīng)了解哪些網(wǎng)站制作知識(shí)? 2022-07-10
- CDN對(duì)于做網(wǎng)站有什么意義? 2022-10-20
- 做網(wǎng)站前應(yīng)該知道的些什么事項(xiàng) 2022-04-19
- 企業(yè)做網(wǎng)站務(wù)必關(guān)注哪些要點(diǎn)? 2022-09-22
- 如何做網(wǎng)站推廣做到好的實(shí)際效果 以下內(nèi)容要高度重視 2016-11-16
- 淺談初級(jí)站長(zhǎng)做網(wǎng)站建設(shè)的步驟 2015-03-01