python中simhash包的使用方法-創(chuàng)新互聯(lián)
創(chuàng)新互聯(lián)www.cdcxhl.cn八線動(dòng)態(tài)BGP香港云服務(wù)器提供商,新人活動(dòng)買多久送多久,劃算不套路!

這篇文章將為大家詳細(xì)講解有關(guān)python中simhash包的使用方法,小編覺得挺實(shí)用的,因此分享給大家做個(gè)參考,希望大家閱讀完這篇文章后可以有所收獲。
1、simHash簡(jiǎn)介
simHash算法是GoogleMoses Charikear于2007年發(fā)布的一篇論文《Detecting Near-duplicates for web crawling》中提出的, 專門用來(lái)解決億萬(wàn)級(jí)別的網(wǎng)頁(yè)去重任務(wù)。
simHash是局部敏感哈希(locality sensitve hash)的一種,其主要思想是降維,將高維的特征向量映射成低維的特征向量,再通過(guò)比較兩個(gè)特征向量的漢明距離(Hamming Distance) 來(lái)確定文章之間的相似性。
什么是局部敏感呢?假設(shè)A,B具有一定的相似性,在hash之后,仍能保持這種相似性,就稱之為局部敏感hash
漢明距離:
Hamming Distance,又稱漢明距離,在信息論中,等長(zhǎng)的兩個(gè)字符串之間的漢明距離就是兩個(gè)字符串對(duì)應(yīng)位置的不同字符的個(gè)數(shù)。即將一個(gè)字符串變換成另外一個(gè)字符串所需要替換的字符個(gè)數(shù),可使用異或操作。
例如: 1011與1001之間的漢明距離是1。
2、simHash具體流程
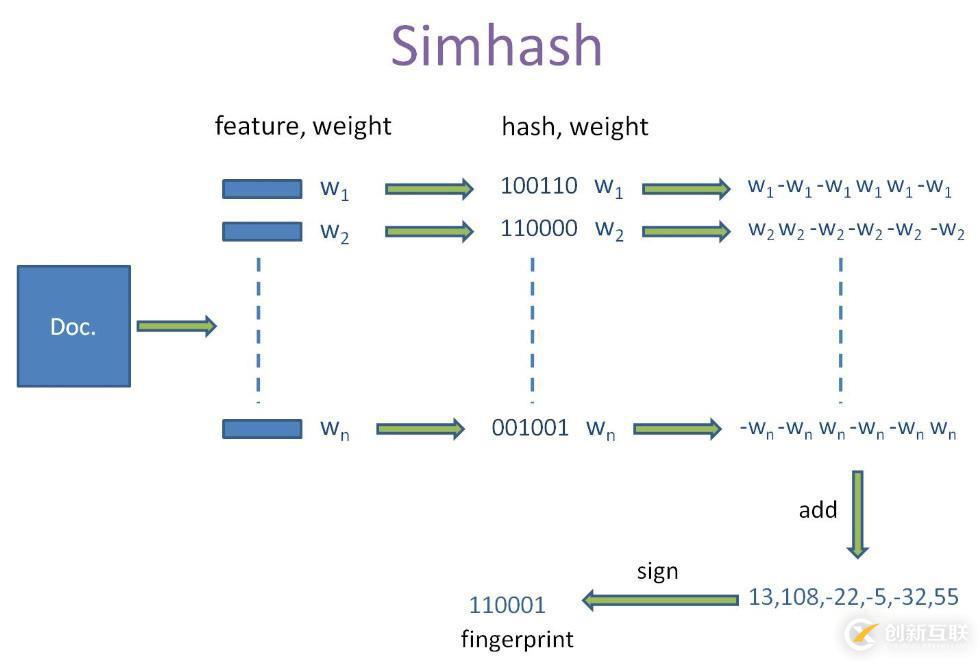
simHash算法總共分為5個(gè)流程: 分詞、has、加權(quán)、合并、降維。
分詞
對(duì)待處理文檔進(jìn)行中文分詞,得到有效的特征及其權(quán)重。可以使用TF-IDF方法獲取一篇文章權(quán)重最高的前topK個(gè)詞(feature)和權(quán)重(weight)。即可使用jieba.analyse.extract_tags()來(lái)實(shí)現(xiàn)
hash
對(duì)獲取的詞(feature),進(jìn)行普通的哈希操作,計(jì)算hash值,這樣就得到一個(gè)長(zhǎng)度為n位的二進(jìn)制,得到(hash:weight)的集合。
加權(quán)
在獲取的hash值的基礎(chǔ)上,根據(jù)對(duì)應(yīng)的weight值進(jìn)行加權(quán),即W=hash*weight。即hash為1則和weight正相乘,為0則和weight負(fù)相乘。例如一個(gè)詞經(jīng)過(guò)hash后得到(010111:5)經(jīng)過(guò)步驟(3)之后可以得到列表[-5,5,-5,5,5,5]。
合并
將上述得到的各個(gè)向量的加權(quán)結(jié)果進(jìn)行求和,變成只有一個(gè)序列串。如[-5,5,-5,5,5,5]、[-3,-3,-3,3,-3,3]、[1,-1,-1,1,1,1]進(jìn)行列向累加得到[-7,1,-9,9,3,9],這樣,我們對(duì)一個(gè)文檔得到,一個(gè)長(zhǎng)度為64的列表。
降維
對(duì)于得到的n-bit簽名的累加結(jié)果的每個(gè)值進(jìn)行判斷,大于0則置為1, 否則置為0,從而得到該語(yǔ)句的simhash值。例如,[-7,1,-9,9,3,9]得到 010111,這樣,我們就得到一個(gè)文檔的 simhash值。
最后根據(jù)不同語(yǔ)句的simhash值的漢明距離來(lái)判斷相似度。
根據(jù)經(jīng)驗(yàn)值,對(duì)64位的 SimHash值,海明距離在3以內(nèi)的可認(rèn)為相似度比較高。
3、Python實(shí)現(xiàn)simHash
使用Python實(shí)現(xiàn)simHash算法,具體如下:
# -*- coding:utf-8 -*-
import jieba
import jieba.analyse
import numpy as np
class SimHash(object):
def simHash(self, content):
seg = jieba.cut(content)
# jieba.analyse.set_stop_words('stopword.txt')
# jieba基于TF-IDF提取關(guān)鍵詞
keyWords = jieba.analyse.extract_tags("|".join(seg), topK=10, withWeight=True)
keyList = []
for feature, weight in keyWords:
print('weight: {}'.format(weight))
# weight = math.ceil(weight)
weight = int(weight)
binstr = self.string_hash(feature)
temp=[]
for c in binstr:
if (c == '1'):
temp.append(weight)
else:
temp.append(-weight)
keyList.append(temp)
listSum = np.sum(np.array(keyList), axis = 0)
if (keyList == []):
return '00'
simhash = ''
for i in listSum:
if (i>0):
simhash = simhash + '1'
else:
simhash = simhash + '0'
return simhash
def string_hash(self, source):
if source == "":
return 0
else:
x = ord(source[0]) << 7
m = 1000003
mask = 2**128 - 1
for c in source:
x = ((x*m)^ord(c)) & mask
x ^= len(source)
if x == -1:
x = -2
x = bin(x).replace('0b', '').zfill(64)[-64:]
# print('strint_hash: %s, %s'%(source, x))
return str(x)
def getDistance(self, hashstr1, hashstr2):
'''
計(jì)算兩個(gè)simhash的漢明距離
'''
length = 0
for index, char in enumerate(hashstr1):
if char == hashstr2[index]:
continue
else:
length += 1
return length
if __name__ == '__main__':
simhash = SimHash()
s1 = simhash.simHash('我想洗照片')
s2 = simhash.simHash('可以洗一張照片嗎')
dis = simhash.getDistance(s1, s2)
print('dis: {}'.format(dis))對(duì)于短小的文本,計(jì)算相似度并不十分準(zhǔn)確,更適用于較長(zhǎng)的文本。
關(guān)于python中simhash包的使用方法就分享到這里了,希望以上內(nèi)容可以對(duì)大家有一定的幫助,可以學(xué)到更多知識(shí)。如果覺得文章不錯(cuò),可以把它分享出去讓更多的人看到。
標(biāo)題名稱:python中simhash包的使用方法-創(chuàng)新互聯(lián)
文章URL:http://www.chinadenli.net/article18/dgiegp.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站改版、外貿(mào)建站、網(wǎng)頁(yè)設(shè)計(jì)公司、網(wǎng)站收錄、網(wǎng)站排名、搜索引擎優(yōu)化
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)

- 響應(yīng)式網(wǎng)站建設(shè)和自適應(yīng)網(wǎng)站建設(shè)之間的區(qū)別 2014-10-17
- 成都響應(yīng)式網(wǎng)站建設(shè)的幾大注意事項(xiàng) 2017-12-28
- 響應(yīng)式網(wǎng)站優(yōu)勢(shì)有哪些?成都網(wǎng)站制做, 2016-10-26
- 成都網(wǎng)站建設(shè)企業(yè)響應(yīng)式網(wǎng)站建設(shè)要注意什么? 2016-10-21
- 網(wǎng)站建設(shè)公司從三點(diǎn)就能分析出響應(yīng)式網(wǎng)站建設(shè)究竟好不好 2021-02-15
- 響應(yīng)式網(wǎng)站建設(shè)有哪些優(yōu)點(diǎn)? 2020-11-28
- 什么是響應(yīng)式設(shè)計(jì)?為什么需要響應(yīng)式網(wǎng)站RWD? 2019-11-16
- 成都響應(yīng)式網(wǎng)站建設(shè)事項(xiàng) 2017-10-28
- 五個(gè)H5響應(yīng)式網(wǎng)站中制作 2022-11-10
- 響應(yīng)式網(wǎng)站怎么定義建設(shè)標(biāo)準(zhǔn) 2023-03-01
- 響應(yīng)式網(wǎng)站建設(shè)有哪些注意事項(xiàng) 2015-08-02
- 響應(yīng)式網(wǎng)站建設(shè)在國(guó)內(nèi)興起,?創(chuàng)新互聯(lián)異軍突起 2023-03-06