dns泛解析及代碼測試-創(chuàng)新互聯
0x00 前言
在自己的掃描器開發(fā)過程中,掃描器當中自然包括了子域名收集功能,但在遇到泛解析的網站時,也增加了掃描器很多不必要的檢測,導致效率和資源的浪費。本文中主要針對掃描器遇到的問題進行解決并優(yōu)化。
創(chuàng)新互聯服務項目包括恭城網站建設、恭城網站制作、恭城網頁制作以及恭城網絡營銷策劃等。多年來,我們專注于互聯網行業(yè),利用自身積累的技術優(yōu)勢、行業(yè)經驗、深度合作伙伴關系等,向廣大中小型企業(yè)、政府機構等提供互聯網行業(yè)的解決方案,恭城網站推廣取得了明顯的社會效益與經濟效益。目前,我們服務的客戶以成都為中心已經輻射到恭城省份的部分城市,未來相信會繼續(xù)擴大服務區(qū)域并繼續(xù)獲得客戶的支持與信任!泛域名解析介紹 https://baike.baidu.com/item/%E6%B3%9B%E5%9F%9F%E5%90%8D%E8%A7%A3%E6%9E%90/9845966?fr=aladdin
0x01 問題產生
泛解析的功能為廠商提供了便利,但為自動化掃描帶來了麻煩,什么麻煩呢?這里以一個使用了泛解析的廠商作為演示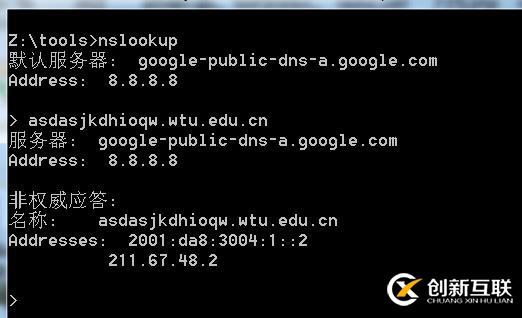
由于該網站使用了泛解析,導致原本不存在的子域名也會成功被解析,那么其實訪問這個域名,會重定向到主頁
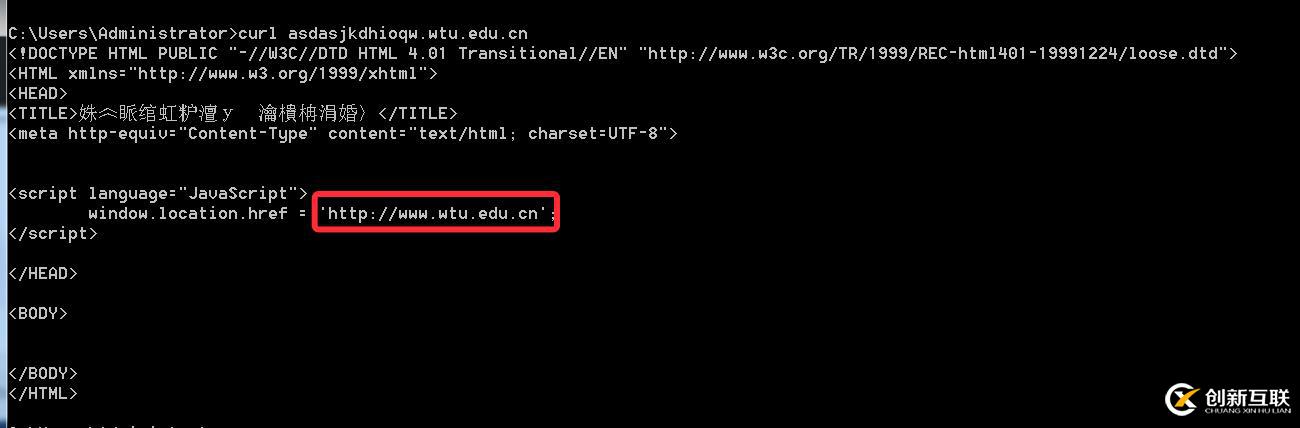
那么在自動化掃描中,通常我們會使用到一個字典組合域名的方式,然后進行dns解析,如果成功解析說明子域名存在,利用這種方式來進行子域名窮舉,但使用泛解析的話,則會導致所有的域名都能成功解析,使得子域名窮舉變得不精準。
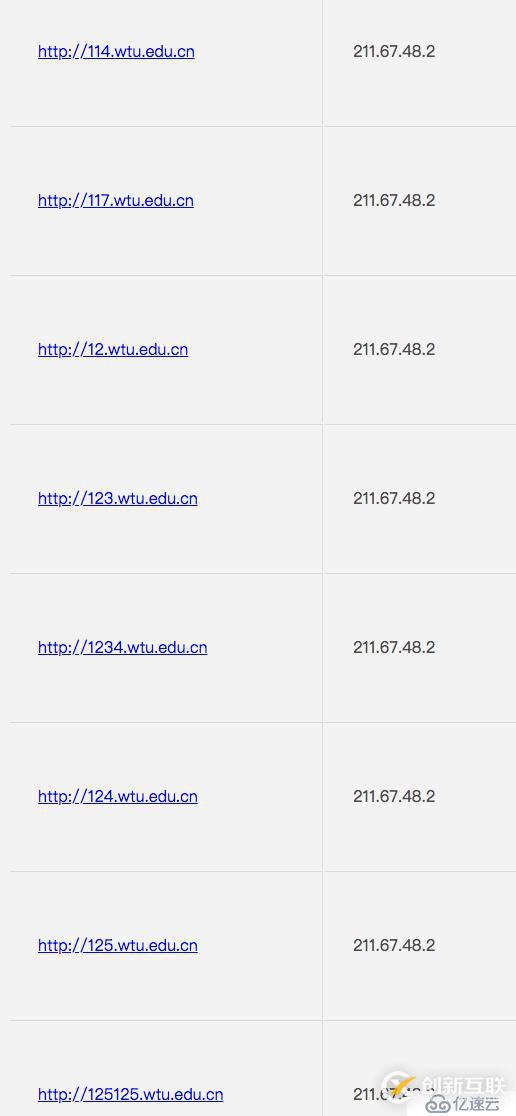
ps:只是一個泛解析測試
0x02 解決方法
那么怎么去判斷域名使用了泛解析和如何解決掃描器中遇到這種情況呢?
泛解析的域名會自動匹配所有*.域名的解析,利用這點我們可以故意去解析一個根本不可能存在的域名,如果能成功解析代表使用泛解析,否之未采用
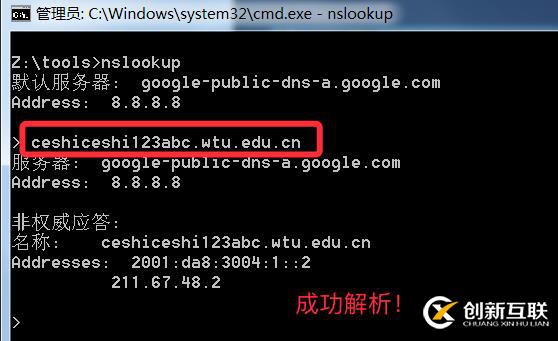
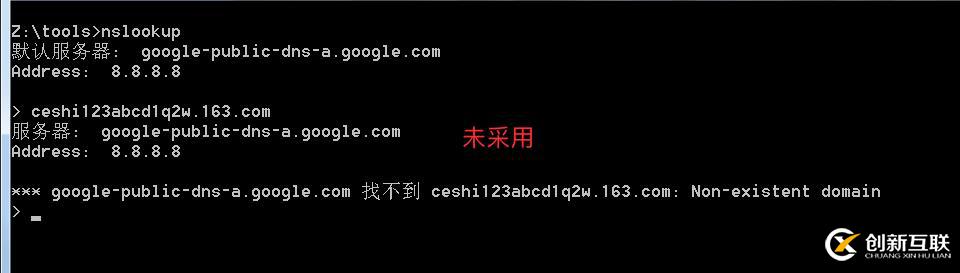
- 掃描器解決思路也同上點,附上演示過程,(具體代碼最后貼)
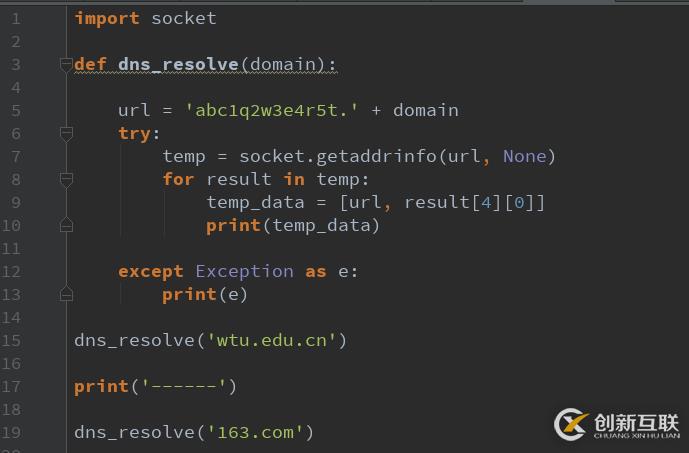
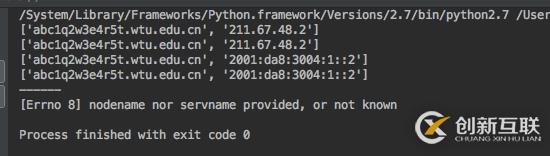
上圖中可以看到,如果能成功解析不存在的域名則使用泛解析,那么socket.getaddrinfo也不會拋出異常
那么改進后的檢測代碼為
import socket
import sys
def dns_resolve(domain):
url = 'abc1q2w3e4r5t.' + domain
flag = False
#拋出異常說明使用了泛解析
try:
socket.getaddrinfo(url, None)
flag = True
except:
pass
if not flag:
print('[+] %s 未采用泛解析'%domain)
else:
print('[-] %s 采用泛解析'%domain)
if __name__ == '__main__':
if len(sys.argv) < 2:
print('python3 %s <domain>'%sys.argv[0])
exit(1)
dns_resolve(sys.argv[1])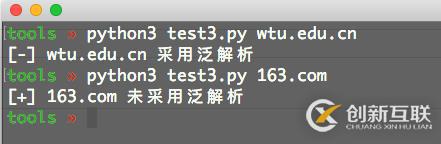
0x03 tips
- 當域名使用了泛解析,那么放棄窮舉的方式來獲取子域名,可通過其他途徑,類似爬蟲或者搜索引擎來獲取
- 如有錯誤,請斧正
另外有需要云服務器可以了解下創(chuàng)新互聯scvps.cn,海內外云服務器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務器、裸金屬服務器、高防服務器、香港服務器、美國服務器、虛擬主機、免備案服務器”等云主機租用服務以及企業(yè)上云的綜合解決方案,具有“安全穩(wěn)定、簡單易用、服務可用性高、性價比高”等特點與優(yōu)勢,專為企業(yè)上云打造定制,能夠滿足用戶豐富、多元化的應用場景需求。
網頁標題:dns泛解析及代碼測試-創(chuàng)新互聯
分享地址:http://www.chinadenli.net/article16/cespgg.html
成都網站建設公司_創(chuàng)新互聯,為您提供網站建設、營銷型網站建設、企業(yè)建站、動態(tài)網站、移動網站建設、網站收錄
聲明:本網站發(fā)布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創(chuàng)新互聯

- 商城網站建設就是要把網站做得對搜索引擎的檢索原則 2023-11-12
- 我的網站為什么沒有人點擊呢? 2021-05-03
- 如何讓銷售新手快速成長的技巧有哪些 2023-05-12
- 近十年互聯網的發(fā)展給中小企業(yè)帶來什么樣飛躍的變化 2023-05-17
- SEO優(yōu)化,SEO中不可忽視的地方-內頁優(yōu)化 2022-12-31
- 定制網站多少錢?有哪些費用指支出? 2021-04-29
- 企業(yè)網站的排名如何排到首頁? 2016-11-14
- 自助建站與傳統(tǒng)式建站的差別 2023-09-07
- 外貿網站優(yōu)化怎樣充分利用外鏈 2023-05-30
- 淺談2019如何推廣app 2019-09-07
- 四步計劃建造自己的關鍵字的URL映射 2016-08-13
- 建設企業(yè)網站時怎樣提高網站打開速度? 2023-04-08