java中HashMap的用法
這篇文章主要介紹“java中HashMap的用法”,在日常操作中,相信很多人在java中HashMap的用法問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”java中HashMap的用法”的疑惑有所幫助!接下來,請跟著小編一起來學(xué)習(xí)吧!
創(chuàng)新互聯(lián)公司主營寧陽網(wǎng)站建設(shè)的網(wǎng)絡(luò)公司,主營網(wǎng)站建設(shè)方案,成都App制作,寧陽h5微信小程序搭建,寧陽網(wǎng)站營銷推廣歡迎寧陽等地區(qū)企業(yè)咨詢
1、HashMap的數(shù)據(jù)結(jié)構(gòu)以及如何存儲數(shù)據(jù)?
HashMap的幾個重要參數(shù):
transient int size:表示當(dāng)前HashMap包含的鍵值對數(shù)量
transient int modCount:表示當(dāng)前HashMap修改次數(shù)
int threshold:表示當(dāng)前HashMap能夠承受的最多的鍵值對數(shù)量,一旦超過這個數(shù)量HashMap就會進行擴容
final float loadFactor:負(fù)載因子,用于擴容
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4:默認(rèn)的table初始容量
static final float DEFAULT_LOAD_FACTOR = 0.75f:默認(rèn)的負(fù)載因子
數(shù)組的特點是:尋址容易,插入和刪除困難;
而鏈表的特點是:尋址困難,插入和刪除容易。
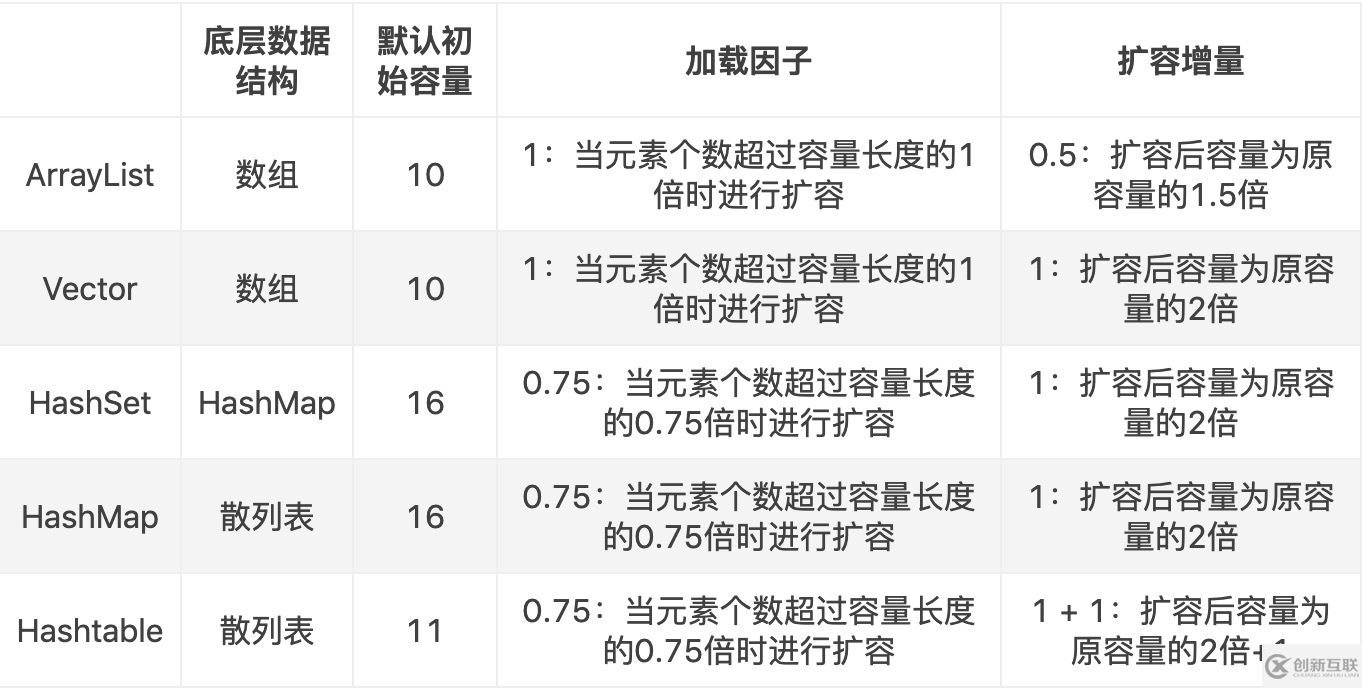
Hashmap實際上是一個數(shù)組和鏈表的結(jié)合體(在數(shù)據(jù)結(jié)構(gòu)中,一般稱之為“鏈表散列“),請看下圖(橫排表示數(shù)組,縱排表示數(shù)組元素【實際上是一個鏈表】)。 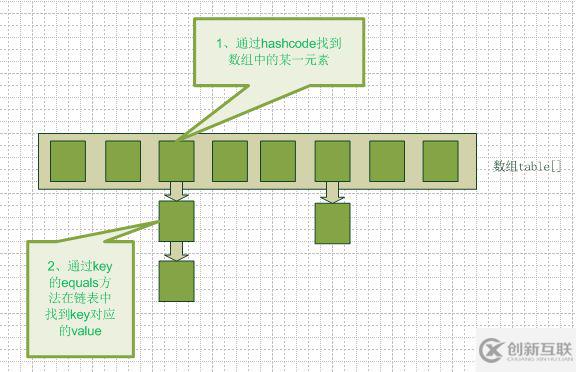
從圖中我們可以看到一個hashmap就是一個數(shù)組結(jié)構(gòu),當(dāng)新建一個hashmap的時候,就會初始化一個數(shù)組。我們來看看java代碼:
/**
* The table, resized as necessary. Length MUST Always be a power of two.
* FIXME 這里需要注意這句話,至于原因后面會講到
*/
transient Entry[] table;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
final int hash;
Entry<K,V> next;
..........
}上面的Entry就是數(shù)組中的元素,它持有一個指向下一個元素的引用,這就構(gòu)成了鏈表。
當(dāng)我們往hashmap中put元素的時候,先根據(jù)key的hash值得到這個元素在數(shù)組中的位置(即下標(biāo)),然后就可以把這個元素放到對應(yīng)的位置中了。如果這個元素所在的位子上已經(jīng)存放有其他元素了,那么在同一個位子上的元素將以鏈表的形式存放,新加入的放在鏈頭,最先加入的放在鏈尾。從hashmap中g(shù)et元素時,首先計算key的hashcode,找到數(shù)組中對應(yīng)位置的某一元素,然后通過key的equals方法在對應(yīng)位置的鏈表中找到需要的元素。從這里我們可以想象得到,如果每個位置上的鏈表只有一個元素,那么hashmap的get效率將是最高的
hash算法
我們可以看到在hashmap中要找到某個元素,需要根據(jù)key的hash值來求得對應(yīng)數(shù)組中的位置。如何計算這個位置就是hash算法。前面說過hashmap的數(shù)據(jù)結(jié)構(gòu)是數(shù)組和鏈表的結(jié)合,所以我們當(dāng)然希望這個hashmap里面的元素位置盡量的分布均勻些,盡量使得每個位置上的元素數(shù)量只有一個,那么當(dāng)我們用hash算法求得這個位置的時候,馬上就可以知道對應(yīng)位置的元素就是我們要的,而不用再去遍歷鏈表。
所以我們首先想到的就是把hashcode對數(shù)組長度取模運算,這樣一來,元素的分布相對來說是比較均勻的。
確定hash數(shù)組的索引位置
方法一:
static final int hash(Object key) { //jdk1.8 & jdk1.7
int h;
// h = key.hashCode() 為第一步 取hashCode值
// h ^ (h >>> 16) 為第二步 高位參與運算
//可以在數(shù)組table的length比較小的時候,也能保證考慮到高低Bit都參與到Hash的計算中,同時不會有太大的開銷
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
方法二:
static int indexFor(int h, int length) { //jdk1.7的源碼,jdk1.8沒有這個方法,但是實現(xiàn)原理一樣的
return h & (length-1); //第三步 取模運算 速度更快
}這里的Hash算法本質(zhì)上就是三步:取key的hashCode值、高位運算、取模運算。
hashmap的數(shù)組初始化大小都是2的次方大小時,hashmap的效率最高。
看下圖,左邊兩組是數(shù)組長度為16(2的4次方),右邊兩組是數(shù)組長度為15。兩組的hashcode均為8和9,但是很明顯,當(dāng)它們和1110“與”的時候,產(chǎn)生了相同的結(jié)果,也就是說它們會定位到數(shù)組中的同一個位置上去,這就產(chǎn)生了碰撞,8和9會被放到同一個鏈表上,那么查詢的時候就需要遍歷這個鏈表,得到8或者9,這樣就降低了查詢的效率。同時,我們也可以發(fā)現(xiàn),當(dāng)數(shù)組長度為15的時候,hashcode的值會與14(1110)進行“與”,那么最后一位永遠(yuǎn)是0,而0001,0011,0101,1001,1011,0111,1101這幾個位置永遠(yuǎn)都不能存放元素了,空間浪費相當(dāng)大,更糟的是這種情況中,數(shù)組可以使用的位置比數(shù)組長度小了很多,這意味著進一步增加了碰撞的幾率,減慢了查詢的效率!
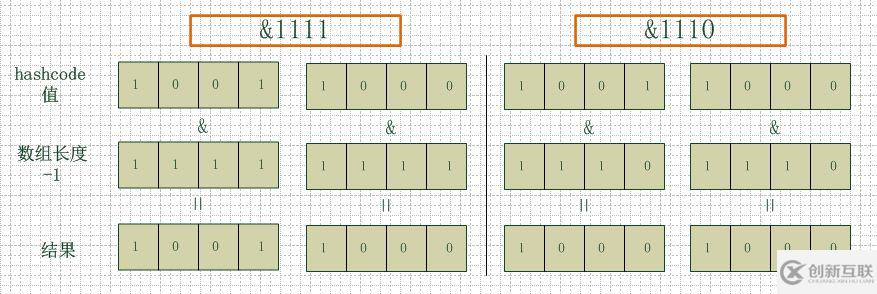
所以說,當(dāng)數(shù)組長度為2的n次冪的時候,不同的key算得得index相同的幾率較小,那么數(shù)據(jù)在數(shù)組上分布就比較均勻,也就是說碰撞的幾率小,相對的,查詢的時候就不用遍歷某個位置上的鏈表,這樣查詢效率也就較高了。
hashmap中默認(rèn)的數(shù)組大小是16
因為16是2的整數(shù)次冪的原因,在小數(shù)據(jù)量的情況下16比15和20更能減少key之間的碰撞,而加快查詢的效率。
所以,在存儲大容量數(shù)據(jù)的時候,最好預(yù)先指定hashmap的size為2的整數(shù)次冪次方。就算不指定的話,也會以大于且最接近指定值大小的2次冪來初始化的,代碼如下(HashMap的構(gòu)造方法中):
// Find a power of 2 >= initialCapacity int capacity = 1; while (capacity < initialCapacity) capacity <<= 1;
2、擴容機制,如何擴容,1.7擴容時出現(xiàn)環(huán)型鏈表了解嗎?1.8怎么擴容的?幾倍擴容?默認(rèn)容量多少?
擴容機制
當(dāng)hashmap中的元素越來越多的時候,碰撞的幾率也就越來越高(因為數(shù)組的長度是固定的),所以為了提高查詢的效率,就要對hashmap的數(shù)組進行擴容
什么時候擴容?
1、 存放新值的時候當(dāng)前已有元素的個數(shù)必須大于等于閾值:
當(dāng)hashmap中的元素個數(shù)超過數(shù)組大小*loadFactor時,就會進行數(shù)組擴容,loadFactor的默認(rèn)值為0.75(JDK中的解釋就是盡量減少rehash的次數(shù),并且在時間和空間上做了一個很好的折中。同時,如果這個值設(shè)置的比較大的話,桶中的鍵值碰撞的幾率就會大大上升),也就是說,默認(rèn)情況下,數(shù)組大小為16,那么當(dāng)hashmap中元素個數(shù)超過16*0.75=12的時候,就把數(shù)組的大小擴展為2*16=32,即擴大一倍,然后重新計算每個元素在數(shù)組中的位置,而這是一個非常消耗性能的操作
2、 存放新值的時候當(dāng)前存放數(shù)據(jù)發(fā)生hash碰撞
resize
在hashmap數(shù)組擴容之后,最消耗性能的點就出現(xiàn)了:原數(shù)組中的數(shù)據(jù)必須重新計算其在新數(shù)組中的位置,并放進去,這就是resize
如何擴容?
resize()方法
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
transfer(newTable, rehash); //transfer函數(shù)的調(diào)用
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
//其實就是新建一個 newCapacity大小的數(shù)組,然后調(diào)用transfer()方法將元素復(fù)制進去。
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) { //這里才是問題出現(xiàn)的關(guān)鍵..
while(null != e) {
Entry<K,V> next = e.next; //尋找到下一個節(jié)點..
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity); //重新獲取hashcode
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}總得來說,就是拷貝舊的數(shù)據(jù)元素,從新新建一個更大容量的空間,然后進行數(shù)據(jù)復(fù)制
關(guān)于環(huán)形鏈表的形成,則主要在這擴容的過程。當(dāng)多個線程同時對這個HashMap進行put操作,而察覺到內(nèi)存容量不夠,需要進行擴容時,多個線程會同時執(zhí)行resize操作,而這就出現(xiàn)問題了,問題的原因分析如下:
首先,在HashMap擴容時,會改變鏈表中的元素的順序,將元素從鏈表頭部插入(避免尾部遍歷)。
而環(huán)形鏈表就在這一時刻發(fā)生,以下模擬2個線程同時擴容。假設(shè),當(dāng)前hashmap的空間為2(臨界值為1),hashcode分別為0和1,在散列地址0處有元素A和B,這時候要添加元素C,C經(jīng)過hash運算,得到散列地址為1,這時候由于超過了臨界值,空間不夠,需要調(diào)用resize方法進行擴容,那么在多線程條件下,會出現(xiàn)條件競爭,模擬過程如下:
線程一:讀取到當(dāng)前的hashmap情況,在準(zhǔn)備擴容時,線程二介入
這個過程為,先將A復(fù)制到新的hash表中,然后接著復(fù)制B到鏈頭(A的前邊:B.next=A),本來B.next=null,到此也就結(jié)束了(跟線程二一樣的過程),但是,由于線程二擴容的原因,將B.next=A,所以,這里繼續(xù)復(fù)制A,讓A.next=B,由此,環(huán)形鏈表出現(xiàn):B.next=A; A.next=B

1.7、1.8的區(qū)別
1.8主要優(yōu)化減少了Hash沖突 ,提高哈希表的存、取效率。
底層數(shù)據(jù)結(jié)構(gòu)不一樣,1.7是數(shù)組+鏈表,1.8則是數(shù)組+鏈表+紅黑樹結(jié)構(gòu)(當(dāng)鏈表長度大于8,轉(zhuǎn)為紅黑樹)。
JDK1.8中resize()方法在表為空時,創(chuàng)建表;在表不為空時,擴容;而JDK1.7中resize()方法負(fù)責(zé)擴容,inflateTable()負(fù)責(zé)創(chuàng)建表。
1.8中沒有區(qū)分鍵為null的情況,而1.7版本中對于鍵為null的情況調(diào)用putForNullKey()方法。但是兩個版本中如果鍵為null,那么調(diào)用hash()方法得到的都將是0,所以鍵為null的元素都始終位于哈希表table[0]中。
當(dāng)1.8中的桶中元素處于鏈表的情況,遍歷的同時最后如果沒有匹配的,直接將節(jié)點添加到鏈表尾部;而1.7在遍歷的同時沒有添加數(shù)據(jù),而是另外調(diào)用了addEntry()方法,將節(jié)點添加到鏈表頭部。
1.7中新增節(jié)點采用頭插法,1.8中新增節(jié)點采用尾插法。這也是為什么1.8不容易出現(xiàn)環(huán)型鏈表的原因。
1.7中是通過更改hashSeed值修改節(jié)點的hash值從而達到rehash時的鏈表分散,而1.8中鍵的hash值不會改變,rehash時根據(jù)(hash&oldCap)==0將鏈表分散。
1.8rehash時保證原鏈表的順序,而1.7中rehash時有可能改變鏈表的順序(頭插法導(dǎo)致)。
在擴容的時候:1.7在插入數(shù)據(jù)之前擴容,而1.8插入數(shù)據(jù)成功之后擴容。
3、Hash沖突
為什么產(chǎn)生Hash沖突?
由于哈希算法被計算的數(shù)據(jù)是無限的,而計算后的結(jié)果范圍有限,因此總會存在不同的數(shù)據(jù)經(jīng)過計算后得到的值相同,這就是哈希沖突。(兩個不同的數(shù)據(jù)計算后的結(jié)果一樣)
如何解決?
開放定址法
從發(fā)生沖突的那個單元起,按照一定的次序,從哈希表中找到一個空閑的單元,然后把發(fā)生沖突的元素存入到該單元的一種方法。
開放定址法需要的表長度要大于等于所需要存放的元素
在開放定址法中解決沖突的方法有:
a. 線行探查法
線行探查法是開放定址法中最簡單的沖突處理方法,它從發(fā)生沖突的單元起,依次判斷下一個單元是否為空,當(dāng)達到最后一個單元時,再從表首依次判斷。直到碰到空閑的單元或者探查完全部單元為止。
b. 平方探查法
平方探查法即是發(fā)生沖突時,用發(fā)生沖突的單元d[i], 加上 12、 22等。即d[i] + 12,d[i] + 22, d[i] + 32…直到找到空閑單元。在實際操作中,平方探查法不能探查到全部剩余的單元。不過在實際應(yīng)用中,能探查到一半單元也就可以了。若探查到一半單元仍找不到一個空閑單元,表明此散列表太滿,應(yīng)該重新建立。
c. 雙散列探查法
這種方法使用兩個散列函數(shù)hl和h3。其中hl和前面的h一樣,以關(guān)鍵字為自變量,產(chǎn)生一個0至m—l之間的數(shù)作為散列地址;h3也以關(guān)鍵字為自變量,產(chǎn)生一個l至m—1之間的、并和m互素的數(shù)(即m不能被該數(shù)整除)作為探查序列的地址增量(即步長),探查序列的步長值是固定值l;對于平方探查法,探查序列的步長值是探查次數(shù)i的兩倍減l;對于雙散列函數(shù)探查法,其探查序列的步長值是同一關(guān)鍵字的另一散列函數(shù)的值。
開放定址法缺點:
刪除元素的時候不能真的刪除,否則會引起查找錯誤。
只能做一個標(biāo)記,直到有下個元素插入才能真正刪除該元素。鏈地址法
鏈地址法的思路是將哈希值相同的元素構(gòu)成一個同義詞的單鏈表,并將單鏈表的頭指針存放在哈希表的第i個單元中,查找、插入和刪除主要在同義詞鏈表中進行。鏈地址法適用于經(jīng)常進行插入和刪除的情況。再哈希法
就是同時構(gòu)造多個不同的哈希函數(shù):Hi = RHi(key) i= 1,2,3 … k;當(dāng)H1 = RH1(key) 發(fā)生沖突時,再用H2 = RH2(key) 進行計算,直到?jīng)_突不再產(chǎn)生,這種方法不易產(chǎn)生聚集,但是增加了計算時間。建立公共溢出區(qū)
將哈希表分為公共表和溢出表,當(dāng)溢出發(fā)生時,將所有溢出數(shù)據(jù)統(tǒng)一放到溢出區(qū)。
到此,關(guān)于“java中HashMap的用法”的學(xué)習(xí)就結(jié)束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學(xué)習(xí),快去試試吧!若想繼續(xù)學(xué)習(xí)更多相關(guān)知識,請繼續(xù)關(guān)注創(chuàng)新互聯(lián)網(wǎng)站,小編會繼續(xù)努力為大家?guī)砀鄬嵱玫奈恼拢?/p>
標(biāo)題名稱:java中HashMap的用法
網(wǎng)站URL:http://www.chinadenli.net/article12/jogddc.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供定制開發(fā)、電子商務(wù)、定制網(wǎng)站、關(guān)鍵詞優(yōu)化、企業(yè)建站、自適應(yīng)網(wǎng)站
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)

- 怎樣利用chatGPT快速賺錢? 2023-05-05
- ChatGPT的發(fā)展歷程 2023-02-20
- 馬云回國,首談ChatGPT。又是新一個風(fēng)口? 2023-05-28
- 火爆的ChatGPT,來聊聊它的熱門話題 2023-02-20
- ChatGPT是什么 2023-02-20
- ChatGPT是什么?ChatGPT是聊天機器人嗎? 2023-05-05
- ChatGPT的應(yīng)用ChatGPT對社會的利弊影響 2023-02-20
- 爆紅的ChatGPT,誰會丟掉飯碗? 2023-02-20