python文件數(shù)據(jù)分析治理提取的方法是什么
這篇文章主要介紹了python文件數(shù)據(jù)分析治理提取的方法是什么的相關(guān)知識(shí),內(nèi)容詳細(xì)易懂,操作簡(jiǎn)單快捷,具有一定借鑒價(jià)值,相信大家閱讀完這篇python文件數(shù)據(jù)分析治理提取的方法是什么文章都會(huì)有所收獲,下面我們一起來(lái)看看吧。
創(chuàng)新互聯(lián)建站是一家專(zhuān)業(yè)提供開(kāi)平企業(yè)網(wǎng)站建設(shè),專(zhuān)注與成都網(wǎng)站設(shè)計(jì)、網(wǎng)站制作、HTML5、小程序制作等業(yè)務(wù)。10年已為開(kāi)平眾多企業(yè)、政府機(jī)構(gòu)等服務(wù)。創(chuàng)新互聯(lián)專(zhuān)業(yè)網(wǎng)站建設(shè)公司優(yōu)惠進(jìn)行中。

前提提要
python2.0有無(wú)法直接讀取中文路徑的問(wèn)題,需要另外寫(xiě)函數(shù)。python3.0在2018年的時(shí)候也無(wú)法直接讀取。
現(xiàn)在使用的時(shí)候,發(fā)現(xiàn)python3.0是可以直接讀取中文路徑的。
需要自帶或者創(chuàng)建幾個(gè)txt文件,里面最好寫(xiě)幾個(gè)數(shù)據(jù)(姓名,手機(jī)號(hào),住址)
要求
寫(xiě)代碼的時(shí)候最好,自己設(shè)幾個(gè)要求,明確下目的:
需要讀取對(duì)應(yīng)目錄路徑的所有對(duì)應(yīng)文件
按行讀取出每個(gè)對(duì)應(yīng)txt文件的記錄
使用正則表達(dá)式獲取每行的手機(jī)號(hào)
將手機(jī)號(hào)碼存儲(chǔ)到excel中
思路
1)讀取文件
2)讀取數(shù)據(jù)
3)數(shù)據(jù)整理
4)正則表達(dá)式匹配
5)數(shù)據(jù)去重
6)數(shù)據(jù)導(dǎo)出保存
代碼
import glob
import re
import xlwt
filearray=[]
data=[]
phone=[]
filelocation=glob.glob(r'課堂實(shí)訓(xùn)/*.txt')
print(filelocation)
for i in range(len(filelocation)):
file =open(filelocation[i])
file_data=file.readlines()
data.append(file_data)
print(data)
combine_data=sum(data,[])
print(combine_data)
for a in combine_data:
data1=re.search(r'[0-9]{11}',a)
phone.append(data1[0])
phone=list(set(phone))
print(phone)
print(len(phone))
#存到excel中
f=xlwt.Workbook('encoding=utf-8')
sheet1=f.add_sheet('sheet1',cell_overwrite_ok=True)
for i in range(len(phone)):
sheet1.write(i,0,phone[i])
f.save('phonenumber.xls')運(yùn)行結(jié)果

會(huì)生成一個(gè)excel文件

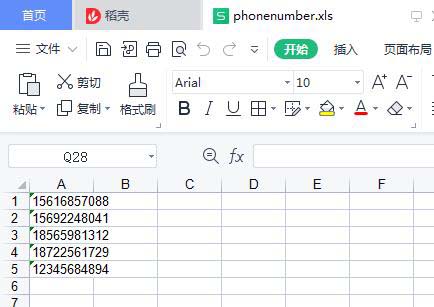
分析
import glob import re import xlwt
globe用來(lái)定位文件,re正則表達(dá)式,xlwt用于excel
1)讀取文件
filelocation=glob.glob(r'課堂實(shí)訓(xùn)/*.txt')
指定目錄下的所有txt文件
2)讀取數(shù)據(jù)
for i in range(len(filelocation)): file =open(filelocation[i]) file_data=file.readlines() data.append(file_data) print(data)
將路徑下的txt文件循環(huán)讀取,按序號(hào)依次讀取文件
打開(kāi)每一次循環(huán)對(duì)應(yīng)的文件
將每一次循環(huán)的txt文件的數(shù)據(jù)按行讀取出來(lái)
使用append()方法將每一行的數(shù)據(jù)添加到data列表中
輸出一下,可以看到將幾個(gè)txt的文件數(shù)據(jù)以字列形式存在同一個(gè)列表
3)數(shù)據(jù)整理
combine_data=sum(data,[])
列表合并成一個(gè)列表
4)正則表達(dá)式匹配外加數(shù)據(jù)去重
print(combine_data)
for a in combine_data:
data1=re.search(r'[0-9]{11}',a)
phone.append(data1[0])
phone=list(set(phone))
print(phone)
print(len(phone))set()函數(shù):無(wú)序去重,創(chuàng)建一個(gè)無(wú)序不重復(fù)元素集
6)數(shù)據(jù)導(dǎo)出保存
#存到excel中
f=xlwt.Workbook('encoding=utf-8')
sheet1=f.add_sheet('sheet1',cell_overwrite_ok=True)
for i in range(len(phone)):
sheet1.write(i,0,phone[i])
f.save('phonenumber.xls')Workbook('encoding=utf-8'):設(shè)置工作簿的編碼
add_sheet('sheet1',cell_overwrite_ok=True):創(chuàng)建對(duì)應(yīng)的工作表
write(x,y,z):參數(shù)對(duì)應(yīng)行、列、值
關(guān)于“python文件數(shù)據(jù)分析治理提取的方法是什么”這篇文章的內(nèi)容就介紹到這里,感謝各位的閱讀!相信大家對(duì)“python文件數(shù)據(jù)分析治理提取的方法是什么”知識(shí)都有一定的了解,大家如果還想學(xué)習(xí)更多知識(shí),歡迎關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道。
分享名稱(chēng):python文件數(shù)據(jù)分析治理提取的方法是什么
當(dāng)前網(wǎng)址:http://www.chinadenli.net/article12/ihhhgc.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供軟件開(kāi)發(fā)、網(wǎng)站制作、App設(shè)計(jì)、做網(wǎng)站、手機(jī)網(wǎng)站建設(shè)、定制開(kāi)發(fā)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶(hù)投稿、用戶(hù)轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話(huà):028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)

- 企業(yè)建站在用戶(hù)數(shù)量方面要做哪些努力 2022-10-27
- 企業(yè)建站有哪些坑? 2022-12-30
- 動(dòng)態(tài)網(wǎng)頁(yè)和靜態(tài)網(wǎng)頁(yè)哪個(gè)更適合企業(yè)建站? 2016-10-13
- 為什么企業(yè)建站都喜歡選擇本地建站公司? 2016-11-24
- 企業(yè)建站制作要掌握的細(xì)節(jié) 2020-11-24
- 企業(yè)建站過(guò)程中的相關(guān)注意細(xì)節(jié) 2016-04-09
- 如何能夠讓企業(yè)建站效果趕上小程序和公眾號(hào)? 2023-02-07
- 企業(yè)建站擁有獨(dú)立服務(wù)器有什么好處? 2022-11-04
- 手機(jī)網(wǎng)站成為企業(yè)建站標(biāo)配 2016-11-10
- 企業(yè)建站涉及到的問(wèn)題有哪些? 2023-04-06
- 企業(yè)建站常見(jiàn)流程 2022-07-29
- 中小企業(yè)建站怎么選擇合適的空間呢? 2016-10-29