原生python如何實現(xiàn)knn分類算法-創(chuàng)新互聯(lián)
這篇文章給大家分享的是有關(guān)原生python如何實現(xiàn)knn分類算法的內(nèi)容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。

一、題目要求
用原生Python實現(xiàn)knn分類算法。
二、題目分析
數(shù)據(jù)來源:鳶尾花數(shù)據(jù)集(見附錄Iris.txt)
數(shù)據(jù)集包含150個數(shù)據(jù)集,分為3類,分別是:Iris Setosa(山鳶尾)、Iris Versicolour(雜色鳶尾)和Iris Virginica(維吉尼亞鳶尾)。每類有50個數(shù)據(jù),每個數(shù)據(jù)包含四個屬性,分別是:Sepal.Length(花萼長度)、Sepal.Width(花萼寬度)、Petal.Length(花瓣長度)和Petal.Width(花瓣寬度)。
將得到的數(shù)據(jù)集按照7:3的比例劃分,其中7為訓練集,3為測試集。編寫算法實現(xiàn):學習訓練集的數(shù)據(jù)特征來預(yù)測測試集鳶尾花的種類,并且計算出預(yù)測的準確性。
KNN是通過測量不同特征值之間的距離進行分類。它的思路是:如果一個樣本在特征空間中的k個最相似(即特征空間中最鄰近)的樣本中的大多數(shù)屬于某一個類別,則該樣本也屬于這個類別,其中K通常是不大于20的整數(shù)。KNN算法中,所選擇的鄰居都是已經(jīng)正確分類的對象。該方法在定類決策上只依據(jù)最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。
三、算法設(shè)計
1)將文本文件按行分割,寫入列表datas中
def data_read(filepath): # 讀取txt文件,將讀出的內(nèi)容存入datas列表中
fp = open(filepath, "r")
datas = [] # 存儲處理后的數(shù)據(jù)
lines = fp.readlines() # 讀取整個文件數(shù)據(jù)
for line in lines:
row = line.strip('\n').split(',') # 去除兩頭的換行符,按空格分割
datas.append(row)
fp.close()
return datas2)劃分數(shù)據(jù)集與測試集,將數(shù)據(jù)集的數(shù)據(jù)存入labeldata_list列表,標簽存入label_list列表,測試集數(shù)據(jù)存入text_list列表,標簽存入textlabel_list列表。
3)對得到的兩個數(shù)據(jù)集的數(shù)據(jù)和標簽列表進行處理。將labeldata_list列表數(shù)據(jù)轉(zhuǎn)換為元組labeldata_tuple,構(gòu)造形入{labeldata_tuple: label_list}的字典mydict。這樣不僅可以去掉重復數(shù)據(jù),而且可唯一的標識各個數(shù)據(jù)所對應(yīng)的鳶尾花種類。
for i in range(0, 105): # 數(shù)據(jù)集按照3:7的比例劃分,其中105行為訓練集,45行為測試集
labeldata_list.append([datas[i][0], datas[i][1], datas[i][2], datas[i][3]])
label_list.append(datas[i][4])
for i in range(105, 150): # 測試集的數(shù)據(jù)
text_list.append([datas[i][0], datas[i][1], datas[i][2], datas[i][3]])
textlabel_list.append(datas[i][4])
j = 0
for i in labeldata_list:
labeldata_tuple = tuple(i)
mydict.update({labeldata_tuple: label_list[j]})
j = j + 14)計算測試集數(shù)據(jù)與各個訓練集數(shù)據(jù)之間的距離,得到distance_list列表,外層循環(huán)進行一次,都會有一個該測試數(shù)據(jù)所對應(yīng)的與訓練數(shù)據(jù)最短距離。標記出該距離對應(yīng)的訓練集,在一個近鄰的條件下,這個訓練集的種類,就是該測試集的種類。
在計算距離時,使用絕對距離來計算。將每個訓練集對應(yīng)數(shù)據(jù)的屬性值相減后求和add,得到一個測試數(shù)據(jù)與每個樣本的距離,add的最小值就是距離最小值。
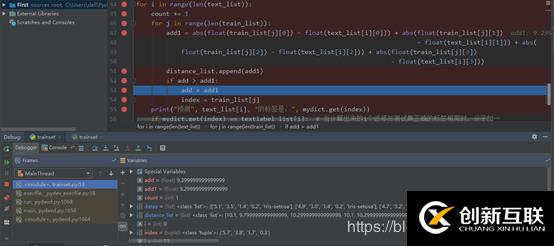
for i in range(len(text_list)):
count += 1
for j in range(len(train_list)):
add1 = abs(float(train_list[j][0]) - float(text_list[i][0])) + abs(float(train_list[j][1])
- float(text_list[i][1])) + abs(
float(train_list[j][2]) - float(text_list[i][2])) + abs(float(train_list[j][3])
- float(text_list[i][3]))
distance_list.append(add1)
if add > add1:
add = add1
index = train_list[j]
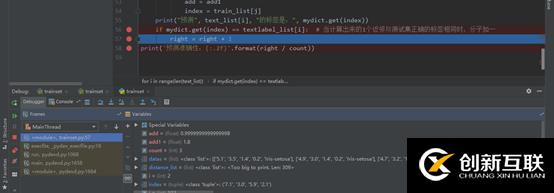
print("預(yù)測", text_list[i], "的標簽是:", mydict.get(index))5)判斷預(yù)測結(jié)果的準確性:將預(yù)測的測試數(shù)據(jù)種類與原始數(shù)據(jù)對比,若相同,則分子加一。
right = 0 # 分子
count = 0 # 分母
for i in range(len(text_list)):
count += 1
for j in range(len(train_list)):
add1 = abs(float(train_list[j][0]) - float(text_list[i][0])) + abs(float(train_list[j][1])
- float(text_list[i][1])) + abs(
float(train_list[j][2]) - float(text_list[i][2])) + abs(float(train_list[j][3])
- float(text_list[i][3]))
distance_list.append(add1)
if add > add1:
add = add1
index = train_list[j]
print("預(yù)測", text_list[i], "的標簽是:", mydict.get(index))
if mydict.get(index) == textlabel_list[i]: # 當計算出來的1個近鄰與測試集正確的標簽相同時,分子加一
right = right + 1
print('預(yù)測準確性:{:.2f}'.format(right / count))6)舉例,繪圖
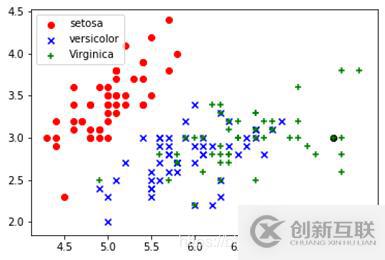
以測試集7.6,3.0,6.6,2.1,Iris-virginica為例:
首先運用anaconda繪制出數(shù)據(jù)集的散點圖,其次,將需要測試的數(shù)據(jù)于數(shù)據(jù)集繪制在同一張圖上,在一個近鄰的前提下,距離測試數(shù)據(jù)最近的點的標簽即為測試數(shù)據(jù)的的標簽。如下圖,黑色的測試點距離紅點最近,所以,測試數(shù)據(jù)的標簽就為virginica。
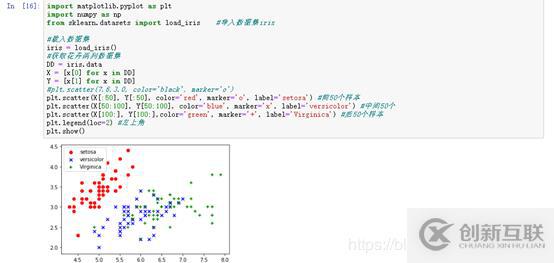
import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import load_iris #導入數(shù)據(jù)集iris #載入數(shù)據(jù)集 iris = load_iris() #獲取花卉兩列數(shù)據(jù)集 DD = iris.data X = [x[0] for x in DD] Y = [x[1] for x in DD] #plt.scatter(7.6,3.0, color='black', marker='o') plt.scatter(X[:50], Y[:50], color='red', marker='o', label='setosa') #前50個樣本 plt.scatter(X[50:100], Y[50:100], color='blue', marker='x', label='versicolor') #中間50個 plt.scatter(X[100:], Y[100:],color='green', marker='+', label='Virginica') #后50個樣本 plt.legend(loc=2) #左上角 plt.show()
算法數(shù)據(jù)流圖:
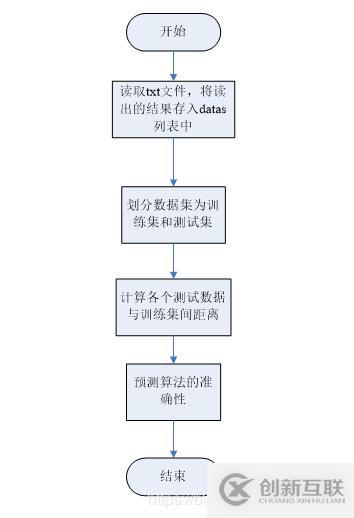
計算各個測試數(shù)據(jù)與訓練集間距離詳細流程圖:
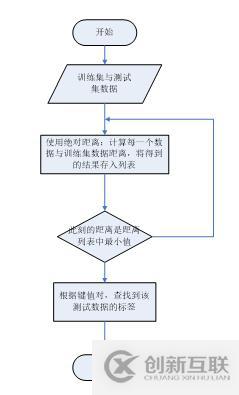
五、測試
導入數(shù)據(jù)集
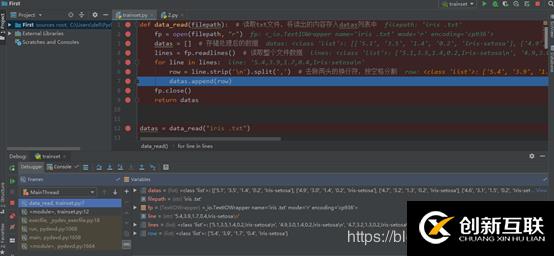
劃分數(shù)據(jù)集
訓練集:
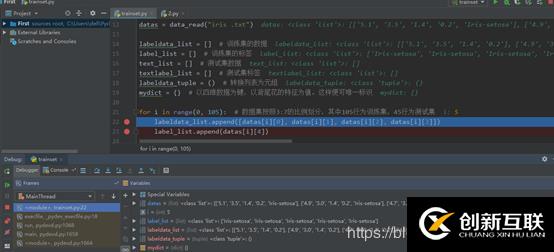
測試集:
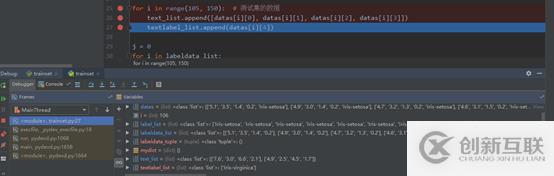
對得到的兩個數(shù)據(jù)集的數(shù)據(jù)和標簽列表進行處理
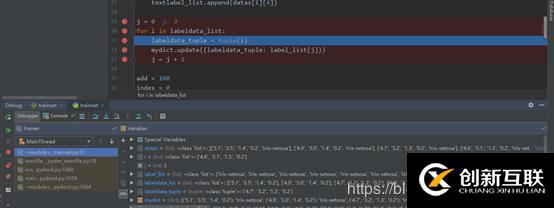
計算測試集數(shù)據(jù)與各個訓練集數(shù)據(jù)之間的距離
判斷預(yù)測結(jié)果的準確性
繪圖舉例
五、運行結(jié)果
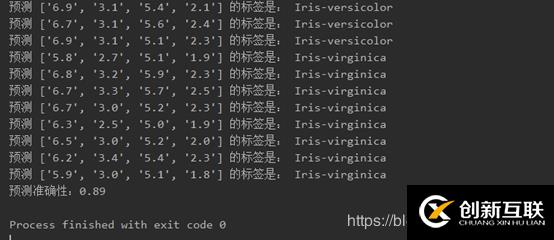
1.對測試集所有數(shù)據(jù)進行預(yù)測,得到預(yù)測測試集的標簽與預(yù)測準確性
繪出散點圖:7.6,3.0,6.6,2.1,Iris-virginica作為測試集的舉例
六、總結(jié)
學習了關(guān)于繪圖的函數(shù)與庫
發(fā)現(xiàn)在繪圖方面anaconde比pycharm要方便的多
對向量之間的距離公式進行了復習
除了這次作業(yè)中使用到的絕對距離之外,還有:
a)歐氏距離
兩個n維向量a(x11,x12,…,x1n)與 b(x21,x22,…,x2n)間的歐氏距離:
b)曼哈頓距離
兩個n維向量a(x11,x12,…,x1n)與 b(x21,x22,…,x2n)間的曼哈頓距離
c)閔可夫斯基距離
兩個n維變量a(x11,x12,…,x1n)與 b(x21,x22,…,x2n)間的閔可夫斯基距離定義為:
對文件的讀操作進行使用
算法缺點:用了許多for循環(huán),會降低效率,增加算法的時間復雜度;只是一個近鄰的判斷依據(jù)
七、源代碼
def data_read(filepath): # 讀取txt文件,將讀出的內(nèi)容存入datas列表中
fp = open(filepath, "r")
datas = [] # 存儲處理后的數(shù)據(jù)
lines = fp.readlines() # 讀取整個文件數(shù)據(jù)
for line in lines:
row = line.strip('\n').split(',') # 去除兩頭的換行符,按空格分割
datas.append(row)
fp.close()
return datas
datas = data_read("iris .txt")
labeldata_list = [] # 訓練集的數(shù)據(jù)
label_list = [] # 訓練集的標簽
text_list = [] # 測試集數(shù)據(jù)
textlabel_list = [] # 測試集標簽
labeldata_tuple = () # 轉(zhuǎn)換列表為元組
mydict = {} # 以四維數(shù)據(jù)為鍵,以鳶尾花的特征為值。這樣便可唯一標識
'''
劃分數(shù)據(jù)集與測試集,將數(shù)據(jù)集的數(shù)據(jù)存入labeldata_list列表,標簽存入label_list列表,
測試集數(shù)據(jù)存入text_list列表,標簽存入textlabel_list列表。
'''
for i in range(0, 105): # 數(shù)據(jù)集按照3:7的比例劃分,其中105行為訓練集,45行為測試集
labeldata_list.append([datas[i][0], datas[i][1], datas[i][2], datas[i][3]])
label_list.append(datas[i][4])
for i in range(105, 150): # 測試集的數(shù)據(jù)
text_list.append([datas[i][0], datas[i][1], datas[i][2], datas[i][3]])
textlabel_list.append(datas[i][4])
j = 0
for i in labeldata_list:
labeldata_tuple = tuple(i)
mydict.update({labeldata_tuple: label_list[j]})
j = j + 1
add = 100
index = 0
distance_list = []
train_list = []
for key, value in mydict.items():
train_list.append(key)
right = 0 # 分子
count = 0 # 分母
'''
在計算距離時,使用絕對距離來計算。
將每個訓練集對應(yīng)數(shù)據(jù)的屬性值相減后求和add,
得到一個測試數(shù)據(jù)與每個樣本的距離,add的最小值就是距離最小值。
'''
for i in range(len(text_list)):
count += 1
for j in range(len(train_list)):
add1 = abs(float(train_list[j][0]) - float(text_list[i][0])) + abs(float(train_list[j][1])
- float(text_list[i][1])) + abs(
float(train_list[j][2]) - float(text_list[i][2])) + abs(float(train_list[j][3])
- float(text_list[i][3]))
distance_list.append(add1)
if add > add1:
add = add1
index = train_list[j]
print("預(yù)測", text_list[i], "的標簽是:", mydict.get(index))
if mydict.get(index) == textlabel_list[i]: # 當計算出來的1個近鄰與測試集正確的標簽相同時,分子加一
right = right + 1
print('預(yù)測準確性:{:.2f}'.format(right / count))感謝各位的閱讀!關(guān)于“原生python如何實現(xiàn)knn分類算法”這篇文章就分享到這里了,希望以上內(nèi)容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
本文標題:原生python如何實現(xiàn)knn分類算法-創(chuàng)新互聯(lián)
本文來源:http://www.chinadenli.net/article10/doiddo.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供企業(yè)建站、網(wǎng)站導航、全網(wǎng)營銷推廣、品牌網(wǎng)站制作、外貿(mào)網(wǎng)站建設(shè)、App開發(fā)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- RAII和模擬實現(xiàn)智能指針-創(chuàng)新互聯(lián)
- java面向?qū)ο笾畬W生信息管理系統(tǒng)-創(chuàng)新互聯(lián)
- 邊緣計算工作負載:虛擬機,容器還是裸機?-創(chuàng)新互聯(lián)
- Java使用sftp定時下載文件的示例代碼-創(chuàng)新互聯(lián)
- microsoftonedrive指的是什么軟件-創(chuàng)新互聯(lián)
- PHP7中五種I/O模型以及同步、異步、阻塞和非阻塞的說明-創(chuàng)新互聯(lián)
- TIM改密碼報databaseconnectionfailed的問題-創(chuàng)新互聯(lián)

- 網(wǎng)站面包屑導航優(yōu)化設(shè)計應(yīng)當遵循用戶體驗習慣 2023-04-17
- 面包屑導航的優(yōu)化攻略 2022-05-25
- 網(wǎng)站優(yōu)化先行官:面包屑導航 2021-10-13
- 網(wǎng)站面包屑導航對網(wǎng)站優(yōu)化的作用以及影響 2014-11-17
- 網(wǎng)站面包屑導航使用四大注意事項 2022-08-23
- 面包屑導航對于網(wǎng)站的重要性? 2020-08-14
- 面包屑導航在網(wǎng)站中的作用 2021-12-20
- 深圳網(wǎng)站建設(shè)中面包屑導航的作用 2021-12-20
- 羅定網(wǎng)站建設(shè)為什么要做面包屑導航 2021-01-05
- 網(wǎng)站建設(shè)中面包屑導航的設(shè)計及使用 2022-08-07
- 網(wǎng)頁設(shè)計公司:面包屑導航優(yōu)化的必要性 2016-10-08
- 網(wǎng)站制作中的面包屑導航是什么? 2021-04-25