Kafka原理以及實戰(zhàn)分析是什么樣的
Kafka 原理以及實戰(zhàn)分析是什么樣的,相信很多沒有經(jīng)驗的人對此束手無策,為此本文總結(jié)了問題出現(xiàn)的原因和解決方法,通過這篇文章希望你能解決這個問題。
上杭網(wǎng)站制作公司哪家好,找創(chuàng)新互聯(lián)建站!從網(wǎng)頁設(shè)計、網(wǎng)站建設(shè)、微信開發(fā)、APP開發(fā)、響應(yīng)式網(wǎng)站等網(wǎng)站項目制作,到程序開發(fā),運營維護。創(chuàng)新互聯(lián)建站于2013年開始到現(xiàn)在10年的時間,我們擁有了豐富的建站經(jīng)驗和運維經(jīng)驗,來保證我們的工作的順利進行。專注于網(wǎng)站建設(shè)就選創(chuàng)新互聯(lián)建站。
背景
最近要把原來做的那套集中式日志監(jiān)控系統(tǒng)進行遷移,原來的實現(xiàn)方案是: Log Agent => Log Server => ElasticSearch => Kibana,其中Log Agent和Log Server之間走的是Thrift RPC,自己實現(xiàn)了一個簡單的負(fù)載均衡(WRB)。
原來的方案其實運行的挺好的,異步化Agent對應(yīng)用性能基本沒有影響。支持我們這個每天幾千萬PV的應(yīng)用一點壓力都沒有。不過有個缺點就是如果錯誤日志暴增,Log Server這塊處理不過來,會導(dǎo)致消息丟失。當(dāng)然我們量級沒有達到這個程度,而且也是可以通過引入隊列緩沖一下處理。不過現(xiàn)在綜合考慮,其實直接使用消息隊列會更簡單。PRC,負(fù)載均衡,負(fù)載緩沖都內(nèi)建實現(xiàn)了。另一種方式是直接讀取日志,類似于logstash或者flume的方式。不過考慮到靈活性還是決定使用消息隊列的方式,反正我們已經(jīng)部署了Zookeeper。調(diào)研了一下,Kafka是最適合做這個數(shù)據(jù)中轉(zhuǎn)和緩沖的。于是,打算把方案改成: Log Agent => Kafka => ElasticSearch => Kibana。
Kafka介紹
一、Kafka基本概念
Broker:Kafka集群包含一個或多個服務(wù)器,這種服務(wù)器被稱為broker。
Topic:每條發(fā)布到Kafka集群的消息都有一個類別,這個類別被稱為Topic。
Message
消息的偏移量: 8字節(jié),類似于消息的Id。
消息的總長度: 4字節(jié)
CRC32: CRC32校驗和,4個字節(jié)。
magic: Kafka服務(wù)程序協(xié)議版本號,用于做兼容。1個字節(jié)。
attributes: 該字段占1字節(jié),其中低兩位用來表示壓縮方式,第三位表示時間戳類型(0表示LogCreateTime,1表示LogAppendTime),高四位為預(yù)留位置,暫無實際意義。
timestamp: 消息時間戳,當(dāng)
magic > 0時消息頭必須包含該字段。8個字節(jié)。key-length: 消息key長度,4個字節(jié)。
key: 消息key實際數(shù)據(jù)。
payload-length: 消息實際數(shù)據(jù)長度,4個字節(jié)。
payload: 消息實際數(shù)據(jù)
消息是Kafka通訊的基本單位,有一個固定長度的消息頭和一個可變長度的消息體(payload)構(gòu)成。在Java客戶端中又稱之為記錄(Record)。
消息結(jié)構(gòu)各部分說明如下:
在實際存儲一條消息還包括12字節(jié)的額外開銷(LogOverhead):
Partition:
Partition(分區(qū))是物理上的概念,每個Topic包含一個或多個Partition。
每個分區(qū)由一系列有序的不可變的消息組成,是一個有序隊列。
每個分區(qū)在物理上對應(yīng)為一個文件夾,分區(qū)的命名規(guī)則為
${topicName}-{partitionId},如__consumer_offsets-0。分區(qū)目錄下存儲的是該分區(qū)的日志段,包括日志數(shù)據(jù)文件和兩個索引文件。
每條消息被追加到相應(yīng)的分區(qū)中,是順序?qū)懘疟P,因此效率非常高,這也是Kafka高吞吐率的一個重要保證。
kafka只能保證一個分區(qū)內(nèi)的消息的有序性,并不能保證跨分區(qū)消息的有序性。
LogSegment:
數(shù)據(jù)文件
偏移量索引文件
時間戳索引文件
數(shù)據(jù)文件是以
.log為文件后綴名的消息集文件(FileMessageSet),用于保存消息實際數(shù)據(jù)命名規(guī)則為:由數(shù)據(jù)文件的第一條消息偏移量,也稱之為基準(zhǔn)偏移量(
BaseOffset),左補0構(gòu)成20位數(shù)字字符組成每個數(shù)據(jù)文件的基準(zhǔn)偏移量就是上一個數(shù)據(jù)文件的
LEO+1(第一個數(shù)據(jù)文件為0)文件名與數(shù)據(jù)文件相同,但是以
.index為后綴名。它的目的是為了快速根據(jù)偏移量定位到消息所在的位置。首先Kafka將每個日志段以
BaseOffset為key保存到一個ConcurrentSkipListMap跳躍表中,這樣在查找指定偏移量的消息時,用二分查找法就能快速定位到消息所在的數(shù)據(jù)文件和索引文件然后在索引文件中通過二分查找,查找值小于等于指定偏移量的最大偏移量,最后從查找出的最大偏移量處開始順序掃描數(shù)據(jù)文件,直到在數(shù)據(jù)文件中查詢到偏移量與指定偏移量相等的消息
需要注意的是并不是每條消息都對應(yīng)有索引,而是采用了稀疏存儲的方式,每隔一定字節(jié)的數(shù)據(jù)建立一條索引,我們可以通過
index.interval.bytes設(shè)置索引跨度。Kafka從0.10.1.1版本開始引入了一個基于時間戳的索引文件,文件名與數(shù)據(jù)文件相同,但是以
.timeindex作為后綴。它的作用則是為了解決根據(jù)時間戳快速定位消息所在位置。Kafka API提供了一個
offsetsForTimes(Map<TopicPartition, Long> timestampsToSearch)方法,該方法會返回時間戳大于等于待查詢時間的第一條消息對應(yīng)的偏移量和時間戳。這個功能其實挺好用的,假設(shè)我們希望從某個時間段開始消費,就可以用offsetsForTimes()方法定位到離這個時間最近的第一條消息的偏移量,然后調(diào)用seek(TopicPartition, long offset)方法將消費者偏移量移動過去,然后調(diào)用poll()方法長輪詢拉取消息。日志文件按照大小或者時間滾動切分成一個或者多個日志段(LogSegment),其中日志段大小由配置項
log.segment.bytes指定,默認(rèn)是1GB。時間長度則是根據(jù)log.roll.ms或者log.roll.hours配置項設(shè)置;當(dāng)前活躍的日志段稱之為活躍段(activeSegment)。不同于普通的日志文件,Kafka的日志段除了有一個具體的日志文件之外,還有兩個輔助的索引文件:
Producer:
request.required.acks: Kafka為生產(chǎn)者提供了三種消息確認(rèn)機制(ACK),用于配置broker接到消息后向生產(chǎn)者發(fā)送確認(rèn)信息,以便生產(chǎn)者根據(jù)ACK進行相應(yīng)的處理,該機制通過屬性request.required.acks設(shè)置,取值可以為0, -1, 1,默認(rèn)是1。message.send.max.retries: 生產(chǎn)者在放棄該消息前進行重試的次數(shù),默認(rèn)是3次。retry.backoff.ms: 每次重試之前等待的時間,單位是ms,默認(rèn)是100。queue.buffering.max.ms: 在異步模式下,消息被緩存的最長時間,當(dāng)?shù)竭_該時間后消息被開始批量發(fā)送;若在異步模式下同時配置了緩存數(shù)據(jù)的最大值batch.num.messages,則達到這兩個閾值的任何一個就會觸發(fā)消息批量發(fā)送。默認(rèn)是1000ms。queue.buffering.max.messages: 在異步模式下,可以被緩存到隊列中的未發(fā)送的最大消息條數(shù)。默認(rèn)是10000。queue.enqueue.timeout.ms:batch.num.messages: Kafka支持批量消息(Batch)向broker的特定分區(qū)發(fā)送消息,批量大小由屬性batch.num.messages設(shè)置,表示每次批量發(fā)送消息的最大消息數(shù),當(dāng)生產(chǎn)者采用同步模式發(fā)送時改配置項將失效。默認(rèn)是200。request.timeout.ms: 在需要acks時,生產(chǎn)者等待broker應(yīng)答的超時時間。默認(rèn)是1500ms。send.buffer.bytes: Socket發(fā)送緩沖區(qū)大小。默認(rèn)是100kb。topic.metadata.refresh.interval.ms: 生產(chǎn)者定時請求更新主題元數(shù)據(jù)的時間間隔。若設(shè)置為0,則在每個消息發(fā)送后都會去請求更新數(shù)據(jù)。默認(rèn)是5min。client.id: 生產(chǎn)者id,主要方便業(yè)務(wù)用來追蹤調(diào)用定位問題。默認(rèn)是console-producer。acks=0: 生產(chǎn)者不需要等待broker返回確認(rèn)消息,而連續(xù)發(fā)送消息。
acks=1: 生產(chǎn)者需要等待Leader副本已經(jīng)成功將消息寫入日志文件中。這種方式在一定程度上降低了數(shù)據(jù)丟失的可能性,但仍無法保證數(shù)據(jù)一定不會丟失。因為沒有等待follower副本同步完成。
acks=-1: Leader副本和所有的ISR列表中的副本都完成數(shù)據(jù)存儲時才會向生產(chǎn)者發(fā)送確認(rèn)消息。為了保證數(shù)據(jù)不丟失,需要保證同步的副本至少大于1,通過參數(shù)
min.insync.replicas設(shè)置,當(dāng)同步副本數(shù)不足次配置項時,生產(chǎn)者會拋出異常。但是這種方式同時也影響了生產(chǎn)者發(fā)送消息的速度以及吞吐率。=0: 表示當(dāng)隊列沒滿時直接入隊,滿了則立即丟棄<0: 表示無條件阻塞且不丟棄>0: 表示阻塞達到該值時長拋出QueueFullException異常負(fù)責(zé)發(fā)布消息到Kafka broker。
生產(chǎn)者的一些重要的配置項:
Consumer & Consumer Group & Group Coordinator:
group.id: A unique string that identifies the consumer group this consumer belongs to.
client.id: The client id is a user-specified string sent in each request to help trace calls. It should logically identify the application making the request.
bootstrap.servers: A list of host/port pairs to use for establishing the initial connection to the Kafka cluster.
key.deserializer: Deserializer class for key that implements the org.apache.kafka.common.serialization.Deserializer interface.
value.deserializer: Deserializer class for value that implements the org.apache.kafka.common.serialization.Deserializer interface.
fetch.min.bytes: The minimum amount of data the server should return for a fetch request. If insufficient data is available the request will wait for that much data to accumulate before answering the request.
fetch.max.bytes: The maximum amount of data the server should return for a fetch request.
max.partition.fetch.bytes: The maximum amount of data per-partition the server will return.
max.poll.records: The maximum number of records returned in a single call to poll().
heartbeat.interval.ms: The expected time between heartbeats to the consumer coordinator when using Kafka’s group management facilities.
session.timeout.ms: The timeout used to detect consumer failures when using Kafka’s group management facility.
enable.auto.commit: If true the consumer’s offset will be periodically committed in the background.
自動提交: 并不是定時周期性提交,而是在一些特定事件發(fā)生時才檢測與上一次提交的時間間隔是否超過
auto.commit.interval.ms。手動提交
enable.auto.commit=trueauto.commit.interval.msenable.auto.commit=falsecommitSync(): 同步提交commitAsync(): 異步提交Consumer: 消息消費者,向Kafka broker讀取消息的客戶端。Kafka0.9版本發(fā)布了基于Java重新寫的新的消費者,它不再依賴scala運行時環(huán)境和zookeeper。
Consumer Group: 每個消費者都屬于一個特定的Consumer Group,可通過
group.id配置項指定,若不指定group name則默認(rèn)為test-consumer-group。Group Coordinator: 對于每個Consumer group,會選擇一個brokers作為消費組的協(xié)調(diào)者。
每個消費者也有一個全局唯一的id,可通過配置項
client.id指定,如果不指定,Kafka會自動為該消費者生成一個格式為${groupId}-${hostName}-${timestamp}-${UUID前8個字符}的全局唯一id。Kafka提供了兩種提交consumer_offset的方式:Kafka自動提交 或者 客戶端調(diào)用KafkaConsumer相應(yīng)API手動提交。
消費者的一些重要的配置項:
ISR: Kafka在ZK中動態(tài)維護了一個ISR(In-Sync Replica),即保持同步的副本列表,該列表中保存的是與leader副本保持消息同步的所有副本對應(yīng)的brokerId。如果一個副本宕機或者落后太多,則該follower副本將從ISR列表中移除。
Zookeeper:
/consumers: 舊版消費者啟動后會在ZK的該節(jié)點下創(chuàng)建一個消費者的節(jié)點
/brokers/seqid: 輔助生成的brokerId,當(dāng)用戶沒有配置
broker.id時,ZK會自動生成一個全局唯一的id。/brokers/topics: 每創(chuàng)建一個主題就會在該目錄下創(chuàng)建一個與該主題同名的節(jié)點。
/borkers/ids: 當(dāng)Kafka每啟動一個KafkaServer時就會在該目錄下創(chuàng)建一個名為
{broker.id}的子節(jié)點/config/topics: 存儲動態(tài)修改主題級別的配置信息
/config/clients: 存儲動態(tài)修改客戶端級別的配置信息
/config/changes: 動態(tài)修改配置時存儲相應(yīng)的信息
/admin/delete_topics: 在對主題進行刪除操作時保存待刪除主題的信息
/cluster/id: 保存集群id信息
/controller: 保存控制器對應(yīng)的brokerId信息等
/isr_change_notification: 保存Kafka副本ISR列表發(fā)生變化時通知的相應(yīng)路徑
Kafka利用ZK保存相應(yīng)的元數(shù)據(jù)信息,包括:broker信息,Kafka集群信息,舊版消費者信息以及消費偏移量信息,主題信息,分區(qū)狀態(tài)信息,分區(qū)副本分片方案信息,動態(tài)配置信息,等等。
Kafka在zk中注冊節(jié)點說明:
Kafka在啟動或者運行過程中會在ZK上創(chuàng)建相應(yīng)的節(jié)點來保存元數(shù)據(jù)信息,通過監(jiān)聽機制在這些節(jié)點注冊相應(yīng)的監(jiān)聽器來監(jiān)聽節(jié)點元數(shù)據(jù)的變化。
TIPS
如果跟ES對應(yīng),Broker相當(dāng)于Node,Topic相當(dāng)于Index,Message相對于Document,而Partition相當(dāng)于shard。LogSegment相對于ES的Segment。
如何查看消息內(nèi)容(Dump Log Segments)
我們在使用kafka的過程中有時候可以需要查看我們生產(chǎn)的消息的各種信息,這些消息是存儲在kafka的日志文件中的。由于日志文件的特殊格式,我們是無法直接查看日志文件中的信息內(nèi)容。Kafka提供了一個命令,可以將二進制分段日志文件轉(zhuǎn)儲為字符類型的文件:
$ bin/kafka-run-class.sh kafka.tools.DumpLogSegments Parse a log file and dump its contents to the console, useful for debugging a seemingly corrupt log segment. Option Description ------ ----------- --deep-iteration 使用深迭代而不是淺迭代 --files <file1, file2, ...> 必填。輸入的日志段文件,逗號分隔 --key-decoder-class 自定義key值反序列化器。必須實現(xiàn)`kafka.serializer.Decoder` trait。所在jar包需要放在`kafka/libs`目錄下。(默認(rèn)是`kafka.serializer.StringDecoder`)。 --max-message-size <Integer: size> 消息最大的字節(jié)數(shù)(默認(rèn)為5242880) --print-data-log 同時打印出日志消息 --value-decoder-class 自定義value值反序列化器。必須實現(xiàn)`kafka.serializer.Decoder` trait。所在jar包需要放在`kafka/libs`目錄下。(默認(rèn)是`kafka.serializer.StringDecoder`)。 --verify-index-only 只是驗證索引不打印索引內(nèi)容
$ bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/test-0/00000000000000000000.log --print-data-log Dumping /tmp/kafka-logs/test-0/00000000000000000000.log Starting offset: 0 offset: 0 position: 0 CreateTime: 1498104812192 isvalid: true payloadsize: 11 magic: 1 compresscodec: NONE crc: 3271928089 payload: hello world offset: 1 position: 45 CreateTime: 1498104813269 isvalid: true payloadsize: 14 magic: 1 compresscodec: NONE crc: 242183772 payload: hello everyone
注意:這里 --print-data-log 是表示查看消息內(nèi)容的,不加此項只能看到Header,看不到payload。
也可以用來查看index文件:
$ bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/test-0/00000000000000000000.index --print-data-log Dumping /tmp/kafka-logs/test-0/00000000000000000000.index offset: 0 position: 0
timeindex文件也是OK的:
$ bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/test-0/00000000000000000000.timeindex --print-data-log Dumping /tmp/kafka-logs/test-0/00000000000000000000.timeindex timestamp: 1498104813269 offset: 1 Found timestamp mismatch in :/tmp/kafka-logs/test-0/00000000000000000000.timeindex Index timestamp: 0, log timestamp: 1498104812192. Found out of order timestamp in :/tmp/kafka-logs/test-0/00000000000000000000.timeindex Index timestamp: 0, Previously indexed timestamp: 1498104813269
消費者平衡過程
消費者平衡(Consumer Rebalance)是指的是消費者重新加入消費組,并重新分配分區(qū)給消費者的過程。在以下情況下會引起消費者平衡操作:
新的消費者加入消費組
當(dāng)前消費者從消費組退出(不管是異常退出還是正常關(guān)閉)
消費者取消對某個主題的訂閱
訂閱主題的分區(qū)增加(Kafka的分區(qū)數(shù)可以動態(tài)增加但是不能減少)
broker宕機新的協(xié)調(diào)器當(dāng)選
當(dāng)消費者在${session.timeout.ms}時間內(nèi)還沒有發(fā)送心跳請求,組協(xié)調(diào)器認(rèn)為消費者已退出。
消費者自動平衡操作提供了消費者的高可用和高可擴展性,這樣當(dāng)我們增加或者減少消費者或者分區(qū)數(shù)的時候,不需要關(guān)心底層消費者和分區(qū)的分配關(guān)系。但是需要注意的是,在rebalancing過程中,由于需要給消費者重新分配分區(qū),所以會出現(xiàn)在一個短暫時間內(nèi)消費者不能拉取消息的狀況。
NOTES
這里要特別注意最后一種情況,就是所謂的慢消費者(Slow Consumers)。如果沒有在session.timeout.ms時間內(nèi)收到心跳請求,協(xié)調(diào)者可以將慢消費者從組中移除。通常,如果消息處理比session.timeout.ms慢,就會成為慢消費者。導(dǎo)致兩次poll()方法的調(diào)用間隔比session.timeout.ms時間長。由于心跳只在 poll()調(diào)用時才會發(fā)送(在0.10.1.0版本中, 客戶端心跳在后臺異步發(fā)送了),這就會導(dǎo)致協(xié)調(diào)者標(biāo)記慢消費者死亡。
如果沒有在session.timeout.ms時間內(nèi)收到心跳請求,協(xié)調(diào)者標(biāo)記消費者死亡并且斷開和它的連接。同時,通過向組內(nèi)其他消費者的HeartbeatResponse中發(fā)送IllegalGeneration錯誤代碼 觸發(fā)rebalance操作。
在手動commit offset的模式下,要特別注意這個問題,否則會出現(xiàn)commit不上的情況。導(dǎo)致一直在重復(fù)消費。
二、Kafka的特點
消息順序:保證每個partition內(nèi)部的順序,但是不保證跨partition的全局順序。如果需要全局消息有序,topic只能有一個partition。
consumer group:consumer group中的consumer并發(fā)獲取消息,但是為了保證partition消息的順序性,每個partition只會由一個consumer消費。因此consumer group中的consumer數(shù)量需要小于等于topic的partition個數(shù)。(如需全局消息有序,只能有一個partition,一個consumer)
同一Topic的一條消息只能被同一個Consumer Group內(nèi)的一個Consumer消費,但多個Consumer Group可同時消費這一消息。這是Kafka用來實現(xiàn)一個Topic消息的廣播(發(fā)給所有的Consumer)和單播(發(fā)給某一個Consumer)的手段。一個Topic可以對應(yīng)多個Consumer Group。如果需要實現(xiàn)廣播,只要每個Consumer有一個獨立的Group就可以了。要實現(xiàn)單播只要所有的Consumer在同一個Group里。
Producer Push消息,Client Pull消息模式:一些logging-centric system,比如Facebook的Scribe和Cloudera的Flume,采用push模式。事實上,push模式和pull模式各有優(yōu)劣。push模式很難適應(yīng)消費速率不同的消費者,因為消息發(fā)送速率是由broker決定的。push模式的目標(biāo)是盡可能以最快速度傳遞消息,但是這樣很容易造成Consumer來不及處理消息,典型的表現(xiàn)就是拒絕服務(wù)以及網(wǎng)絡(luò)擁塞。而pull模式則可以根據(jù)Consumer的消費能力以適當(dāng)?shù)乃俾氏M消息。pull模式可簡化broker的設(shè)計,Consumer可自主控制消費消息的速率,同時Consumer可以自己控制消費方式——即可批量消費也可逐條消費,同時還能選擇不同的提交方式從而實現(xiàn)不同的傳輸語義。
實際上,Kafka的設(shè)計理念之一就是同時提供離線處理和實時處理。根據(jù)這一特性,可以使用Storm或Spark Streaming這種實時流處理系統(tǒng)對消息進行實時在線處理,同時使用Hadoop這種批處理系統(tǒng)進行離線處理,還可以同時將數(shù)據(jù)實時備份到另一個數(shù)據(jù)中心,只需要保證這三個操作所使用的Consumer屬于不同的Consumer Group即可。
三、kafka的HA
Kafka在0.8以前的版本中,并不提供High Availablity機制,一旦一個或多個Broker宕機,則宕機期間其上所有Partition都無法繼續(xù)提供服務(wù)。若該Broker永遠(yuǎn)不能再恢復(fù),亦或磁盤故障,則其上數(shù)據(jù)將丟失。而Kafka的設(shè)計目標(biāo)之一即是提供數(shù)據(jù)持久化,同時對于分布式系統(tǒng)來說,尤其當(dāng)集群規(guī)模上升到一定程度后,一臺或者多臺機器宕機的可能性大大提高,對Failover要求非常高。因此,Kafka從0.8開始提供High Availability機制。主要表現(xiàn)在Data Replication和Leader Election兩方面。
Data Replication
Kafka從0.8開始提供partition級別的replication,replication的數(shù)量可在
$KAFKA_HOME/config/server.properties 中配置:
default.replication.factor = 1
該 Replication與leader election配合提供了自動的failover機制。replication對Kafka的吞吐率是有一定影響的,但極大的增強了可用性。默認(rèn)情況下,Kafka的replication數(shù)量為1。每個partition都有一個唯一的leader,所有的讀寫操作都在leader上完成,follower批量從leader上pull數(shù)據(jù)。一般情況下partition的數(shù)量大于等于broker的數(shù)量,并且所有partition的leader均勻分布在broker上。follower上的日志和其leader上的完全一樣。
需要注意的是,replication factor并不會影響consumer的吞吐率測試,因為consumer只會從每個partition的leader讀數(shù)據(jù),而與replicaiton factor無關(guān)。同樣,consumer吞吐率也與同步復(fù)制還是異步復(fù)制無關(guān)。
Leader Election
引入Replication之后,同一個Partition可能會有多個副本(Replica),而這時需要在這些副本之間選出一個Leader,Producer和Consumer只與這個Leader副本交互,其它Replica作為Follower從Leader中復(fù)制數(shù)據(jù)。注意,只有Leader負(fù)責(zé)數(shù)據(jù)讀寫,F(xiàn)ollower只向Leader順序Fetch數(shù)據(jù)(N條通路),并不提供任何讀寫服務(wù),系統(tǒng)更加簡單且高效。
思考 為什么follower副本不提供讀寫,只做冷備?
follwer副本不提供寫服務(wù)這個比較好理解,因為如果follower也提供寫服務(wù)的話,那么就需要在所有的副本之間相互同步。n個副本就需要 nxn 條通路來同步數(shù)據(jù),如果采用異步同步的話,數(shù)據(jù)的一致性和有序性是很難保證的;而采用同步方式進行數(shù)據(jù)同步的話,那么寫入延遲其實是放大n倍的,反而適得其反。
那么為什么不讓follower副本提供讀服務(wù),減少leader副本的讀壓力呢?這個除了因為同步延遲帶來的數(shù)據(jù)不一致之外,不同于其他的存儲服務(wù)(如ES,MySQL),Kafka的讀取本質(zhì)上是一個有序的消息消費,消費進度是依賴于一個叫做offset的偏移量,這個偏移量是要保存起來的。如果多個副本進行讀負(fù)載均衡,那么這個偏移量就不好確定了。
TIPS
Kafka的leader副本類似于ES的primary shard,follower副本相對于ES的replica。ES也是一個index有多個shard(相對于Kafka一個topic有多個partition),shard又分為primary shard和replicition shard,其中primary shard用于提供讀寫服務(wù)(sharding方式跟MySQL非常類似:shard = hash(routing) % number_of_primary_shards。但是ES引入了協(xié)調(diào)節(jié)點(coordinating node) 的角色,實現(xiàn)對客戶端透明。),而replication shard只提供讀服務(wù)(這里跟Kafka一樣,ES會等待relication shard返回成功才最終返回給client)。
有傳統(tǒng)MySQL分庫分表經(jīng)驗的同學(xué)一定會覺得這個過程是非常相似的,就是一個sharding + replication的數(shù)據(jù)架構(gòu),只是通過client(SDK)或者coordinator對你透明了而已。
Propagate消息
Producer在發(fā)布消息到某個Partition時,先通過ZooKeeper找到該Partition的Leader,然后無論該Topic的Replication Factor為多少(也即該Partition有多少個Replica),Producer只將該消息發(fā)送到該Partition的Leader。Leader會將該消息寫入其本地Log。每個Follower都從Leader pull數(shù)據(jù)。這種方式上,F(xiàn)ollower存儲的數(shù)據(jù)順序與Leader保持一致。Follower在收到該消息并寫入其Log后,向Leader發(fā)送ACK。一旦Leader收到了 ISR (in-sync replicas) 中的所有Replica的ACK,該消息就被認(rèn)為已經(jīng)commit了,Leader將增加 HW( High-Watermark) 并且向Producer發(fā)送ACK。
為了提高性能,每個Follower在接收到數(shù)據(jù)后就立馬向Leader發(fā)送ACK,而非等到數(shù)據(jù)寫入Log中。因此,對于已經(jīng)commit的消息,Kafka只能保證它被存于多個Replica的內(nèi)存中,而不能保證它們被持久化到磁盤中,也就不能完全保證異常發(fā)生后該條消息一定能被Consumer消費。但考慮到這種場景非常少見,可以認(rèn)為這種方式在性能和數(shù)據(jù)持久化上做了一個比較好的平衡。在將來的版本中,Kafka會考慮提供更高的持久性。
Consumer讀消息也是從Leader讀取,只有被commit過的消息(offset低于HW的消息)才會暴露給Consumer。
Kafka Replication的數(shù)據(jù)流如下圖所示:
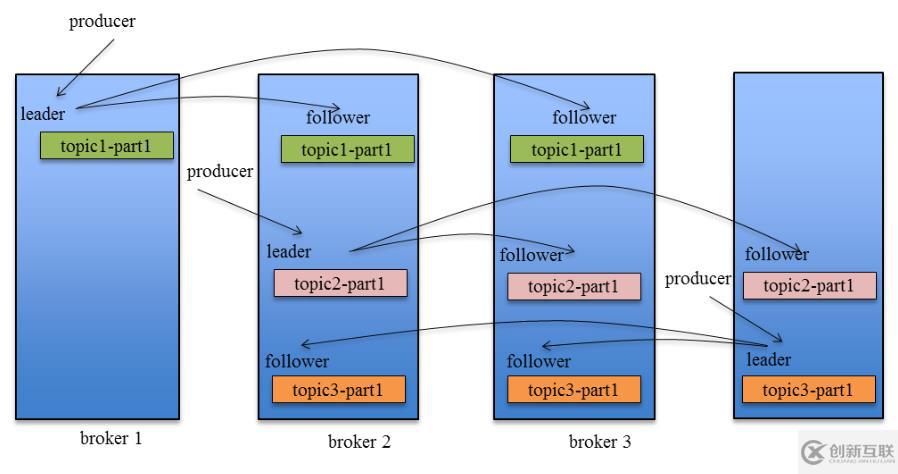
關(guān)于這方面的內(nèi)容比較多而且復(fù)雜,這里就不展開了,這篇文章寫的很好,有興趣的同學(xué)可以學(xué)習(xí)
《 Kafka設(shè)計解析(二):Kafka High Availability (上)》。
Kafka的幾個游標(biāo)(偏移量/offset)
下面這張圖非常簡單明了的顯示kafka的所有游標(biāo)
(https://rongxinblog.wordpress.com/2016/07/29/kafka-high-watermark/):
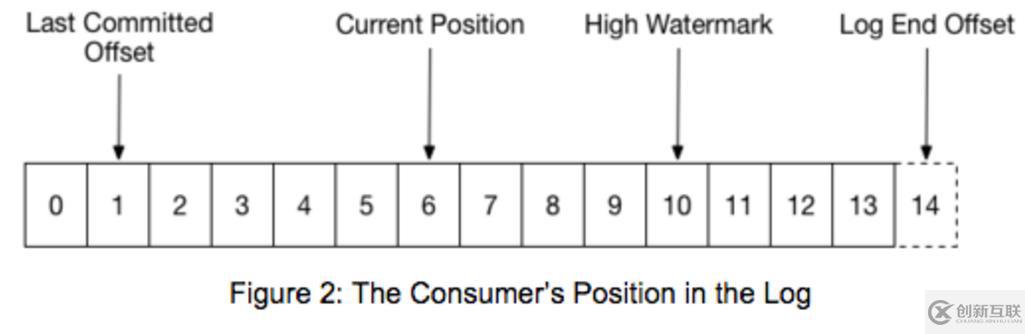
下面簡單的說明一下:
0、ISR
In-Sync Replicas list,顧名思義,就是跟leader “保存同步” 的Replicas。“保持同步”的含義有些復(fù)雜,在0.9版本,broker的參數(shù)replica.lag.time.max.ms用來指定ISR的定義,如果leader在這么長時間沒收到follower的拉取請求,或者在這么長時間內(nèi),follower沒有fetch到leader的log end offset,就會被leader從ISR中移除。ISR是個很重要的指標(biāo),controller選取partition的leader replica時會使用它,leader需要維護ISR列表,因此leader選取ISR后會把結(jié)果記到Zookeeper上。
在需要選舉leader的場景下,leader和ISR是由controller決定的。在選出leader以后,ISR是leader決定。如果誰是leader和ISR只存在于ZK上,那么每個broker都需要在Zookeeper上監(jiān)聽它host的每個partition的leader和ISR的變化,這樣效率比較低。如果不放在Zookeeper上,那么當(dāng)controller fail以后,需要從所有broker上重新獲得這些信息,考慮到這個過程中可能出現(xiàn)的問題,也不靠譜。所以leader和ISR的信息存在于Zookeeper上,但是在變更leader時,controller會先在Zookeeper上做出變更,然后再發(fā)送LeaderAndIsrRequest給相關(guān)的broker。這樣可以在一個LeaderAndIsrRequest里包括這個broker上有變動的所有partition,即batch一批變更新信息給broker,更有效率。另外,在leader變更ISR時,會先在Zookeeper上做出變更,然后再修改本地內(nèi)存中的ISR。
1、Last Commited Offset
Consumer最后提交的位置,這個位置會保存在一個特殊的topic:_consumer_offsets 中。
2、Current Position
Consumer當(dāng)前讀取的位置,但是還沒有提交給broker。提交之后就變成Last Commit Offset。
3、High Watermark(HW)
這個offset是所有ISR的LEO的最小位置(minimum LEO across all the ISR of this partition),consumer不能讀取超過HW的消息,因為這意味著讀取到未完全同步(因此沒有完全備份)的消息。換句話說就是:HW是所有ISR中的節(jié)點都已經(jīng)復(fù)制完的消息.也是消費者所能獲取到的消息的最大offset(注意,并不是所有replica都一定有這些消息,而只是ISR里的那些才肯定會有)。
隨著follower的拉取進度的即時變化,HW是隨時在變化的。follower總是向leader請求自己已有messages的下一個offset開始的數(shù)據(jù),因此當(dāng)follower發(fā)出了一個fetch request,要求offset為A以上的數(shù)據(jù),leader就知道了這個follower的log end offset至少為A。此時就可以統(tǒng)計下ISR里的所有replica的LEO是否已經(jīng)大于了HW,如果是的話,就提高了HW。同時,leader在fetch本地消息給follower時,也會在返回給follower的reponse里附帶自己的HW。這樣follower也就知道了leader處的HW(但是在實現(xiàn)中,follower獲取的只是讀leader本地log時的HW,并不能保證是最新的HW)。但是leader和follower的HW是不同步的,follower處記的HW可能會落后于leader。
Hight Watermark Checkpoint
由于HW是隨時變化的,如果即時更新到Zookeeper,會帶來效率的問題。而HW是如此重要,因此需要持久化,ReplicaManager就啟動了單獨的線程定期把所有的partition的HW的值記到文件中,即做highwatermark-checkpoint。
####4、Log End Offset(LEO)
這個很好理解,就是當(dāng)前的最新日志寫入(或者同步)位置。
四、Kafka客戶端
Kafka支持JVM語言(java、scala),同是也提供了高性能的C/C++客戶端,和基于librdkafka封裝的各種語言客戶端。如,Python客戶端: confluent-kafka-python 。Python客戶端還有純python實現(xiàn)的:kafka-python。
下面是Python例子(以confluent-kafka-python為例):
Producer:
from confluent_kafka import Producer
p = Producer({'bootstrap.servers': 'mybroker,mybroker2'})
for data in some_data_source:
p.produce('mytopic', data.encode('utf-8'))
p.flush()
Consumer:
from confluent_kafka import Consumer, KafkaError
c = Consumer({'bootstrap.servers': 'mybroker', 'group.id': 'mygroup',
'default.topic.config': {'auto.offset.reset': 'smallest'}})
c.subscribe(['mytopic'])
running = True
while running:
msg = c.poll()
if not msg.error():
print('Received message: %s' % msg.value().decode('utf-8'))
elif msg.error().code() != KafkaError._PARTITION_EOF:
print(msg.error())
running = False
c.close()
跟普通的消息隊列使用基本是一樣的。
五、Kafka的offset管理
kafka讀取消息其實是基于offset來進行的,如果offset出錯,就可能出現(xiàn)重復(fù)讀取消息或者跳過未讀消息。在0.8.2之前,kafka是將offset保存在ZooKeeper中,但是我們知道zk的寫操作是很昂貴的,而且不能線性拓展,頻繁的寫入zk會導(dǎo)致性能瓶頸。所以在0.8.2引入了Offset Management,將這個offset保存在一個 compacted kafka topic(_consumer_offsets),Consumer通過發(fā)送OffsetCommitRequest請求到指定broker(偏移量管理者)提交偏移量。這個請求中包含一系列分區(qū)以及在這些分區(qū)中的消費位置(偏移量)。偏移量管理者會追加鍵值(key-value)形式的消息到一個指定的topic(__consumer_offsets)。key是由consumerGroup-topic-partition組成的,而value是偏移量。同時為了提供xing能,內(nèi)存中也會維護一份最近的記錄,這樣在指定key的情況下能快速的給出OffsetFetchRequests而不用掃描全部偏移量topic日志。如果偏移量管理者因某種原因失敗,新的broker將會成為偏移量管理者并且通過掃描偏移量topic來重新生成偏移量緩存。
如何查看消費偏移量
0.9版本之前的Kafka提供了kafka-consumer-offset-checker.sh腳本,可以用來查看某個消費組對一個或者多個topic的消費者消費偏移量情況,該腳本調(diào)用的是
kafka.tools.Consumer.OffsetChecker。0.9版本之后已不再建議使用該腳本了,而是建議使用kafka-consumer-groups.sh腳本,該腳本調(diào)用的是kafka.admin.ConsumerGroupCommand。這個腳本其實是對消費組進行管理,不只是查看消費組的偏移量。這里只介紹最新的kafka-consumer-groups.sh腳本使用。
用ConsumerGroupCommand工具,我們可以使用list,describe,或delete消費者組。
例如,要列出所有主題中的所有消費組信息,使用list參數(shù):
$ bin/kafka-consumer-groups.sh --bootstrap-server broker1:9092 --list test-consumer-group
要查看某個消費組當(dāng)前的消費偏移量則使用describe參數(shù):
$ bin/kafka-consumer-groups.sh --bootstrap-server broker1:9092 --describe --group test-consumer-group GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG OWNER test-consumer-group test-foo 0 1 3 2 consumer-1_/127.0.0.1
NOTES
該腳本只支持刪除不包括任何消費組的消費組,而且只能刪除消費組為老版本消費者對應(yīng)的消費組(即分組元數(shù)據(jù)存儲在zookeeper的才有效),因為這個腳本刪除操作的本質(zhì)就是刪除ZK中對應(yīng)消費組的節(jié)點及其子節(jié)點而已。
如何管理消費偏移量
上面介紹了通過腳本工具方式查詢Kafka消費偏移量。事實上,我們也可以通過API的方式查詢消費偏移量。
Kafka消費者API提供了兩個方法用于查詢消費者消費偏移量的操作:
committed(TopicPartition partition): 該方法返回一個OffsetAndMetadata對象,通過它可以獲取指定分區(qū)已提交的偏移量。
position(TopicPartition partition): 該方法返回下一次拉取位置的position。
除了查看消費偏移量,有些時候我們需要人為的指定offset,比如跳過某些消息,或者redo某些消息。在0.8.2之前,offset是存放在ZK中,只要用ZKCli操作ZK就可以了。但是在0.8.2之后,offset默認(rèn)是存放在kafka的__consumer_offsets隊列中,只能通過API修改了:
Class KafkaConsumer<K,V> Kafka allows specifying the position using seek(TopicPartition, long) to specify the new position. Special methods for seeking to the earliest and latest offset the server maintains are also available (seekToBeginning(TopicPartition…) and seekToEnd(TopicPartition…) respectively).
參考文檔: Kafka Consumer Offset Management
Kafka消費者API提供了重置消費偏移量的方法:
seek(TopicPartition partition, long offset): 該方法用于將消費起始位置重置到指定的偏移量位置。
seekToBeginning(): 從消息起始位置開始消費,對應(yīng)偏移量重置策略
auto.offset.reset=earliest。
seekToEnd(): 從最新消息對應(yīng)的位置開始消費,也就是說等待新的消息寫入后才開始拉取,對應(yīng)偏移量重置策略是
auto.offset.reset=latest。
當(dāng)然前提你得知道要重置的offset的位置。一種方式就是根據(jù)時間戳獲取對應(yīng)的offset。再seek過去。
部署和配置
Kafka是用Scala寫的,所以只要安裝了JRE環(huán)境,運行非常簡單。直接下載官方編譯好的包,解壓配置一下就可以直接運行了。
一、kafka配置
配置文件在config目錄下的server.properties,關(guān)鍵配置如下(有些屬性配置文件中默認(rèn)沒有,需自己添加):
broker.id:Kafka集群中每臺機器(稱為broker)需要獨立不重的id port:監(jiān)聽端口 delete.topic.enable:設(shè)為true則允許刪除topic,否則不允許 message.max.bytes:允許的最大消息大小,默認(rèn)是1000012(1M),建議調(diào)到到10000012(10M)。 replica.fetch.max.bytes: 同上,默認(rèn)是1048576,建議調(diào)到到10048576。 log.dirs:Kafka數(shù)據(jù)文件的存放目錄,注意不是日志文件。可以配置為:/home/work/kafka/data/kafka-logs log.cleanup.policy:過期數(shù)據(jù)清除策略,默認(rèn)為delete,還可設(shè)為compact log.retention.hours:數(shù)據(jù)過期時間(小時數(shù)),默認(rèn)是1073741824,即一周。過期數(shù)據(jù)用log.cleanup.policy的規(guī)則清除。可以用log.retention.minutes配置到分鐘級別。 log.segment.bytes:數(shù)據(jù)文件切分大小,默認(rèn)是1073741824(1G)。 retention.check.interval.ms:清理線程檢查數(shù)據(jù)是否過期的間隔,單位為ms,默認(rèn)是300000,即5分鐘。 zookeeper.connect:負(fù)責(zé)管理Kafka的zookeeper集群的機器名:端口號,多個用逗號分隔
TIPS 發(fā)送和接收大消息
需要修改如下參數(shù):
broker:message.max.bytes
& replica.fetch.max.bytes
consumer:fetch.message.max.bytes
更多參數(shù)的詳細(xì)說明見官方文檔:
http://kafka.apache.org/documentation.html#brokerconfigs
二、ZK配置和啟動
然后先確保ZK已經(jīng)正確配置和啟動了。Kafka自帶ZK服務(wù),配置文件在config/zookeeper.properties文件,關(guān)鍵配置如下:
dataDir=/home/work/kafka/data/zookeeper clientPort=2181 maxClientCnxns=0 tickTime=2000 initLimit=10 syncLimit=5 server.1=nj03-bdg-kg-offline-01.nj03:2888:3888 server.2=nj03-bdg-kg-offline-02.nj03:2888:3888 server.3=nj03-bdg-kg-offline-03.nj03:2888:3888
NOTES Zookeeper集群部署
ZK的集群部署要做兩件事情:
分配serverId: 在dataDir目錄下創(chuàng)建一個myid文件,文件中只包含一個1到255的數(shù)字,這就是ZK的serverId。
配置集群:格式為server.{id}={host}:{port}:{port},其中{id}就是上面提到的ZK的serverId。
然后啟動:
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties。
三、啟動kafka
然后可以啟動Kafka:JMX_PORT=8999 bin/kafka-server-start.sh -daemon config/server.properties,非常簡單。
TIPS
我們在啟動命令中增加了JMX_PORT=8999環(huán)境變量,這樣可以暴露JMX監(jiān)控項,方便監(jiān)控。
Kafka監(jiān)控和管理
不過不像RabbitMQ,或者ActiveMQ,Kafka默認(rèn)并沒有web管理界面,只有命令行語句,不是很方便,不過可以安裝一個,比如,Yahoo的 Kafka Manager: A tool for managing Apache Kafka。它支持很多功能:
Manage multiple clusters
Easy inspection of cluster state (topics, consumers, offsets, brokers, replica distribution, partition distribution)
Run preferred replica election
Generate partition assignments with option to select brokers to use
Run reassignment of partition (based on generated assignments)
Create a topic with optional topic configs (0.8.1.1 has different configs than 0.8.2+)
Delete topic (only supported on 0.8.2+ and remember set delete.topic.enable=true in broker config)
Topic list now indicates topics marked for deletion (only supported on 0.8.2+)
Batch generate partition assignments for multiple topics with option to select brokers to use
Batch run reassignment of partition for multiple topics
Add partitions to existing topic
Update config for existing topic
Optionally enable JMX polling for broker level and topic level metrics.
Optionally filter out consumers that do not have ids/ owners/ & offsets/ directories in zookeeper.
安裝過程蠻簡單的,就是要下載很多東東,會很久。具體參見: kafka manager安裝。不過這些管理平臺都沒有權(quán)限管理功能。
需要注意的是,Kafka Manager的conf/application.conf配置文件里面配置的kafka-manager.zkhosts是為了它自身的高可用,而不是指向要管理的Kafka集群指向的zkhosts。所以不要忘記了手動配置要管理的Kafka集群信息(主要是配置名稱,和zk地址)。Install and Evaluation of Yahoo’s Kafka Manager。
Kafka Manager主要是提供管理界面,監(jiān)控的話還要依賴于其他的應(yīng)用,比如:
Burrow: Kafka Consumer Lag Checking. Linkedin開源的cusumer log監(jiān)控,go語言編寫,貌似沒有界面,只有HTTP API,可以配置郵件報警。
Kafka Offset Monitor: A little app to monitor the progress of kafka consumers and their lag wrt the queue.
這兩個應(yīng)用的目的都是監(jiān)控Kafka的offset。
刪除主題
刪除Kafka主題,一般有如下兩種方式:
1、手動刪除各個節(jié)點${log.dir}目錄下該主題分區(qū)文件夾,同時登陸ZK客戶端刪除待刪除主題對應(yīng)的節(jié)點,主題元數(shù)據(jù)保存在/brokers/topics和/config/topics節(jié)點下。
2、執(zhí)行kafka-topics.sh腳本執(zhí)行刪除,若希望通過該腳本徹底刪除主題,則需要保證在啟動Kafka時加載的server.properties文件中配置 delete.topic.enable=true,該配置項默認(rèn)為false。否則執(zhí)行該腳本并未真正刪除topic,而是在ZK的/admin/delete_topics目錄下創(chuàng)建一個與該待刪除主題同名的topic,將該主題標(biāo)記為刪除狀態(tài)而已。
kafka-topic –delete –zookeeper server-1:2181,server-2:2181 –topic test`
執(zhí)行結(jié)果:
Topic test is marked for deletion. Note: This will have no impact if delete.topic.enable is not set to true.
此時若希望能夠徹底刪除topic,則需要通過手動刪除相應(yīng)文件及節(jié)點。當(dāng)該配置項為true時,則會將該主題對應(yīng)的所有文件目錄以及元數(shù)據(jù)信息刪除。
過期數(shù)據(jù)自動清除
對于傳統(tǒng)的message queue而言,一般會刪除已經(jīng)被消費的消息,而Kafka集群會保留所有的消息,無論其被消費與否。當(dāng)然,因為磁盤限制,不可能永久保留所有數(shù)據(jù)(實際上也沒必要),因此Kafka提供兩種策略去刪除舊數(shù)據(jù)。一是基于時間,二是基于partition文件大小。可以通過配置$KAFKA_HOME/config/server.properties ,讓Kafka刪除一周前的數(shù)據(jù),也可通過配置讓Kafka在partition文件超過1GB時刪除舊數(shù)據(jù):
############################# Log Retention Policy ############################# # The following configurations control the disposal of log segments. The policy can # be set to delete segments after a period of time, or after a given size has accumulated. # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens # from the end of the log. # The minimum age of a log file to be eligible for deletion log.retention.hours=168 # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining # segments don't drop below log.retention.bytes. #log.retention.bytes=1073741824 # The maximum size of a log segment file. When this size is reached a new log segment will be created. log.segment.bytes=1073741824 # The interval at which log segments are checked to see if they can be deleted according # to the retention policies log.retention.check.interval.ms=300000 # By default the log cleaner is disabled and the log retention policy will default to # just delete segments after their retention expires. # If log.cleaner.enable=true is set the cleaner will be enabled and individual logs # can then be marked for log compaction. log.cleaner.enable=false
這里要注意,因為Kafka讀取特定消息的時間復(fù)雜度為O(1),即與文件大小無關(guān),所以這里刪除文件與Kafka性能無關(guān),選擇怎樣的刪除策略只與磁盤以及具體的需求有關(guān)。
Kafka的一些問題
1、只保證單個主題單個分區(qū)內(nèi)的消息有序,但是不能保證單個主題所有分區(qū)消息有序。如果應(yīng)用嚴(yán)格要求消息有序,那么kafka可能不大合適。
2、消費偏移量由消費者跟蹤和提交,但是消費者并不會經(jīng)常把這個偏移量寫會kafka,因為broker維護這些更新的代價很大,這會導(dǎo)致異常情況下消息可能會被多次消費或者沒有消費。
具體分析如下:消息可能已經(jīng)被消費了,但是消費者還沒有像broker提交偏移量(commit offset)確認(rèn)該消息已經(jīng)被消費就掛掉了,接著另一個消費者又開始處理同一個分區(qū),那么它會從上一個已提交偏移量開始,導(dǎo)致有些消息被重復(fù)消費。但是反過來,如果消費者在批處理消息之前就先提交偏移量,但是在處理消息的時候掛掉了,那么這部分消息就相當(dāng)于『丟失』了。通常來說,處理消息和提交偏移量很難構(gòu)成一個原子性操作,因此無法總是保證所有消息都剛好只被處理一次。
3、主題和分區(qū)的數(shù)目有限
Kafka集群能夠處理的主題數(shù)目是有限的,達到1000個主題左右時,性能就開始下降。這些問題基本上都跟Kafka的基本實現(xiàn)決策有關(guān)。特別是,隨著主題數(shù)目增加,broker上的隨機IO量急劇增加,因為每個主題分區(qū)的寫操作實際上都是一個單獨的文件追加(append)操作。隨著分區(qū)數(shù)目增加,問題越來越嚴(yán)重。如果Kafka不接管IO調(diào)度,問題就很難解決。
當(dāng)然,一般的應(yīng)用都不會有這么大的主題數(shù)和分區(qū)數(shù)要求。但是如果將單個Kafka集群作為多租戶資源,這個時候這個問題就會暴露出來。
4、手動均衡分區(qū)負(fù)載
Kafka的模型非常簡單,一個主題分區(qū)全部保存在一個broker上,可能還有若干個broker作為該分區(qū)的副本(replica)。同一分區(qū)不在多臺機器之間分割存儲。隨著分區(qū)不斷增加,集群中有的機器運氣不好,會正好被分配幾個大分區(qū)。Kafka沒有自動遷移這些分區(qū)的機制,因此你不得不自己來。監(jiān)控磁盤空間,診斷引起問題的是哪個分區(qū),然后確定一個合適的地方遷移分區(qū),這些都是手動管理型任務(wù),在Kafka集群環(huán)境中不容忽視。
如果集群規(guī)模比較小,數(shù)據(jù)所需的空間較小,這種管理方式還勉強奏效。但是,如果流量迅速增加或者沒有一流的系統(tǒng)管理員,那么情況就完全無法控制。
注意:如果向集群添加新的節(jié)點,也必須手動將數(shù)據(jù)遷移到這些新的節(jié)點上,Kafka不會自動遷移分區(qū)以平衡負(fù)載量或存儲空間的。
5、follow副本(replica)只充當(dāng)冷備(解決HA問題),無法提供讀服務(wù)
不像ES,replica shard是同時提供讀服務(wù),以緩解master的讀壓力。kafka因為讀服務(wù)是有狀態(tài)的(要維護commited offset),所以follow副本并沒有參與到讀寫服務(wù)中。只是作為一個冷備,解決單點問題。
6、只能順序消費消息,不能隨機定位消息,出問題的時候不方便快速定位問題
這其實是所有以消息系統(tǒng)作為異步RPC的通用問題。假設(shè)發(fā)送方發(fā)了一條消息,但是消費者說我沒有收到,那么怎么排查呢?消息隊列缺少隨機訪問消息的機制,如根據(jù)消息的key獲取消息。這就導(dǎo)致排查這種問題不大容易。
看完上述內(nèi)容,你們掌握Kafka 原理以及實戰(zhàn)分析是什么樣的的方法了嗎?如果還想學(xué)到更多技能或想了解更多相關(guān)內(nèi)容,歡迎關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道,感謝各位的閱讀!
文章名稱:Kafka原理以及實戰(zhàn)分析是什么樣的
文章網(wǎng)址:http://www.chinadenli.net/article0/ighdoo.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供軟件開發(fā)、網(wǎng)站營銷、品牌網(wǎng)站制作、App設(shè)計、移動網(wǎng)站建設(shè)、App開發(fā)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)

- 網(wǎng)站排名公司:頂級域名和二級域名的區(qū)別? 2016-11-14
- 【成都網(wǎng)站建設(shè)】優(yōu)化網(wǎng)站排名要把握的實用技巧 2022-10-28
- 【SEO優(yōu)化】分析競爭網(wǎng)站更利于超越競爭對手的網(wǎng)站排名 2021-08-07
- 解析網(wǎng)站排名優(yōu)化不到首頁的問題 2014-11-18
- 網(wǎng)站排名與 SEO 搜索引擎優(yōu)化 2022-07-27
- 企業(yè)網(wǎng)站排名的提高還是要靠內(nèi)容和外鏈 2021-09-03
- 【網(wǎng)站排名公司】優(yōu)質(zhì)的網(wǎng)站優(yōu)化要做到什么程 2016-11-12
- 利用原創(chuàng)文章來提升網(wǎng)站排名和知名度 2015-11-13
- 網(wǎng)站排名跟蹤依然重要嗎? 2015-12-23
- 網(wǎng)站建設(shè)中那些行為會影響網(wǎng)站排名優(yōu)化? 2023-02-02
- 成都優(yōu)化網(wǎng)站排名 2022-08-03
- 怎么優(yōu)化網(wǎng)站排名才能更好? 2014-10-28